29-keepalived高可用性负载均衡
以下将为你详细介绍高可用性负载均衡的原理,并使用 Mermaid 绘制对应的流程图和架构图来直观呈现。
高可用性负载均衡原理概述
高可用性负载均衡是为了确保系统在面对各种故障和高流量时仍能稳定运行。其核心原理是通过多个负载均衡器和多个后端服务器组成集群,负载均衡器负责将客户端的请求均匀地分配到后端服务器上,同时具备故障检测和自动切换功能,当某个负载均衡器或后端服务器出现故障时,系统能够自动调整请求的分配,保证服务的连续性。
架构图代码解释
- 客户端:发起请求的终端用户。
- 负载均衡器集群:由多个负载均衡器组成,用于接收客户端的请求并进行分配。
- 负载均衡算法:包括轮询、加权轮询、IP 哈希、最少连接等,根据不同的策略将请求分配到后端服务器。
- 后端服务器:处理客户端请求的服务器,多个后端服务器组成集群以提高系统的处理能力和容错性。
- 数据存储:存储系统处理的数据,供后端服务器访问。
- 监控系统:实时监控负载均衡器和后端服务器的状态,如 CPU 使用率、响应时间等。
- 故障转移机制:当监控到某个负载均衡器或后端服务器出现故障时,自动将请求转移到其他正常的设备上。
工作流程图 Mermaid 代码
graph LR
classDef startend fill:#F5EBFF,stroke:#BE8FED,stroke-width:2px;
classDef process fill:#E5F6FF,stroke:#73A6FF,stroke-width:2px;
classDef decision fill:#FFF6CC,stroke:#FFBC52,stroke-width:2px;
A([开始]):::startend --> B(客户端发起请求):::process
B --> C(负载均衡器接收请求):::process
C --> D{负载均衡器是否正常}:::decision
D -->|是| E{选择负载均衡算法}:::decision
D -->|否| F(故障转移到备用负载均衡器):::process
F --> E
E -->|轮询| G(选择下一个后端服务器):::process
E -->|加权轮询| H(根据权重选择后端服务器):::process
E -->|IP 哈希| I(根据 IP 地址选择后端服务器):::process
E -->|最少连接| J(选择连接数最少的后端服务器):::process
G --> K{后端服务器是否正常}:::decision
H --> K
I --> K
J --> K
K -->|是| L(后端服务器处理请求):::process
K -->|否| M(故障转移到其他后端服务器):::process
M --> L
L --> N(后端服务器返回响应):::process
N --> O(负载均衡器转发响应给客户端):::process
O --> P([结束]):::startend
工作流程图代码解释
- 开始:流程的起始点。
- 客户端发起请求:客户端向负载均衡器发送请求。
- 负载均衡器接收请求:负载均衡器接收到客户端的请求。
- 负载均衡器是否正常:检查负载均衡器是否处于正常工作状态。
- 故障转移到备用负载均衡器:如果当前负载均衡器出现故障,将请求转移到备用负载均衡器。
- 选择负载均衡算法:根据预设的算法选择合适的后端服务器。
- 后端服务器是否正常:检查所选的后端服务器是否正常工作。
- 故障转移到其他后端服务器:如果所选后端服务器出现故障,将请求转移到其他正常的后端服务器。
- 后端服务器处理请求:后端服务器对请求进行处理。
- 后端服务器返回响应:处理完成后,后端服务器将响应返回给负载均衡器。
- 负载均衡器转发响应给客户端:负载均衡器将响应转发给客户端。
- 结束:流程结束。
通过这两个 Mermaid 图,你可以清晰地了解高可用性负载均衡的架构和工作流程。
软件官网
http://www.keepalived.org/
![]()
