pod精讲
如下的知识点,就是你我们在创建、修改、维护k8s资源、修改yaml文件时
该如何理解yaml中的pod字段的一些属性,一些功能
例如pod的数量、镜像获取、重启策略、健康检查、资源限制等。
k8s基础提问
1.搞清楚yaml,镜像,node,pod的关系
yaml
↓
镜像下载地址(公开,私有)
↓
调度器选择具体node部署pod
↓
镜像会在目标node上(如slave1、slave2)
2.搞清楚k8s-1.24移除docker接口,直接使用containerd管理容器,你不可以很方便的去使用docker命令了,改用命令
- ctr
- crictl
- nerctl
- 90%日常运维都是kubectl完成
查看镜像
不是这么玩了
[root@k8s-master /opt/zbx-k8s]#docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
并且查看的数据目录
[root@k8s-master ~]#ls /var/lib/docker/
# 而建议用,注意-n的添加
[root@k8s-master ~]#nerdctl -n k8s.io images
# 读取的数据目录
[root@k8s-master ~]#ls /var/lib/containerd/
3.查看slave机器的镜像,注意-n参数,默认k8s使用的是 k8s.io,否则不加是default名称空间
crictl默认是直接操作k8s的,默认就是-n k8s.io
ctr、nerdctl是操作containerd的
[root@k8s-slave2 ~]#nerdctl -n k8s.io images
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
10.0.0.66:5000/zabbix-web-nginx-mysql latest c6914033a643 24 hours ago linux/amd64 183.7 MiB 46.9 MiB
flannel/flannel-cni-plugin v1.1.2 bf4b62b13166 4 days ago linux/amd64 7.9 MiB 3.7 MiB
flannel/flannel v0.21.3 2947963f52c2 4 days ago linux/amd64 63.0 MiB 23.1 MiB
kubernetesui/dashboard v2.2.0 148991563e37 4 days ago linux/amd64 223.8 MiB 64.6 MiB
kubernetesui/metrics-scraper v1.0.6 1f977343873e 4 days ago linux/amd64 33.0 MiB 14.4 MiB
redis 3.2 7b0a40301bc1 46 hours ago linux/amd64 79.9 MiB 28.0 MiB
registry.aliyuncs.com/google_containers/kube-proxy v1.24.4 64a04a34b31f 4 days ago linux/amd64 110.1 MiB 37.7 MiB
registry.aliyuncs.com/google_containers/pause 3.6 3d380ca88645 4 days ago linux/amd64 668.0 KiB 294.7 KiB
[root@k8s-slave2 ~]#
[root@k8s-slave2 ~]#
[root@k8s-slave2 ~]#crictl images
IMAGE TAG IMAGE ID SIZE
10.0.0.66:5000/zabbix-web-nginx-mysql latest 7ce5ac13bc18c 49.2MB
docker.io/flannel/flannel-cni-plugin v1.1.2 7a2dcab94698c 3.84MB
docker.io/flannel/flannel v0.21.3 0d004b381af6c 24.2MB
docker.io/kubernetesui/dashboard v2.2.0 5c4ee6ca42ce2 67.8MB
docker.io/kubernetesui/metrics-scraper v1.0.6 48d79e554db69 15.1MB
docker.io/library/redis 3.2 87856cc39862c 29.4MB
registry.aliyuncs.com/google_containers/kube-proxy v1.24.4 7a53d1e08ef58 39.5MB
registry.aliyuncs.com/google_containers/pause 3.6 6270bb605e12e 302kB
[root@k8s-slave2 ~]#
[root@k8s-slave2 ~]#ctr -n k8s.io image ls
REF TYPE DIGEST SIZE PLATFORMS LABELS
10.0.0.66:5000/zabbix-web-nginx-mysql:latest application/vnd.docker.distribution.manifest.v2+json sha256:c6914033a643732be4c371f401391ccbef1f9ad15cccfdae017a9220b185aca5 46.9 MiB linux/amd64 io.cri-containerd.image=managed
docker.io/flannel/flannel-cni-plugin:v1.1.2 application/vnd.docker.distribution.manifest.list.v2+json sha256:bf4b62b131666d040f35a327d906ee5a3418280b68a88d9b9c7e828057210443 3.7 MiB linux/amd64,linux/arm/v6,linux/arm64/v8,linux/mips64le,linux/ppc64le,linux/s390x io.cri-containerd.image=managed
docker.io/flannel/flannel:v0.21.3 application/vnd.docker.distribution.manifest.list.v2+json sha256:2947963f52c22f2df17ba21e47839ad4b9123fb5545784c7922e8264e673268c 23.1 MiB linux/amd64,linux/arm/v6,linux/arm64/v8,linux/mips64le,linux/ppc64le,linux/s390x io.cri-containerd.image=managed
docker.io/kubernetesui/dashboard:v2.2.0 application/vnd.docker.distribution.manifest.list.v2+json sha256:148991563e374c83b75e8c51bca75f512d4f006ddc791e96a91f1c7420b60bd9 64.6 MiB linux/amd64,linux/arm,linux/arm64,linux/ppc64le,linux/s390x io.cri-containerd.image=managed
docker.io/kubernetesui/metrics-scraper:v1.0.6 application/vnd.docker.distribution.manifest.list.v2+json sha256:1f977343873ed0e2efd4916a6b2f3075f310ff6fe42ee098f54fc58aa7a28ab7 14.4 MiB linux/amd64,linux/arm,linux/arm64,linux/ppc64le,linux/s390x io.cri-containerd.image=managed