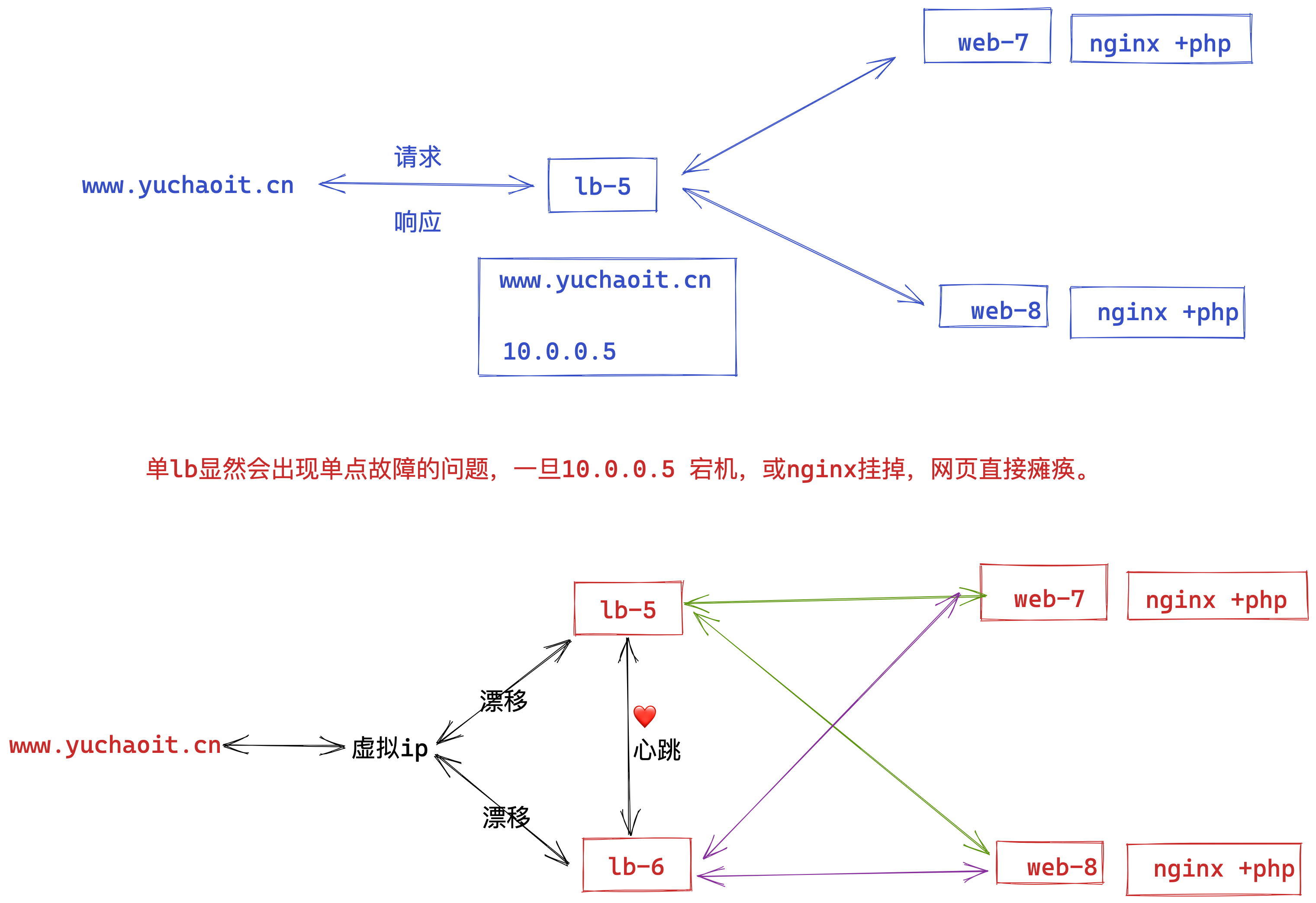
为什么需要keepalived
架构图详细解释
用户访问层:
- 客户端:发起 HTTP 请求的设备或应用程序,如浏览器。它通过访问虚拟 IP 地址(VIP)来请求 Web 服务。
- 虚拟 IP(VIP):是一个逻辑上的 IP 地址,由 Keepalived 管理的主节点和备节点共享。客户端将请求发送到这个 VIP,而不需要关心具体是哪台物理服务器在处理请求。
Keepalived 层:
- Keepalived 主节点(Master):正常情况下,主节点拥有 VIP 的控制权,接收来自客户端的请求,并将请求转发到后端的 Web 服务器。它还会定期向备节点发送心跳检测信号,以表明自己处于正常工作状态。
- Keepalived 备节点(Backup):处于备用状态,监听主节点发送的心跳检测信号。如果在一定时间内没有收到主节点的心跳信号,备节点会认为主节点出现故障,从而接管 VIP,成为新的主节点。
Web 服务器层:
- Web 服务器 1 和 Web 服务器 2:运行 Web 应用程序,处理客户端的请求并生成相应的响应。这两台服务器都可以接收来自 Keepalived 节点的请求,并进行处理。
数据存储层:
- 数据库服务器:存储 Web 应用程序所需的数据,如用户信息、业务数据等。Web 服务器在处理请求时,会与数据库服务器进行交互,读取或写入数据。
健康检查层:
- 健康检查脚本:定期对 Web 服务器进行健康检查,例如检查 Web 服务器的进程是否正常运行、端口是否开放等。健康检查脚本会将检查结果反馈给 Keepalived 的主节点和备节点。如果发现某台 Web 服务器出现故障,Keepalived 可以根据情况调整请求的分发策略,避免将请求发送到故障服务器上。
通过以上架构,Keepalived 实现了 Web 集群的高可用性,确保在某台服务器或某个组件出现故障时,系统仍然能够继续为客户端提供服务。
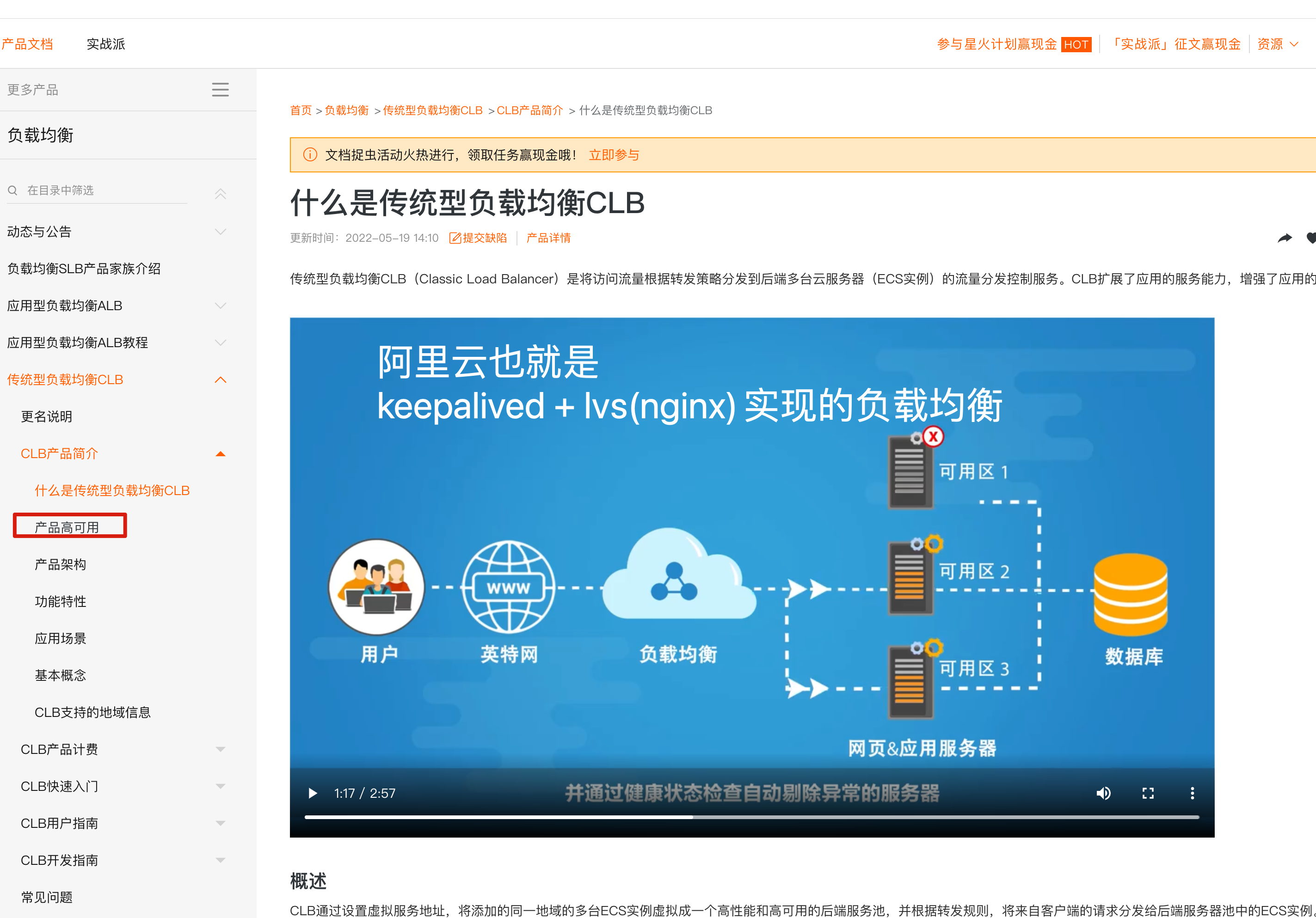
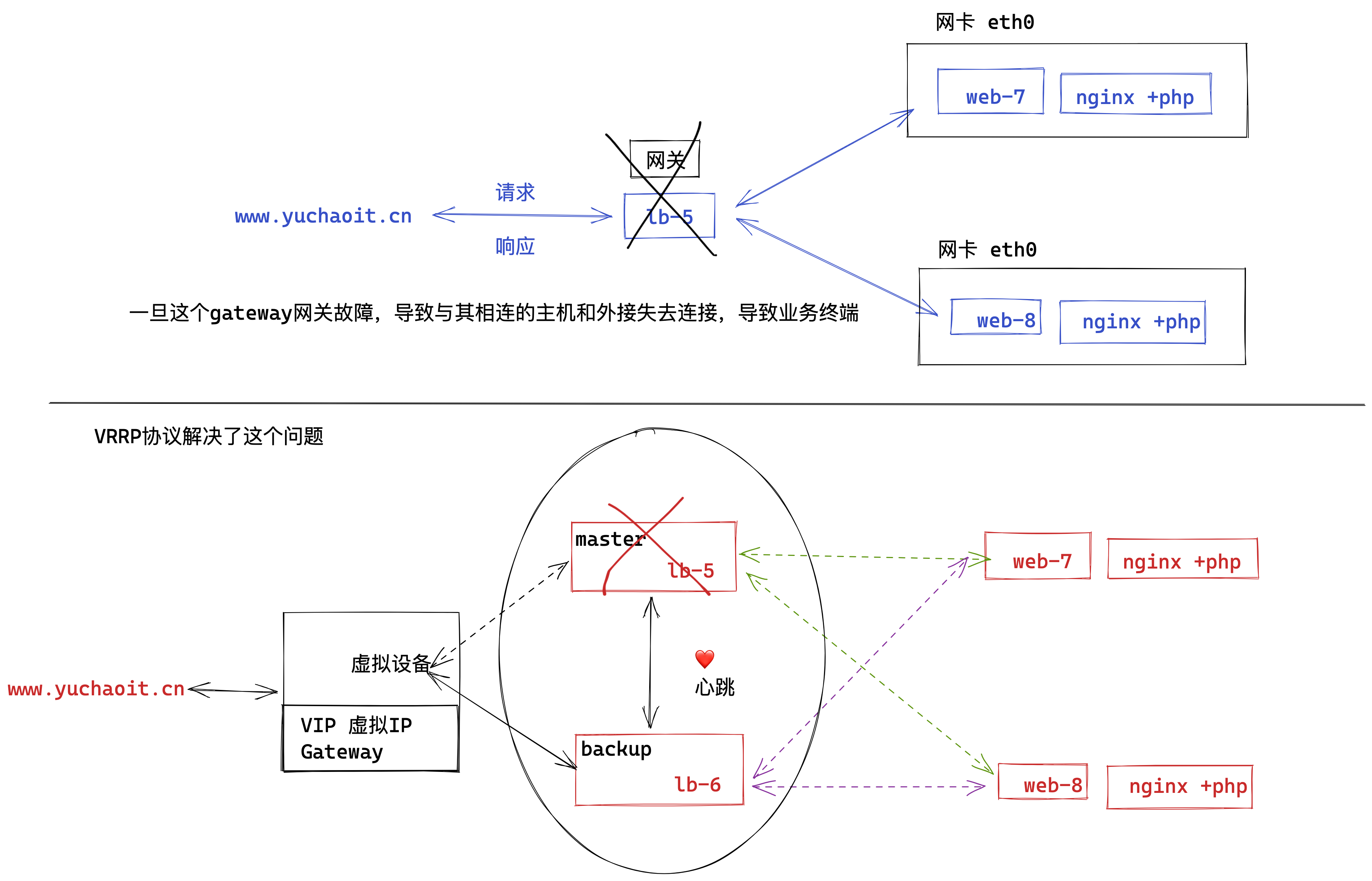
上图明显看出,LB机器应该是双节点,否则出现单点故障的问题,并且LB作为网站的入口,显然要提供高可用性的访问。
keepalived就是解决了单点故障的问题,给两台不同IP的服务器提供了自动漂移虚拟IP的功能。
lb-5机器如果宕机,这个虚拟IP自动切换到lb-6机器上,这个过程对用户是透明的,不会感知到网站有任意问题。
keepalived工作原理
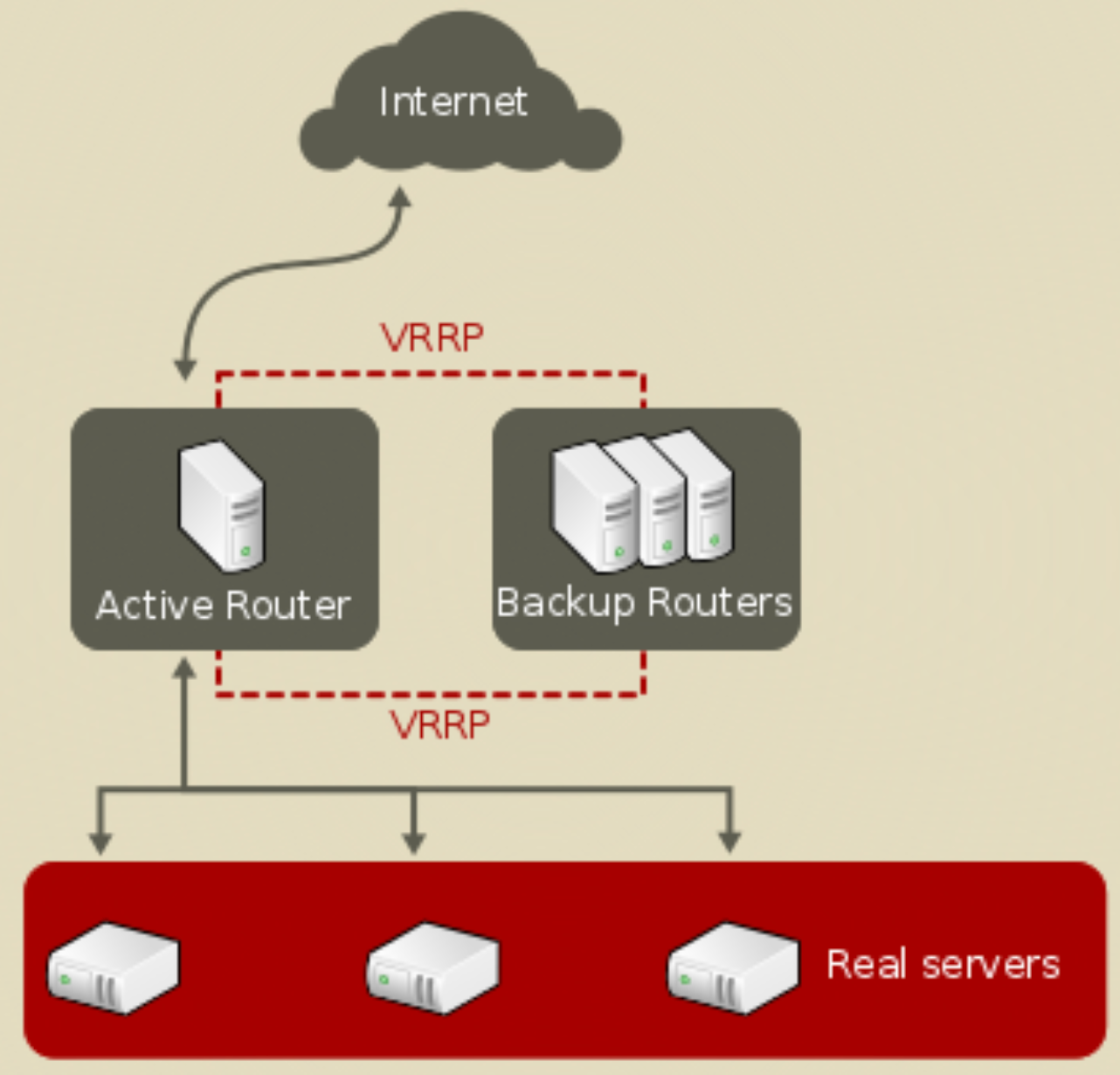
VRRP协议
Keepalived 和 VRRP 协议通常一起用于实现服务器的高可用性(HA)。用通俗的方式解释:
1. VRRP 协议:像“值班小组” • VRRP(虚拟路由冗余协议) 的核心是让多个服务器(比如路由器或负载均衡器)组成一个“小组”,共同对外提供一个虚拟IP地址(VIP)。这个VIP是用户实际访问的入口。
• 工作原理:
• 主节点(Master):小组中有一个“值班”的服务器(主节点),负责处理所有用户请求。
• 备份节点(Backup):其他服务器作为备份,默默待命。
• 心跳检测:主节点会定时发送“心跳”(组播消息)告诉备份节点:“我还活着!”
• 故障切换:如果备份节点收不到心跳,就会认为主节点挂了,并自动接管VIP,继续服务。
比喻:就像公司里的“值班表”,每天有人轮班。如果值班的人突然请假,其他人会立刻顶上,保证公司电话永远有人接听。
2. Keepalived:VRRP 的“实现工具” • Keepalived 是一个软件,基于 VRRP 协议实现了高可用性,同时还能做健康检查。
• 核心功能:
• 管理VIP:通过 VRRP 协议选举主备节点,并绑定/释放虚拟IP。
• 健康检查:不仅检测服务器是否存活,还能检测具体服务(比如 Nginx、MySQL)是否正常。如果服务挂了,即使服务器活着,也会触发切换。
• 配置简单:通过配置文件定义主备节点、优先级、检测脚本等。
比喻:Keepalived 就像值班小组的“智能管理员”,不仅安排谁值班,还会检查值班的人是否真的在干活(比如接电话),如果发现偷懒,立刻换人。
3. 实际应用场景 假设有两台 Nginx 服务器(Server A 和 Server B),用 Keepalived + VRRP 实现高可用:
正常情况: • Server A 是主节点,绑定虚拟IP(例如
192.168.1.100),处理用户请求。• Server B 作为备份,监听心跳。
故障时: • 如果 Server A 宕机,Server B 检测不到心跳,会接管虚拟IP,继续服务。
• 用户访问的IP不变(
192.168.1.100),完全无感知。恢复时: • 当 Server A 恢复,可以重新夺回主节点角色(根据优先级配置)。
总结 • VRRP:负责“主备选举和切换”的通信协议。
• Keepalived:利用 VRRP 实现高可用,并增加了健康检查等高级功能。
• 关键价值:避免单点故障,让服务永不间断。
一句话:Keepalived + VRRP 就是让多个服务器像“备胎”一样随时待命,确保服务永远在线。
部署nginx+keepalived
1. 架构设计
+---------------------+
| 虚拟IP (VIP) |
| 10.211.55.11/24 |
+----------+----------+
|
+-------------+-------------+
| |
+------+------+ +------+------+
| Nginx主节点 | | Nginx备节点 |
| 10.211.55.16| |10.211.55.17|
+-------------+ +------------+
| |
+------+------+ +------+------+
| 后端服务器组 | | 后端服务器组 |
| (Web/App) | | (Web/App) |
+------------+ +------------+
2. 环境准备
2.1 节点信息
| 节点角色 | IP地址 | 主机名 |
|---|---|---|
| 主节点 | 10.211.55.16 | nginx-master |
| 备节点 | 10.211.55.17 | nginx-backup |
| 虚拟IP(VIP) | 10.211.55.11 | - |
2.2 前置条件
- 所有节点安装Nginx并配置相同负载均衡规则(指向统一后端服务器)。
- 确保主备节点间网络互通(允许VRRP协议通信,协议号112)。防火墙关闭。
3. Keepalived安装与配置
3.1 安装Keepalived
# CentOS/RHEL
sudo yum install keepalived -y
# Ubuntu/Debian
sudo apt-get install keepalived -y
# 可能出现的错误
The following packages have unmet dependencies:
libreoffice-common : Breaks: libreoffice-core (< 4:24.2~) but 1:7.3.4-0ubuntu0.22.04.1 is to be installed
Recommends: fonts-liberation (>= 1:2) but 1:1.07.4-11 is to be installed or
ttf-mscorefonts-installer but it is not going to be installed
Recommends: python3-uno but it is not going to be installed
E: Error, pkgProblemResolver::Resolve generated breaks, this may be caused by held packages.