docker.io/library/redis:3.2 application/vnd.docker.distribution.manifest.list.v2+json sha256:7b0a40301bc1567205e6461c5bf94c38e1e1ad0169709e49132cafc47f6b51f3 28.0 MiB linux/386,linux/amd64,linux/arm/v5,linux/arm/v7,linux/arm64/v8,linux/ppc64le,linux/s390x io.cri-containerd.image=managed
registry.aliyuncs.com/google_containers/kube-proxy:v1.24.4 application/vnd.docker.distribution.manifest.list.v2+json sha256:64a04a34b31fdf10b4c7fe9ff006dab818489a318115cfb284010d04e2888386 37.7 MiB linux/amd64,linux/arm/v7,linux/arm64,linux/ppc64le,linux/s390x io.cri-containerd.image=managed
registry.aliyuncs.com/google_containers/pause:3.6 application/vnd.docker.distribution.manifest.list.v2+json sha256:3d380ca8864549e74af4b29c10f9cb0956236dfb01c40ca076fb6c37253234db 294.7 KiB linux/amd64,linux/arm/v7,linux/arm64,linux/ppc64le,linux/s390x,windows/amd64 io.cri-containerd.image=managed
[root@k8s-slave2 ~]#
4.如何获取flannel镜像
1.本地导出镜像,containerd是兼容使用docker的镜像的
docker save > /opt/flannel.tgz
但是注意,不是docker load了
2.通过--help查看命令功能
ctr --help
crictl --help
nerdctl --help
3.可以使用ctr,但是ctr也有名称空间概念,也是一个资源管理,记住就行
ctr -n k8s.io images export /opt/flannel.tgz
4.强烈建议用nerdctl
nerdctl -n k8s.io load -i /opt/flannel.tgz
5.清理none镜像
nerdctl -n k8s.io image prune --all
6.拉取镜像,携带认证
建议直接用
nerdctl login # 该命令自动生成认证配置文件,而其他命令需要手工修改较多配置,非常繁琐
然后再
nerdctl -n k8s.io pull 10.0.0.66:5000/nginx:v1
7.怎么看pod日志,启动pod失败??排错思路
# 看Events(默认存储1小时,在etcd,会自动清理)
[root@k8s-master ~]#kubectl -n yuchao describe po redis
# 看logs(程序可能会自动重启,例如镜像下载正确,但是启动出错)
# logs看pod,只要启动就可以看到日志,包括exit,crash等非running的pod都可以
[root@k8s-master ~]#kubectl -n yuchao logs --tail=5 eladmin-all
Defaulted container "eladmin-api" out of: eladmin-api, eladmin-web
elAdmin- 2023-03-13 11:07:13 [main] INFO o.s.b.w.e.tomcat.TomcatWebServer - Tomcat started on port(s): 8000 (http) with context path ''
elAdmin- 2023-03-13 11:07:13 [main] INFO o.s.s.quartz.SchedulerFactoryBean - Starting Quartz Scheduler now
elAdmin- 2023-03-13 11:07:13 [main] INFO org.quartz.core.QuartzScheduler - Scheduler quartzScheduler_$_NON_CLUSTERED started.
elAdmin- 2023-03-13 11:07:13 [main] INFO me.zhengjie.AppRun - Started AppRun in 6.93 seconds (JVM running for 7.415)
elAdmin- 2023-03-13 11:07:13 [main] INFO m.z.modules.quartz.config.JobRunner - Timing task injection complete
[root@k8s-master ~]#
# 除非是pod从未启动过,例如container creating,容器还在创建,程序还没启动,哪来的日志?
# 玩IT技术,不要忘记,看日志,因此程序本质就是,stdin、stdout、stderr
8.如果部署eladmin验证码不出现,表示eladmin-web、eladmin-api通信有问题,拿不到后端数据
还得对k8s部署流程有足够深入了解,故障排错,理解web前后端关系,方可熟练使用k8s命令,解决问题。
本章内容pod
服务健康检查
检测容器服务是否健康的手段,若不健康,会根据设置的重启策略(restartPolicy)进行操作,两种检测机制可以分别单独设置,若不设置,默认认为Pod是健康的。
两种机制:
LivenessProbe存活性探针
LivenessProbe探针 存活性探测:用于判断容器是否存活,即Pod是否为running状态,如果
LivenessProbe探针探测到容器不健康,则kubelet将kill掉容器,并根据容器的重启策略是否重启,如果一个容器不包含LivenessProbe探针,则Kubelet认为容器的LivenessProbe探针的返回值永远成功。... containers: - name: eladmin-api image: 10.0.0.66:5000/eladmin/eladmin-api:v1 livenessProbe: tcpSocket: port: 8000 initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒 periodSeconds: 15 # 执行探测的频率 timeoutSeconds: 3 # 探测超时时间 ... # 可配置的参数如下: initialDelaySeconds:容器启动后第一次执行探测是需要等待多少秒。 periodSeconds:执行探测的频率。默认是10秒,最小1秒。 timeoutSeconds:探测超时时间。默认1秒,最小1秒。 successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是1。 failureThreshold:探测成功后,最少连续探测失败多少次 # 本例配置的情况,健康检查的逻辑为: K8S将在Pod开始启动20s(initialDelaySeconds)后探测Pod内的8000端口是否可以建立TCP连接,并且每15秒钟探测一次,如果连续3次探测失败,则kubelet重启该容器
ReadinessProbe可用性探针
可用性探测:用于判断容器是否正常提供服务,即容器的Ready是否为True,是否可以接收请求,如果ReadinessProbe探测失败,则容器的Ready将为False,Endpoint Controller控制器将此Pod的Endpoint从对应的service的Endpoint列表中移除,不再将任何请求调度此Pod上,直到下次探测成功。(剔除此pod不参与接收请求不会将流量转发给此Pod)。
...
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin/eladmin-api:v1
readinessProbe:
httpGet:
path: /auth/code
port: 8000
scheme: HTTP
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
...