root@nginx01:~#
# 解决办法
# 尽量不要随意删除,更新系统驱动
同步2遍机器,都为阿里云apt源,apt update
sudo apt update
sudo apt --fix-broken install
#sudo apt remove --purge libreoffice* # 公司apt批量删除一些软件,建议和老大先反馈
#sudo apt install keepalived -y
3.2 主节点配置 (/etc/keepalived/keepalived.conf)
利用单播模式的配置文件,以防止脑裂的问题。
要确保主、备节点上的
unicast_src_ip,,,本机IP
unicast_peer,,,对方IP
vrrp_script chk_service {
script "/etc/keepalived/check_service.sh"
interval 2 # 检查间隔(秒)
weight -20 # 检查失败时优先级降低20
}
vrrp_instance VI_1 {
state MASTER
interface enp0s5 # 替换为你的网卡名(ifconfig查看)
virtual_router_id 51 # 集群ID,同一集群内必须唯一(1-255)
priority 100 # 初始优先级,主节点高于备节点
authentication {
auth_type PASS
auth_pass 123123 # 自定义密码,主备需一致
}
unicast_src_ip 10.211.55.16 # 主节点IP(单播模式)
unicast_peer {
10.211.55.17 # 备节点IP(单播模式)
}
virtual_ipaddress {
10.211.55.100 # 虚拟IP(VIP)
}
track_script {
chk_service # 引用健康检查脚本
}
}
3.3 备节点配置
复制主节点配置文件,修改以下参数: ```conf vrrp_script chk_service {
script "/etc/keepalived/check_service.sh" interval 2 # 检查间隔(秒) weight -20 # 检查失败时优先级降低20}
vrrp_instance VI_1 {
state BACKUP interface enp0s5 # 替换为你的网卡名(ifconfig查看) virtual_router_id 51 # 集群ID,同一集群内必须唯一(1-255) priority 50 # 初始优先级,主节点高于备节点 authentication { auth_type PASS auth_pass 123123 # 自定义密码,主备需一致 } unicast_src_ip 10.211.55.17 # 主节点IP(单播模式) unicast_peer { 10.211.55.16 # 备节点IP(单播模式) } virtual_ipaddress { 10.211.55.100 # 虚拟IP(VIP) } track_script { chk_service # 引用健康检查脚本 }
}
---
### 添加健康检查脚本
```bash
#!/bin/bash
# 示例:检查Nginx是否运行
if systemctl is-active --quiet nginx; then
exit 0
else
exit 1
fi
chmod +x /etc/keepalived/check_service.sh
抓数据包
sudo tcpdump -nn -i enp0s5 vrrp
4. 服务启动与验证
4.1 启动Keepalived
sudo systemctl enable keepalived
sudo systemctl restart keepalived
systemctl status keepalived
# 看日志
journalctl -u keepalived.service -f
4.2 检查VIP绑定
# 在主节点执行
ip addr show eth0 | grep 192.168.1.100
# 应输出:inet 192.168.1.100/24 scope global secondary eth0
# 在备节点执行相同命令,应无此IP
4.3 查看集群状态
sudo journalctl -u keepalived -f
# 正常日志示例:
# VRRP_Instance(VI_1) Transition to MASTER STATE
# VRRP_Instance(VI_1) Entering MASTER STATE
5. 故障切换测试
5.1 模拟主节点故障
# 在主节点停止Nginx服务
sudo systemctl stop nginx
# Keepalived检测到Nginx停止后,自动释放VIP
# 或在主节点直接关闭Keepalived
sudo systemctl stop keepalived
5.2 验证备节点接管VIP
# 在备节点检查IP
ip addr show eth0 | grep 192.168.1.100
# 应显示VIP已绑定到备节点
# 客户端访问VIP测试
curl http://192.168.1.100
6. 高级配置
6.1 邮件告警(主节点配置)
global_defs {
notification_email {
admin@example.com # 接收告警的邮箱
}
notification_email_from keepalived@example.com
smtp_server smtp.example.com
smtp_connect_timeout 30
}
vrrp_instance VI_1 {
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
创建通知脚本 /etc/keepalived/notify.sh:
#!/bin/bash
case $1 in
master) echo "VIP切换至主节点" | mail -s "Keepalived状态变更" admin@example.com ;;