# K8S将在Pod开始启动10s(initialDelaySeconds)后利用HTTP访问8000端口的/auth/code,如果超过3s**或者返回码不在200~399内,则健康检查失败
探针动作
三种类型:
exec:通过执行命令来检查服务是否正常,返回值为0则表示容器健康
...
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
...
httpGet方式:通过发送http请求检查服务是否正常,返回200-399状态码则表明容器健康
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin/eladmin-api:v1
readinessProbe:
httpGet:
path: /auth/code
port: 8000
scheme: HTTP
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
tcpSocket:通过容器的IP和Port执行TCP检查,如果能够建立TCP连接,则表明容器健康
...
livenessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
...
redis使用探针
注意pod探针的作用,是给运行的容器,设置检查规则的,因此缩进层级是属于containers字段内的
正常探针
apiVersion: v1
kind: Pod
metadata:
name: redis
namespace: yuchao
labels:
app: redis
spec:
# hostNetwork: true
containers:
- name: redis
image: redis:3.2
ports:
- containerPort: 6379
livenessProbe:
tcpSocket:
port: 6379 # 判断redis是否活了,看端口起没起
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
readinessProbe:
tcpSocket:
port: 6379 # 判断6379是否可访问,可以提供服务
initialDelaySeconds: 10
timeoutSeconds: 2
periodSeconds: 10
创建,查看redis是否正常
[root@k8s-master ~/k8s-all]#kubectl create -f redis-readiness.yaml
pod/redis-readiness created
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po -w
NAME READY STATUS RESTARTS AGE
eladmin-all 2/2 Running 3 (30h ago) 42h
mysql 1/1 Running 1 (30h ago) 46h
redis 1/1 Running 1 (30h ago) 47h
redis-readiness 0/1 ContainerCreating 0 6s
redis-readiness 0/1 Running 0 20s
redis-readiness 1/1 Running 0 30s
查看pod事件
[root@k8s-master ~/k8s-all]#kubectl -n yuchao describe pod redis-readiness
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 93s default-scheduler Successfully assigned yuchao/redis-readiness to k8s-slave1
Normal Pulling 92s kubelet Pulling image "redis:3.2"
Normal Pulled 74s kubelet Successfully pulled image "redis:3.2" in 18.804738663s
Normal Created 73s kubelet Created container redis
Normal Started 73s kubelet Started container redis
如果livenessProbe出错?
修改yaml,修改livenessProbe的监听端口
[root@k8s-master ~/k8s-all]#kubectl delete -f redis-readiness.yaml
pod "redis-readiness" deleted
[root@k8s-master ~/k8s-all]#kubectl create -f redis-readiness.yaml
pod/redis-readiness created
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po -w
NAME READY STATUS RESTARTS AGE
eladmin-all 2/2 Running 3 (30h ago) 42h
mysql 1/1 Running 1 (30h ago) 46h
redis 1/1 Running 1 (30h ago) 47h
redis-readiness 0/1 Running 0 6s
探针10秒测一次,重启一次redis
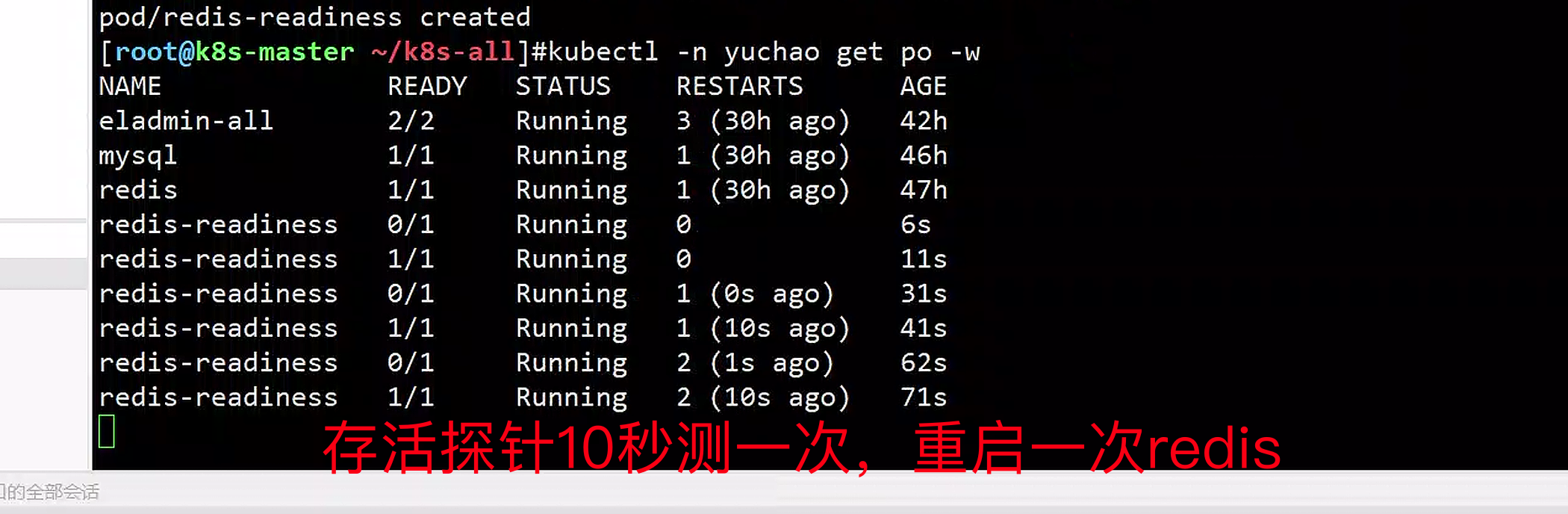
总结,因此livenessProbe探针出错,会认为pod没法存活,会自动反复重启。
以及查看pod的探针事件
[root@k8s-master ~/k8s-all]#kubectl -n yuchao describe pod redis-readiness
如果readinessProbe出错?
修改readinessProbe的监听端口
[root@k8s-master ~/k8s-all]#vim redis-readiness.yaml
[root@k8s-master ~/k8s-all]#kubectl create -f redis-readiness.yaml
pod/redis-readiness created
pod状态
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po -w
NAME READY STATUS RESTARTS AGE
eladmin-all 2/2 Running 3 (30h ago) 43h
mysql 1/1 Running 1 (30h ago) 47h
redis 1/1 Running 1 (30h ago) 2d
redis-readiness 0/1 Running 0 16m
发现探针不通过,不会进入ready就绪的状态,k8s集群的流量,也不会往这个机器上发送,这个pod是不能提供访问的。
[root@k8s-master ~/k8s-all]#kubectl -n yuchao describe pod redis-readiness
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 15m default-scheduler Successfully assigned yuchao/redis-readiness to k8s-slave1
Normal Pulled 15m kubelet Container image "redis:3.2" already present on machine
Normal Created 15m kubelet Created container redis
Normal Started 15m kubelet Started container redis
什么叫流量不往pod发
如service发现后端readiness异常,会剔除该pod。
# pod本身运行后,探针出错,svc流量不会转发过去
# 不代表该pod就是拒绝访问的,发现是可以的
[root@k8s-master ~/k8s-all]#curl 10.244.2.27:6379
-ERR wrong number of arguments for 'get' command
-ERR unknown command 'User-Agent:'
# 访问svc试试,探针不过,流量不会望这发
[root@k8s-master ~/k8s-all]#curl 10.111.94.30:6379
curl: (7) Failed connect to 10.111.94.30:6379; Connection refused
检查svc详细,发现Endpoints也是异常的
[root@k8s-master ~/k8s-all]#kubectl -n yuchao describe svc redis
Name: redis
Namespace: yuchao
Labels: <none>
Annotations: <none>
Selector: app=redis
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.111.94.30
IPs: 10.111.94.30
Port: <unset> 6379/TCP
TargetPort: 6379/TCP
Endpoints:
Session Affinity: None
Events: <none>
[root@k8s-master ~/k8s-all]#
只有redis就绪性探针ok了,svc流量才会转过去,如修复redis的探针问题
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
eladmin-all 2/2 Running 3 (30h ago) 43h 10.244.2.21 k8s-slave1 <none> <none>
mysql 1/1 Running 1 (30h ago) 47h 10.244.0.8 k8s-master <none> <none>
redis-readiness 1/1 Running 0 25s 10.244.2.28 k8s-slave1 <none> <none>
[root@k8s-master ~/k8s-all]#kubectl -n yuchao describe svc redis
Name: redis
Namespace: yuchao
Labels: <none>
Annotations: <none>
Selector: app=redis
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.111.94.30
IPs: 10.111.94.30
Port: <unset> 6379/TCP
TargetPort: 6379/TCP
Endpoints: 10.244.2.28:6379
Session Affinity: None
Events: <none>
[root@k8s-master ~/k8s-all]#
小结探针
Readiness 决定了Service是否将流量导入到该Pod
Liveness决定了容器是否需要被重启
- 有了探针,可以更好的启动、维护程序,确保程序运行正常,以及可访问。
- 以防止,流量发给出错的后端,导致报错500等。
Pod重启策略
[root@k8s-master ~/k8s-all]#kubectl explain pod.spec.restartPolicy
KIND: Pod
VERSION: v1
FIELD: restartPolicy <string>
DESCRIPTION:
Restart policy for all containers within the pod. One of Always, OnFailure,
Never. Default to Always. More info:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#restart-policy
Possible enum values:
- `"Always"`
- `"Never"`
- `"OnFailure"`
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。
当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应的操作。 Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
- Always:当容器进程退出后,由
kubelet自动重启该容器; - OnFailure:当容器终止运行且退出码不为0时,由
kubelet自动重启该容器; - Never:不论容器运行状态如何,
kubelet都不会重启该容器。
演示重启策略:
- eladmin-api 服务连接不上数据库的情况下,分别设置三种重启策略,观察Pod的重启表现
- 使用默认的重启策略,即
restartPolicy: Always,无论容器是否是正常退出,都会自动重启容器 使用OnFailure的策略时
- 如果Pod的1号进程是正常退出,则不会重启
- 只有非正常退出状态才会重启
使用Never时,退出了就不再重启
可以看出,若容器正常退出,Pod的状态会是Completed,非正常退出,状态为Error或者CrashLoopBackOff
实践pod重启策略(always)
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po eladmin-all -oyaml |grep -i restart
restartPolicy: Always
restartCount: 2
restartCount: 1
# 什么叫容器进程退出,例如你启动的这个java程序,连接数据库失败,异常报错了把。退出码 就是非0,表示程序异常了,kubelet自动帮你重启pod,尝试让程序正常启动。
演示重启策略,如下的yaml,故意写错数据库密码
[root@k8s-master ~/k8s-all]#cat pod-eladmin-api.yml
apiVersion: v1
kind: Pod
metadata:
name: eladmin-api
namespace: yuchao
labels:
app: eladmin-api
spec:
imagePullSecrets: # 全局认证,后续容器都使用这个secret
- name: registry-10.0.0.66
restartPolicy: Always
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin/eladmin-api:v1
env:
- name: DB_HOST # 指定数据库地址,更新为svc
value: "10.110.3.172"
- name: DB_USER # 指定数据库连接使用的用户
value: "root"
- name: DB_PWD
value: "www.yuchaoit.cnmmmmmm"
- name: REDIS_HOST
value: "10.111.94.30"
- name: REDIS_PORT
value: "6379"
ports:
- containerPort: 8000 # 同EXPOSE,声明业务端口号
[root@k8s-master ~/k8s-all]#
重建pod
kubectl delete -f pod-eladmin-api.yml
kubectl create -f pod-eladmin-api.yml
查看重启过程
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po eladmin-api -w