backup) echo "VIP切换至备节点" | mail -s "Keepalived状态变更" admin@example.com ;;
fault) echo "节点进入故障状态" | mail -s "Keepalived状态变更" admin@example.com ;;
esac
6.2 多VIP支持
virtual_ipaddress {
192.168.1.100/24
192.168.1.101/24 # 添加第二个VIP
}
7. 防火墙配置(重要!)
允许VRRP协议和Nginx端口:
# CentOS/RHEL (firewalld)
sudo firewall-cmd --permanent --add-rich-rule='rule protocol value="vrrp" accept'
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
# Ubuntu/Debian (ufw)
sudo ufw allow 80/tcp
sudo ufw allow 443/tcp
sudo ufw allow proto vrrp
sudo ufw reload
8. 常见问题
8.1 VIP无法切换
- 检查项:
- 主备节点
virtual_router_id是否一致。 - 防火墙是否允许VRRP协议(IP协议号112)。
- 网络是否互通(使用
ping或tcpdump抓包排查)。
- 主备节点
8.2 脑裂问题(双主节点)
- 解决方法:
- 检查网络延迟和丢包情况。
- 调整
advert_int值(如改为2秒)。 - 使用第三方仲裁脚本(如通过HTTP检测共享状态)。
通过以上方案,您已实现Nginx+Keepalived的高可用集群,确保在单节点故障时服务无感知切换,适用于生产环境关键业务系统。
VRRP配置前提条件
1. 虚拟IP不得重复
2. 虚拟IP得和相同网段的网卡绑定
面试拿出来背即可
1. keppalived高可用是基于VRRP虚拟路由冗余协议实现的,因此我从VRRP给您描述起
2. VRRP也就是虚拟路由冗余协议,是为了解决静态路由的单点故障;
3. VRRP通过竞选协议将路由任务交给某一台VRRP路由器。
4. VRRP正常工作时,master会自动发送数据包,backup接收数据包,目的是为了判断对方是否存活;如果backup收不到master的数据包了,自动接管master的资源;
backup节点可以有多个,通过优先级竞选,但是keepalived服务器一般都是成对出现;
5. VRRP默认对数据包进行了加密,但是官网默认还是推荐使用明文来配置认证;
说完了VRRP,我再给您描述下keepalived工作原理。
1.keepalived就是基于VRRP协议实现的高可用,master的优先级必须高于backup,因此启动时master优先获得机器的IP资源,backup处于等待状态;若master挂掉后,backup顶替上来,继续提供服务。
2.在keepalived工作时,master角色的机器会一直发送VRRP广播数据包,告诉其他backup机器,“我还活着”,此时backup不会抢夺资源,老实呆着。
当master出现问题挂了,导致backup收不到master发来的广播数据包,因此开始接替VIP,保证业务的不中断运行,整个过程小于1秒。
1.环境准备
lb-5 10.0.0.5 keepalived-master机器 nginx-lb-5
lb-6 10.0.0.6 keepalived-backup机器 nginx-lb-6
web-7 10.0.0.7 web服务器
web-8 10.0.0.8 web服务器
2.安装keepalived(两台机器)
yum install keepalived -y
3.创建keepalived配置文件(lb-5)
global_defs {
router_id lb-5 # 路由器ID,每个机器不一样
}
vrrp_instance VIP_1 { # 设置VRRP路由器组组名,属于同一组的名字一样
state MASTER # 角色,master、backup两种
interface eth0 # VIP绑定的网卡
virtual_router_id 50 # 虚拟路由IP,同一组的一样
priority 150 # 优先级,优先级越高,权重越高
advert_int 1 # 发送组播间隔1s
authentication { # 认证形式
auth_type PASS # 密码认证,明文密码 1111
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3 # 指定虚拟VIP地址,必须没人使用
}
}
使用如下配置
[root@lb-5 ~]#cat /etc/keepalived/keepalived.conf
global_defs {
router_id lb-5
}
vrrp_instance VIP_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
[root@lb-5 ~]#
4.backup配置文件(lb-6)
[root@lb-6 ~]#cat /etc/keepalived/keepalived.conf
global_defs {
router_id lb-6
}
vrrp_instance VIP_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
5.启动keepalived(两台lb)
1.先检查当前的网卡情况
[root@lb-5 ~]#ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:eb:fe:a9 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.5/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:feeb:fea9/64 scope link
valid_lft forever preferred_lft forever
[root@lb-5 ~]#