NAME READY STATUS RESTARTS AGE
eladmin-api 0/1 Error 1 (10s ago) 15s
eladmin-api 0/1 CrashLoopBackOff 1 (12s ago) 21s
eladmin-api 1/1 Running 2 (13s ago) 22s
eladmin-api 0/1 Error 2 (16s ago) 25s
eladmin-api 0/1 CrashLoopBackOff 2 (13s ago) 38s
eladmin-api 1/1 Running 3 (29s ago) 54s
eladmin-api 0/1 Error 3 (32s ago) 57s
为什么会重启?可以看看事件,只能看到pod不断的在重启
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 84s default-scheduler Successfully assigned yuchao/eladmin-api to k8s-slave1
Normal Pulled 30s (x4 over 84s) kubelet Container image "10.0.0.66:5000/eladmin/eladmin-api:v1" already present on machine
Normal Created 30s (x4 over 83s) kubelet Created container eladmin-api
Normal Started 30s (x4 over 83s) kubelet Started container eladmin-api
Warning BackOff 11s (x5 over 75s) kubelet Back-off restarting failed container
[root@k8s-master ~]#kubectl -n yuchao describe po eladmin-api
到底怎么判断,看pod的日志
[root@k8s-master ~]#kubectl -n yuchao logs --tail=20 eladmin-api
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.invokeCustomInitMethod(AbstractAutowireCapableBeanFactory.java:1930)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.invokeInitMethods(AbstractAutowireCapableBeanFactory.java:1872)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1800)
... 38 common frames omitted
elAdmin- 2023-03-14 18:24:07 [Druid-ConnectionPool-Create-1681303515] ERROR c.alibaba.druid.pool.DruidDataSource - create connection SQLException, url: jdbc:log4jdbc:mysql://10.110.3.172:3306/eladmin?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false, errorCode 1045, state 28000
java.sql.SQLException: Access denied for user 'root'@'10.244.2.29' (using password: YES)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:129)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:829)
at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:449)
at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:242)
at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:198)
at net.sf.log4jdbc.sql.jdbcapi.DriverSpy.connect(DriverSpy.java:401)
at com.alibaba.druid.filter.FilterChainImpl.connection_connect(FilterChainImpl.java:156)
at com.alibaba.druid.filter.stat.StatFilter.connection_connect(StatFilter.java:251)
at com.alibaba.druid.filter.FilterChainImpl.connection_connect(FilterChainImpl.java:150)
at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1659)
at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1723)
at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:2838)
[root@k8s-master ~]#
可以看出答案了,程序启动失败,退出码非0,kubelet自动帮你重启pod,尝试让pod正常运行。
这个过程原理手工演示
[root@docker01 ~]#docker run --rm -it 10.0.0.66:5000/eladmin/eladmin-api:v1 bash
root@e15da88cc627:/opt/eladmin# java -Dspring.profiles.active=prod -jar eladmin-system-2.6.jar
...
elAdmin- 2023-03-14 10:27:51 [Druid-ConnectionPool-Create-2073299099] ERROR c.alibaba.druid.pool.DruidDataSource - create connection SQLException, url: jdbc:log4jdbc:mysql://localhost:3306/eladmin?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false, errorCode 0, state 08S01
com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure
....
root@e15da88cc627:/opt/eladmin# echo $?
1
root@e15da88cc627:/opt/eladmin#
至此,大伙就可以理解pod的重启策略检查原理了。
OnFailure策略
[root@k8s-master ~/k8s-all]#cat pod-eladmin-api.yml
apiVersion: v1
kind: Pod
metadata:
name: eladmin-api
namespace: yuchao
labels:
app: eladmin-api
spec:
imagePullSecrets: # 全局认证,后续容器都使用这个secret
- name: registry-10.0.0.66
restartPolicy: OnFailure # 修改重启策略
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin/eladmin-api:v1
env:
- name: DB_HOST # 指定数据库地址,更新为svc
value: "10.110.3.172"
- name: DB_USER # 指定数据库连接使用的用户
value: "root"
- name: DB_PWD
value: "www.yuchaoit.cnmmmmmm"
- name: REDIS_HOST
value: "10.111.94.30"
- name: REDIS_PORT
value: "6379"
ports:
- containerPort: 8000 # 同EXPOSE,声明业务端口号
创建,查看pod重启,还是自动在重启,因为程序还是因为java连不上数据库,退出状态码非0,导致重启。
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po eladmin-api -owide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
eladmin-api 0/1 Error 3 (40s ago) 67s 10.244.2.30 k8s-slave1 <none> <none>
eladmin-api 0/1 CrashLoopBackOff 3 (13s ago) 67s 10.244.2.30 k8s-slave1 <none> <none>
eladmin-api 1/1 Running 4 (42s ago) 96s 10.244.2.30 k8s-slave1 <none> <none>
eladmin-api 0/1 Error 4 (45s ago) 99s 10.244.2.30 k8s-slave1 <none> <none>
eladmin-api 0/1 CrashLoopBackOff 4 (14s ago) 113s 10.244.2.30 k8s-slave1 <none> <none>
如何验证出OnFailure的效果?
得让容器退出码是0,就不会再重启了
apiVersion: v1
kind: Pod
metadata:
name: eladmin-api
namespace: yuchao
labels:
app: eladmin-api
spec:
imagePullSecrets: # 全局认证,后续容器都使用这个secret
- name: registry-10.0.0.66
restartPolicy: OnFailure
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin/eladmin-api:v1
env:
- name: DB_HOST # 指定数据库地址,更新为svc
value: "10.110.3.172"
- name: DB_USER # 指定数据库连接使用的用户
value: "root"
- name: DB_PWD
value: "www.yuchaoit.cnmmmmmm"
- name: REDIS_HOST
value: "10.111.94.30"
- name: REDIS_PORT
value: "6379"
args:
- sleep
- "10"
ports:
- containerPort: 8000 # 同EXPOSE,声明业务端口号
再试试
[root@k8s-master ~/k8s-all]#cat pod-eladmin-api.yml
apiVersion: v1
kind: Pod
metadata:
name: eladmin-api
namespace: yuchao
labels:
app: eladmin-api
spec:
imagePullSecrets: # 全局认证,后续容器都使用这个secret
- name: registry-10.0.0.66
restartPolicy: OnFailure
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin/eladmin-api:v1
env:
- name: DB_HOST # 指定数据库地址,更新为svc
value: "10.110.3.172"
- name: DB_USER # 指定数据库连接使用的用户
value: "root"
- name: DB_PWD
value: "www.yuchaoit.cnmmmmmm"
- name: REDIS_HOST
value: "10.111.94.30"
- name: REDIS_PORT
value: "6379"
# command修改容器运行后要执行的命令,args是启动容器且传入额外的环境变量,参数等
command: ["sh","-c","echo www.yuchaoit.cn"]
ports:
- containerPort: 8000 # 同EXPOSE,声明业务端口号
执行结果
[root@k8s-master ~/k8s-all]#kubectl create -f pod-eladmin-api.yml
pod/eladmin-api created
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po eladmin-api -owide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
eladmin-api 0/1 Completed 0 13s 10.244.2.32 k8s-slave1 <none> <none>
[root@k8s-master ~/k8s-all]#kubectl -n yuchao logs eladmin-api
www.yuchaoit.cn
可以看出,若容器正常退出,Pod的状态会是Completed
若是非正常退出,状态为Error或者CrashLoopBackOff
在k8s的一些job类型任务,就会看到completed完成状态
镜像拉取策略
spec:
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin/eladmin-api:v1
imagePullPolicy: IfNotPresent
设置镜像的拉取策略,默认为IfNotPresent
- Always,总是拉取镜像,即使本地有镜像也从仓库拉取
- 当你不信任本地镜像时,强制必须去仓库拉取最新的
- 例如本地恶意的通过
docker tag篡改镜像 - 例如本地tag出现覆盖,导致不拉取最新的镜像
- 例如本地恶意的通过
- 当你不信任本地镜像时,强制必须去仓库拉取最新的
- IfNotPresent ,本地有则使用本地镜像,本地没有则去仓库拉取(常用)
- Never,只使用本地镜像,本地没有则报错
Pod资源限制
为了保证充分利用集群资源,且确保重要容器在运行周期内能够分配到足够的资源稳定运行,因此平台需要具备
Pod的资源限制的能力。
对于一个pod来说,资源最基础的2个的指标就是:CPU和内存。
Kubernetes提供了个采用requests和limits 两种类型参数对资源进行预分配和使用限制。
[root@k8s-master ~/k8s-all]#cat redis-readiness.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis-readiness
namespace: yuchao
labels:
app: redis
spec:
# hostNetwork: true
containers:
- name: redis
image: redis:3.2
ports:
- containerPort: 6379
livenessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
readinessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10
timeoutSeconds: 2
periodSeconds: 10
resources:
requests: # 调度pod对node资源的判断
memory: 300Mi # 容器运行至少需要300M内存
cpu: 50m # 申请0.
limits:
memory: 1Gi # 最多用1G内存
cpu: 200m # 0.2个CPU,数字越大,可分配CPU资源越多
requests解释
- 容器使用的最小资源需求,作用于schedule阶段,作为容器调度时资源分配的判断依赖
- 只有当前节点上可分配的资源量 >= request 时才允许将容器调度到该节点
- request参数不限制容器的最大可使用资源
- requests.cpu被转成docker的--cpu-shares参数,与cgroup cpu.shares功能相同 (无论宿主机有多少个cpu或者内核,--cpu-shares选项都会按照比例分配cpu资源)
- requests.memory没有对应的docker参数,仅作为k8s调度依据
limits解释
容器能使用资源的最大值
设置为0表示对使用的资源不做限制, 可无限的使用
当pod 内存超过limit时,会被oom
当cpu超过limit时,不会被kill,但是会限制不超过limit值
limits.cpu会被转换成docker的–cpu-quota参数。与cgroup cpu.cfs_quota_us功能相同
limits.memory会被转换成docker的–memory参数。用来限制容器使用的最大内存
对于 CPU,我们知道计算机里 CPU 的资源是按
“时间片”的方式来进行分配的,系统里的每一个操作都需要 CPU 的处理,所以,哪个任务要是申请的 CPU 时间片越多,那么它得到的 CPU 资源就越多。
然后还需要了解下 CGroup 里面对于 CPU 资源的单位换算:
1 CPU = 1000 millicpu(1 Core = 1000m)
这里的 m 就是毫、毫核的意思,Kubernetes 集群中的每一个节点可以通过操作系统的命令来确认本节点的 CPU 内核数量,然后将这个数量乘以1000,得到的就是节点总 CPU 总毫数。
比如一个节点有四核,那么该节点的 CPU 总毫量为 4000m。
注意:若内存使用超出限制,会引发系统的OOM机制,因CPU是可压缩资源,不会引发Pod退出或重建
查看node资源剩余
[root@k8s-master ~/k8s-all]#kubectl describe nodes k8s-slave1 |tail
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 100m (5%) 0 (0%)
memory 50Mi (1%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events: <none>
[root@k8s-master ~/k8s-all]#
节点已经分配的资源如上,主要关注limits的百分比,若是很高了,基本不会调取pod到这
memory是不可压缩的,用多少是多少
cpu可以超分
看master可以看到用的更多资源
[root@k8s-master ~/k8s-all]#kubectl describe nodes k8s-master
Addresses:
InternalIP: 10.0.0.80
Hostname: k8s-master
Capacity:
cpu: 4
ephemeral-storage: 47285700Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7992340Ki
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 43578501048
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7889940Ki
pods: 110
System Info:
Machine ID: 1766b53cd44340a9a80ec6837a2e6f60
System UUID: BAAC4D56-56FF-34D1-9804-F22608DE7C84
Boot ID: e2b6ba07-fa36-497d-9fe4-240700995d23
Kernel Version: 3.10.0-862.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.6.18
Kubelet Version: v1.24.4
Kube-Proxy Version: v1.24.4
PodCIDR: 10.244.0.0/24
PodCIDRs: 10.244.0.0/24
Non-terminated Pods: (11 in total)
Namespace Name CPU Requests CPU Limits
...