[root@lb-6 ~]#ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:55:9f:53 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.6/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe55:9f53/64 scope link
valid_lft forever preferred_lft forever
[root@lb-6 ~]#
启动服务
systemctl start keepalived
再次检查VIP情况
[root@lb-5 ~]#ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:eb:fe:a9 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.5/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 10.0.0.3/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:feeb:fea9/64 scope link
valid_lft forever preferred_lft forever
[root@lb-5 ~]#
[root@lb-6 ~]#ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:55:9f:53 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.6/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe55:9f53/64 scope link
valid_lft forever preferred_lft forever
[root@lb-6 ~]#
6.结合nginx测试(两台lb)
6.1 lb-5
[root@lb-5 /etc/nginx/conf.d]#cat lb.conf
upstream web_pools {
server 10.0.0.7;
server 10.0.0.8;
}
server {
listen 80;
server_name _;
location / {
proxy_pass http://web_pools;
include proxy_params;
}
}
[root@lb-5 /etc/nginx/conf.d]#cat /etc/nginx/proxy_params
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_connect_timeout 30;
proxy_send_timeout 60;
proxy_read_timeout 60;
proxy_buffering on;
proxy_buffer_size 32k;
proxy_buffers 4 128k;
[root@lb-5 /etc/nginx/conf.d]#nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@lb-5 /etc/nginx/conf.d]#systemctl restart nginx
6.2 lb-6
[root@lb-6 /etc/nginx/conf.d]#systemctl restart nginx
[root@lb-6 /etc/nginx/conf.d]#
[root@lb-6 /etc/nginx/conf.d]#
[root@lb-6 /etc/nginx/conf.d]#ls
lb.conf
[root@lb-6 /etc/nginx/conf.d]#cat lb.conf
upstream web_pools {
server 10.0.0.7;
server 10.0.0.8;
}
server {
listen 80;
server_name _;
location / {
proxy_pass http://web_pools;
include proxy_params;
}
}
[root@lb-6 /etc/nginx/conf.d]#
[root@lb-6 /etc/nginx/conf.d]#cat /etc/nginx/proxy_params
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_connect_timeout 30;
proxy_send_timeout 60;
proxy_read_timeout 60;
proxy_buffering on;
proxy_buffer_size 32k;
proxy_buffers 4 128k;
6.3 web-7、web-8
# cat web.conf
server {
listen 80;
server_name _;
charset utf-8;
location / {
root /code;
index index.html;
}
}
# 创建测试数据
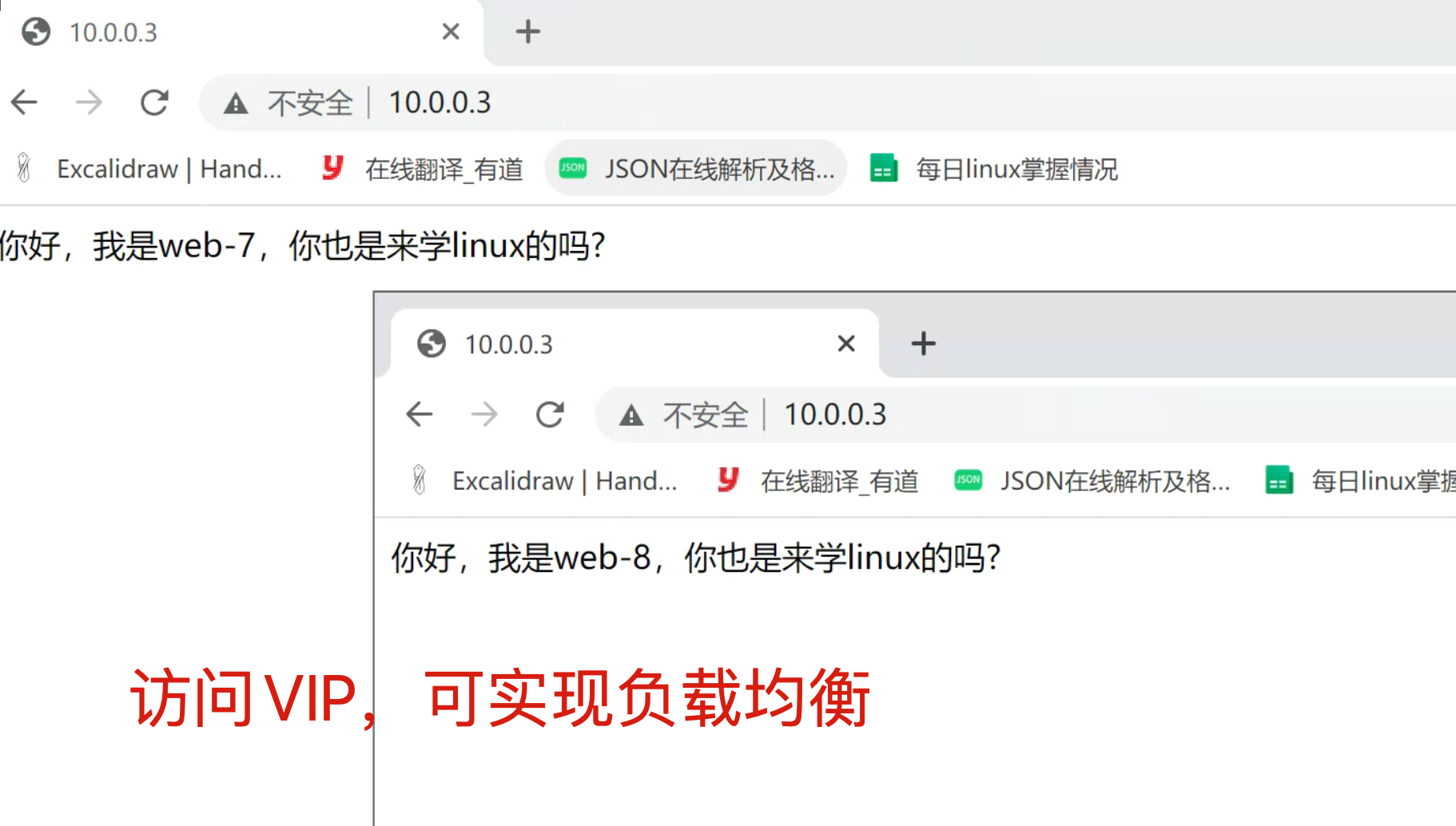
echo '你好,我是web-7,你也是来学linux的吗?' > /code/index.html
echo '你好,我是web-8,你也是来学linux的吗?' > /code/index.html
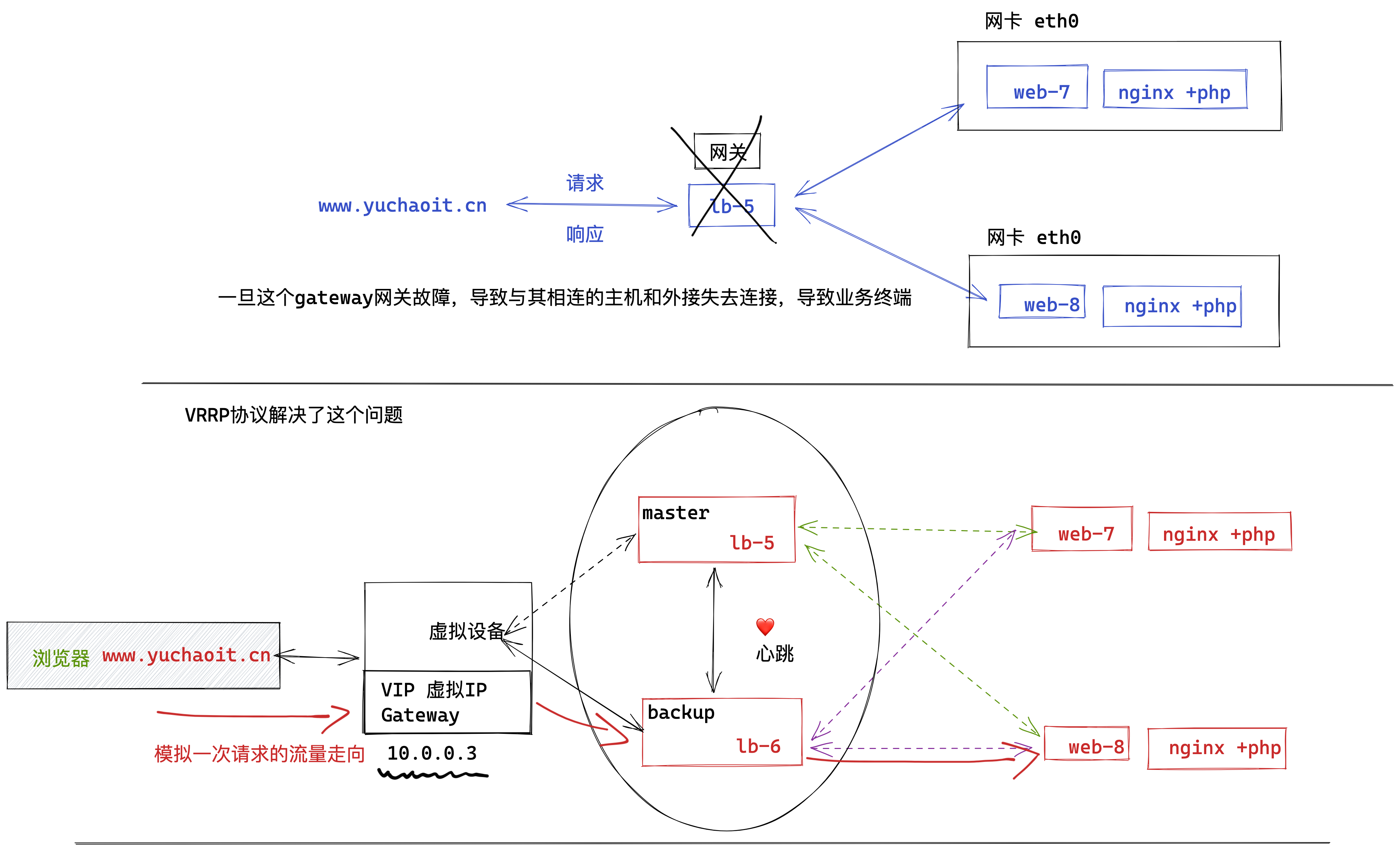
7.客户端访问(访问VIP)
8.模拟master故障,查看VIP
当前VIP在lb-5机器上
[root@lb-5 ~]#ip a show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:eb:fe:a9 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.5/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 10.0.0.3/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:feeb:fea9/64 scope link