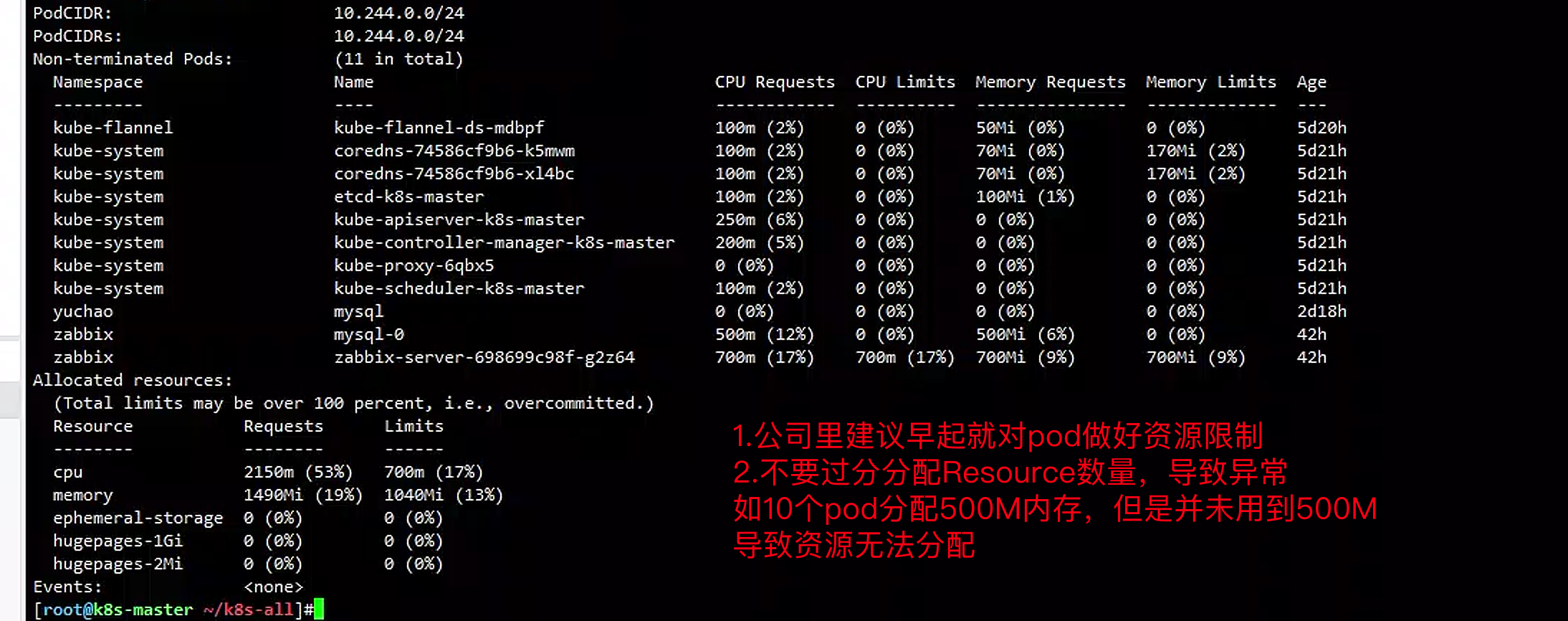
1.kubelet是可以设置reserved预留资源
2.可以查看公司生产下其他pod的资源限制yaml,作为参考。
实践database资源限制
Redis
apiVersion: v1
kind: Pod
metadata:
name: redis
namespace: yuchao
labels:
app: redis
spec:
containers:
- name: redis
image: redis:6
ports:
- containerPort: 6379
livenessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
readinessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
resources:
requests:
memory: 100Mi
cpu: 50m
limits:
memory: 4Gi
cpu: 2
创建
[root@k8s-master ~/k8s-all]#kubectl create -f redis-resources.yaml
pod/redis created
mysql
apiVersion: v1
kind: Pod
metadata:
name: mysql
namespace: yuchao
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_DATABASE # 指定数据库地址
value: "eladmin"
- name: MYSQL_ROOT_PASSWORD
value: "www.yuchaoit.cn"
ports:
- containerPort: 3306
args:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
livenessProbe:
tcpSocket:
port: 3306
initialDelaySeconds: 15 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
readinessProbe:
tcpSocket:
port: 3306
initialDelaySeconds: 15 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
resources:
requests:
memory: 200Mi
cpu: 50m
limits:
memory: 1Gi
cpu: 500m
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
volumes:
- name: mysql-data
hostPath:
path: /opt/mysql/
nodeSelector: # 使用节点选择器将Pod调度到指定label的节点
mysql: "true"
创建
[root@k8s-master ~/k8s-all]#kubectl create -f mysql-resources.yaml
pod/mysql created
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po
NAME READY STATUS RESTARTS AGE
mysql 1/1 Running 0 21s
redis 1/1 Running 0 7m16s
Eladmin-api
- 给java后端资源多一点
- 数据库用的是svc地址
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
eladmin-all NodePort 10.107.166.189 <none> 80:31718/TCP 2d14h
eladmin-api NodePort 10.101.249.141 <none> 8000:30651/TCP 2d14h
mysql ClusterIP 10.110.3.172 <none> 3306/TCP 2d19h
redis ClusterIP 10.111.94.30 <none> 6379/TCP 2d20h
具体yaml
apiVersion: v1
kind: Pod
metadata:
name: eladmin-api
namespace: yuchao
labels:
app: eladmin-api
spec:
imagePullSecrets:
- name: registry-10
restartPolicy: Always
imagePullSecrets: # 全局认证,后续容器都使用这个secret
- name: registry-10.0.0.66
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin/eladmin-api:v1