valid_lft forever preferred_lft forever
lb-6的IP情况
[root@lb-6 ~]#ip a show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:55:9f:53 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.6/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe55:9f53/64 scope link
valid_lft forever preferred_lft forever
关闭master的keepalived服务
[root@lb-5 ~]#systemctl stop keepalived
查看此时服务会中断吗?继续访问10.0.0.3
查看lb-6机器是否实现了VIP漂移。
[root@lb-6 ~]#ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:55:9f:53 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.6/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 10.0.0.3/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe55:9f53/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:55:9f:5d brd ff:ff:ff:ff:ff:ff
inet 172.16.1.6/24 brd 172.16.1.255 scope global noprefixroute eth1
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe55:9f5d/64 scope link
valid_lft forever preferred_lft forever
9.恢复lb-5的keepalived服务
[root@lb-5 ~]#systemctl start keepalived
查看此时VIP又漂移到了那里。
backup机器的VIP是否消失。
Keepalived脑裂问题
简单说就是如果master还在正常工作,但是backup没有正确接收到master的心跳数据包,就会以为master挂掉了,抢夺VIP资源。
这个世道就会导致两个服务器都有了VIP,导致冲突故障,这就是脑裂问题。
1.导致脑裂的原因
要实现心跳检测,需要让至少两台服务器实现互相通信,数据包收发,主要通过如下方式实现
- (生产环境下做法)直接网线让两台服务器直连
- 也可以通过局域网通信,确保两台机器可以连接。
高可用软件基于这个心跳线来判断对端机器是否存活,决定是否要实现故障迁移,VIP迁移,保证业务的连续性。
一般来说,导致脑裂的原因有这些,也是排错思路
- 心跳线老化,线路破损,导致无法通信
- 网卡驱动损坏,master、backup IP地址冲突。
- 防火墙配置错误,导致心跳消息收不到
- 配置文写错了,两台机器的虚拟路由ID不一致。
2.解决脑裂
- 使用双心跳线路,防止单线路损坏,只要确保master的心跳数据包能发给backup。
- 通过脚本程序检测脑裂情况
- 判断是否两边都有VIP,如果心跳重复,强制关闭一个心跳节点(直接发送关机命令,强制断掉主节点的电源)
- 做好脑裂监控,如果发现脑裂,人为第一时间干预处理。
- 如果开启了防火墙,注意要允许心跳IP的访问。
keepalived组播原理
单播流量走向图
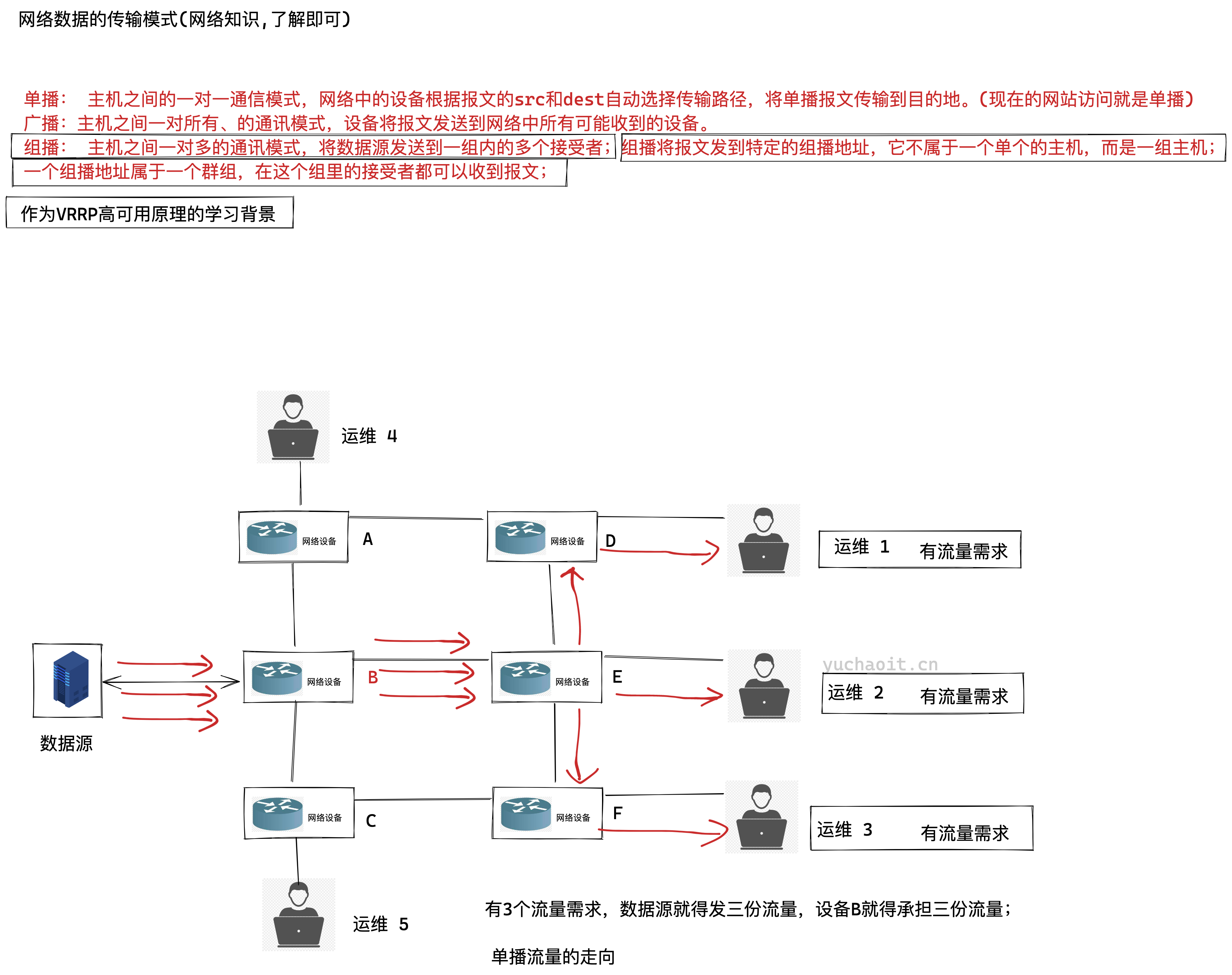
广播数据流
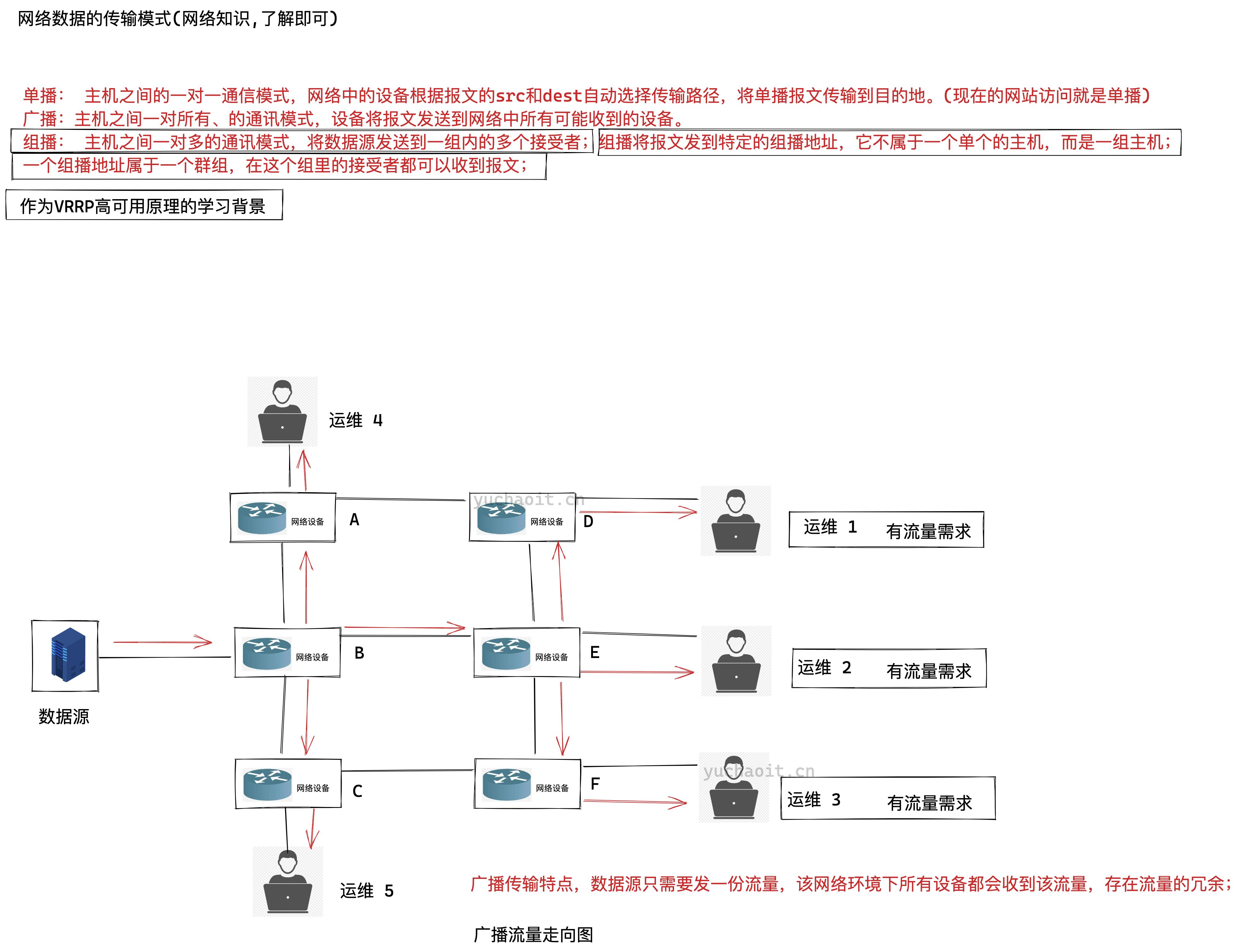
组播数据流
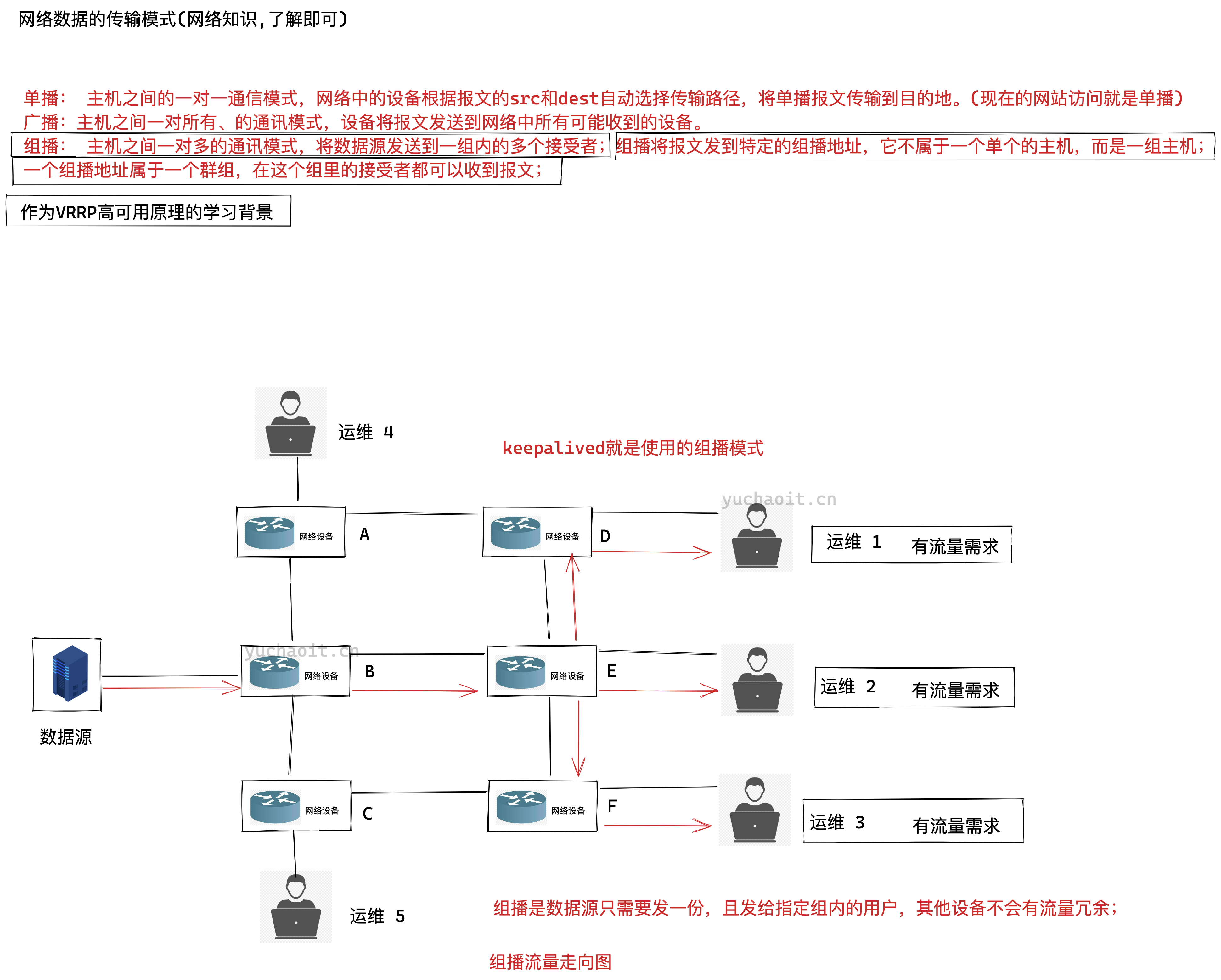
keepalived组播地址
组播: 主机之间一对多的通讯模式,将数据源发送到一组内的多个接受者;组播将报文发到特定的组播地址,它不属于一个单个的主机,而是一组主机;
一个组播地址属于一个群组,在这个组里的接受者都可以收到报文;
keepalived默认使用VRRP虚拟路由器冗余协议,在默认组播224.0.0.18这个IP地址以实现在master和backup机器之间进行通信,实现健康检查。
抓包查看VRRP

停止master试试
[root@lb-5 ~]#systemctl stop keepalived
心跳切换原理
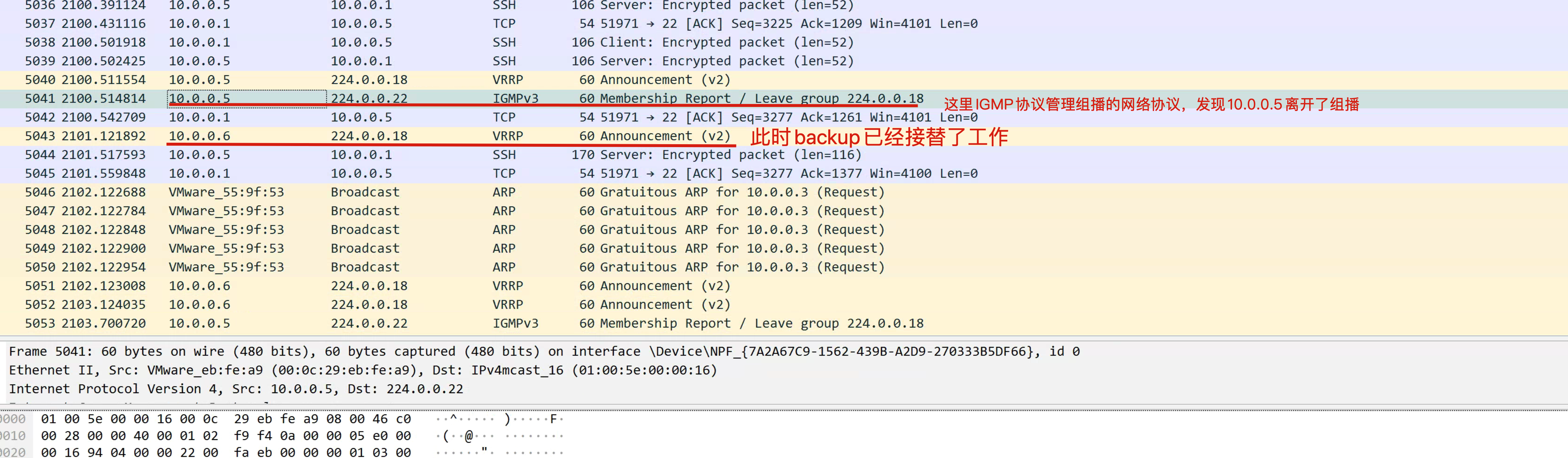
backup切换原理
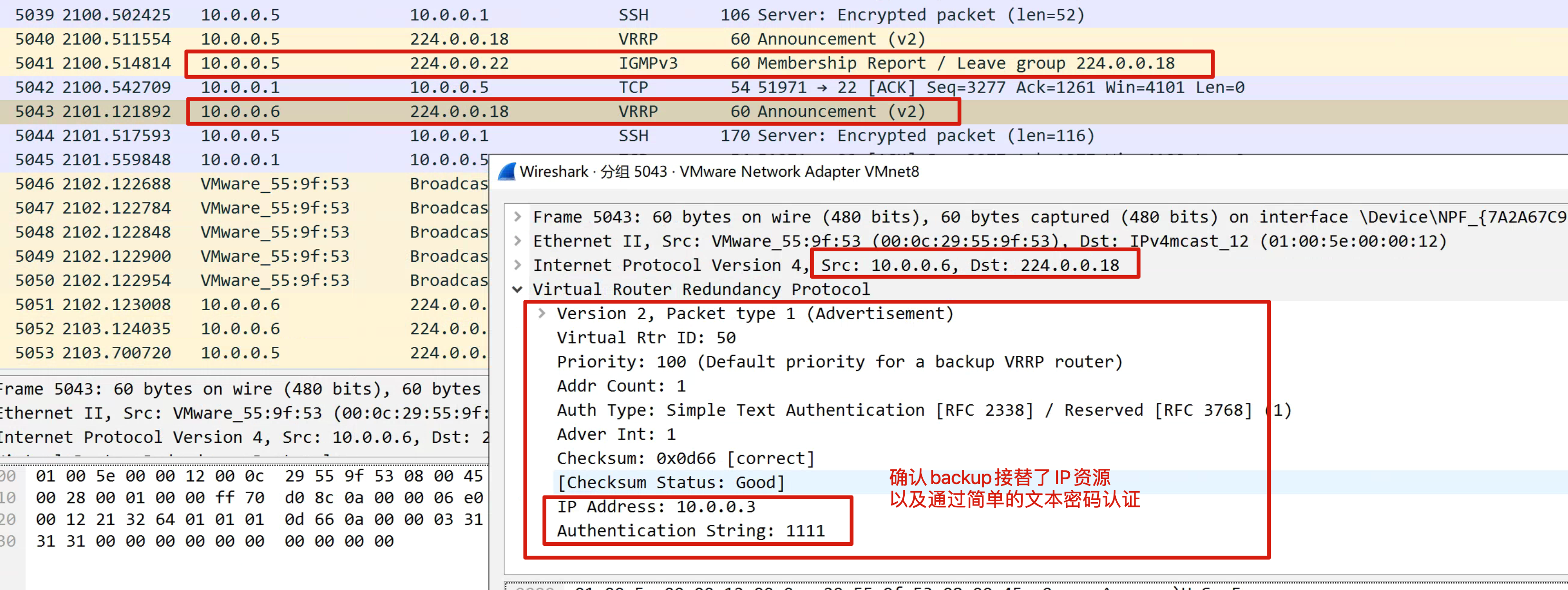
抓包工具查看脑裂
这里在linux下进行抓包。
lb-5安装tcpdump
[root@lb-5 ~]#yum install tcpdump -y
lb-5抓包
# 参数
# -nn: 指定将每个监听到的数据包中的域名转换成IP、端口从应用名称转换成端口号后显示
# -i 指定监听的网络接口;
# any 抓取所有网络接口
# host 指定抓取的主机地址,这里是组播地址。
tcpdump -nn -i any host 224.0.0.18
lb-6开启防火墙
开启防火墙后,导致lb-5没法和lb-6正常通信,backup以为master挂了,抢夺VIP资源。
此时高可用集群就已故障,无法正常漂移切换VIP了。
1.停止master keepalived
2. 发现backup也无法正常工作
停止lb-6的防火墙
可正确恢复 keepalived;
因为你只要确保master能通过给组播发消息,确保backup能收到。
两边的高可用心跳就没问题。
解决脑裂的方案
防火墙规则放行
# 只要启动服务就会抢夺VIP
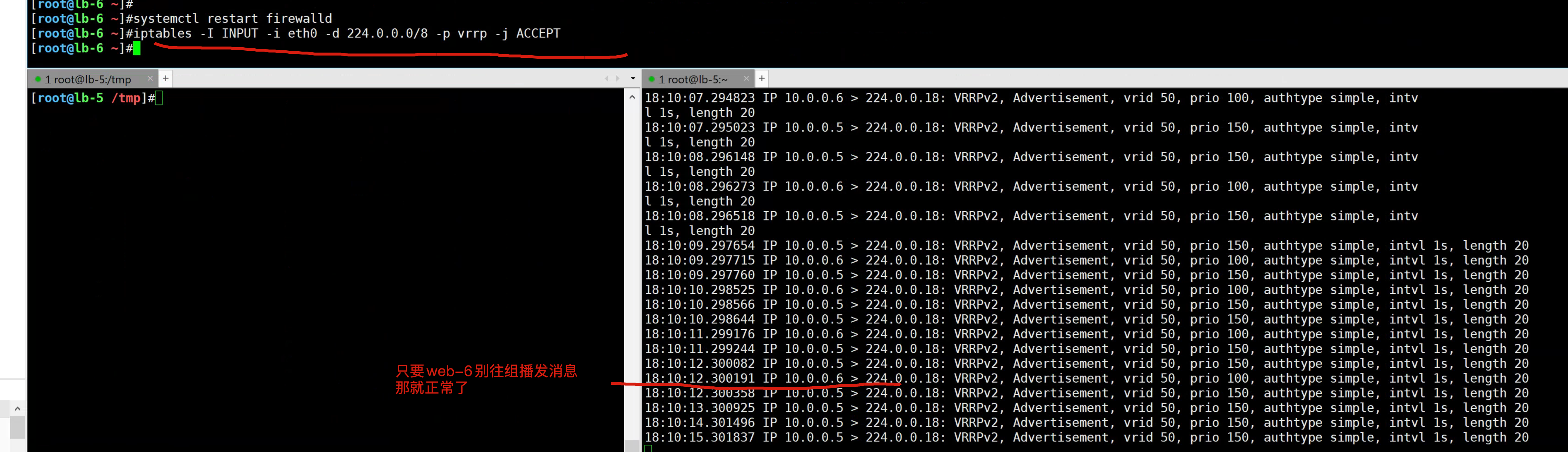
systemctl restart firewalld
# VIP应该会消失,VRRP正常
iptables -I INPUT -i eth0 -d 224.0.0.0/8 -p vrrp -j ACCEPT
防止脑裂的脚本开发
更靠谱的做法是,自己编写shell脚本,核心思路是
确保backup机器定时去判断master的VIP状态,如果发生脑裂,backup自杀即可(kill keepalived)
防止脑裂脚本思路
先有思路,再写脚本
针对backup服务器
1. backup定期检查master的nginx是否运行
2. backup定期检查自己是否有VIP
3. 如果有如下情况,backup却也有VIP,就是脑裂
- master的nginx正常
- master有VIP
- backup有VIP
4. 如果backup有脑裂,就干掉自己的keepalived
5. 告知管理员。
1.backup脚本开发
cat > /etc/keepalived/check_vip.sh << 'EOF'
#!/bin/bash
MASTER_VIP=$(ssh 10.0.0.5 ip a|grep 10.0.0.3|wc -l)
MY_VIP=$(ip a|grep 10.0.0.3|wc -l)
# 如果远程有VIP并且自己本地也存在了VIP,就干掉自己
if [ ${MASTER_VIP} == 1 -a ${MY_VIP} == 1 ]
then
systemctl stop keepalived
fi
EOF
2. backup服务调用自杀脚本
这里是利用了keepalived自身提供的vrrp_script脚本功能,实现监控,自动干掉自己。。
前提条件是
- 脚本添加执行权限
- lb-6和lb-5免密登录
cat > /etc/keepalived/keepalived.conf << 'EOF'
global_defs {
router_id lb-6
}
# 定义脚本
vrrp_script check_vip {
script "/etc/keepalived/check_vip.sh"
interval 5 # 脚本执行的时间间隔
}
vrrp_instance VIP_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
# 调动脚本
track_script {
check_vip
}
}
EOF
3.测试backup的监控脚本
1. 确保master、backup正常
systemctl restart keepalived
2. 主动导致脑裂,查看情况
[root@lb-6 /etc/keepalived]#systemctl restart firewalld

情况2:master出现问题
问题背景
刚才的脚本解决了backup抢夺VIP的问题;
但是如果master出了问题呢?比如master的nginx挂了,那keepalived没啥用了,服务还是挂了。
监控master故障的脚本。
思路
master机器脚本
1. 如果自己的nginx已经不存在了,keepalived还活着,尝试重启nginx
2. 如果重启nginx失败,干掉自己的keepalived,放弃master资源,让backup继续干活
脚本如下
cat > /etc/keepalived/check_web.sh << 'EOF'
#!/bin/bash
NGINX_STATUS=$(ps -ef|grep ngin[x]|wc -l)
# 如果nginx挂了
if [ ${NGINX_STATUS} == 0 ]
then
systemctl restart nginx
# 如果重启失败
if [ $? == 1 ]
then
# keepalived没必要活着了
systemctl stop keepalived
fi
fi
EOF
keepalived调用脚本
cat > /etc/keepalived/keepalived.conf << 'EOF'
global_defs {
router_id lb-5
}
vrrp_script check_web {
script "/etc/keepalived/check_web.sh"
interval 5
}
vrrp_instance VIP_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
track_script {
check_web
}
}
EOF
注意给脚本加上权限
[root@lb-5 ~]#chmod +x /etc/keepalived/check_web.sh
模拟故障
1.确保master和backup正常
2.停止master的nginx
[root@lb-5 ~]#chmod +x /etc/keepalived/check_web.sh
3.发现你此时就已经没法停了,keepalived帮你自动重启nginx
4.你可以试试让nginx起不来
[root@lb-5 ~]#echo 'yuchaoit.cn' >> /etc/nginx/nginx.conf
[root@lb-5 ~]#systemctl stop nginx
[root@lb-5 ~]#
5.此时已经正确切换到backup了。
修复master
[root@lb-5 ~]#systemctl restart nginx
[root@lb-5 ~]#systemctl restart keepalived
查看backup是否归还VIP资源。
小结
Keepalived是一个优秀的高可用工具,不仅可以结合nginx做高可用性负载均衡;
也可以和mysql数据库软件实现主从复制的高可用性;
生产环境负载均衡集群
阿里云提供的高可用性负载均衡文档
https://help.aliyun.com/document_detail/67915.html
看动画片学习什么是负载均衡
待你和于超老师学完了 (高可用性负载均衡集群),在你真真切切的动手练习了,以及掌握其中内部原理了。
再去维护公有云提供的阿里云SLB,就是易如反掌了。
在阿里云上,点击购买不同价格的负载均衡,获取到一个SLB的IP地址(nginx + keepalived)
然后再填写后端的服务器组即可(upstream 地址池)
老铁们,你学废了吗?~~~~