env:
- name: DB_HOST # 指定数据库地址
value: "10.110.3.172"
- name: DB_USER # 指定数据库连接使用的用户
value: "root"
- name: DB_PWD
value: "www.yuchaoit.cn"
- name: REDIS_HOST
value: "10.111.94.30"
- name: REDIS_PORT
value: "6379"
ports:
- containerPort: 8000
livenessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
readinessProbe:
httpGet:
path: /auth/code
port: 8000
scheme: HTTP
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
resources:
requests:
memory: 200Mi
cpu: 50m
limits:
memory: 3Gi # 根据你机器配置去设置
cpu: 1
创建结果
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po -owide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
eladmin-api 0/1 Running 0 20s 10.244.2.34 k8s-slave1 <none> <none>
mysql 1/1 Running 0 7m35s 10.244.0.14 k8s-master <none> <none>
redis 1/1 Running 0 14m 10.244.2.33 k8s-slave1 <none> <none>
eladmin-api 1/1 Running 0 31s 10.244.2.34 k8s-slave1 <none> <none>
如何判断程序资源限制
1.开发自测,给与数值参考
2.在设置资源限制之前,需要知道您的Java应用程序的资源需求。
可以通过运行Java应用程序并使用Linux工具如top、vmstat和iostat等来查看其资源使用情况。
3.具体的资源限制需要根据你的应用程序实际需要和服务器配置情况来设置,建议你根据你的应用负载和性能需求进行调整。
如果你的应用程序需要大量的内存来处理数据,那么你可能需要增加内存限制;
如果你的应用程序需要大量的 CPU 时间来执行计算任务,那么你可能需要增加 CPU 限制。
查看slave1资源
[root@k8s-master ~/k8s-all]#kubectl describe nodes k8s-slave1
yaml安全优化
上面的java应用yaml连接数据库的密码都是明文,及其危险,过不了安全审核。
为什么要优化
yaml的环境变量中存在敏感信息(账号、密码),存在安全隐患
为什么要统一管理环境变量
- 环境变量中有很多敏感的信息,比如账号密码,直接暴漏在yaml文件中存在安全性问题
- 对于开发、测试、生产环境,由于配置均不同,每套环境部署的时候都要修改yaml,带来额外的开销
ConfigMap和Secret
k8s提供两类资源,configMap和Secret,可以用来实现业务配置的统一管理, 允许将配置文件与镜像文件分离,以使容器化的应用程序具有可移植性 。
configmap去存储明文配置文件,实现动态替换,或者简单的环境变量
secret存储密码进行加密
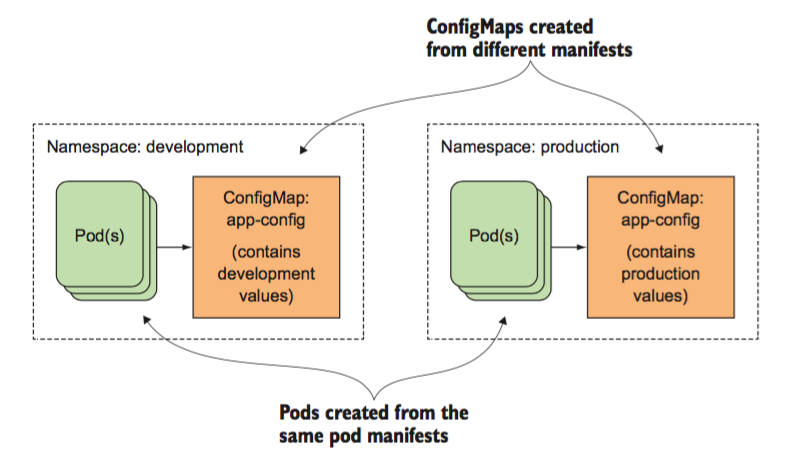
怎么用
Kubernetes中的ConfigMap和Secret都是用来管理应用程序的配置信息和敏感信息的。
它们的区别在于ConfigMap用于存储非敏感的配置信息,而Secret则用于存储敏感的配置信息。
下面是它们在不同场景下的用途:
ConfigMap的使用场景
ConfigMap适用于以下场景:
- 应用程序需要访问的配置信息,如数据库连接字符串、端口号、环境变量等。
- 为应用程序提供自定义配置,以便用户可以更轻松地配置应用程序。
- 在不同的环境中(例如开发、测试和生产)中使用不同的配置。
ConfigMap可以通过多种方式提供配置信息,包括从文件中加载、从环境变量中加载、从命令行参数中加载等。
Secret的使用场景
Secret适用于以下场景:
- 应用程序需要使用的敏感数据,如数据库密码、API密钥、证书等。
- 在不同的环境中使用不同的凭据,例如不同的API密钥、不同的证书等。
- 与ConfigMap一样,为应用程序提供自定义配置。
与ConfigMap类似,Secret可以通过多种方式提供敏感信息,包括从文件中加载、从环境变量中加载、从命令行参数中加载等。
但是,为了确保敏感信息的安全性,Secret的数据会被加密,并且只能被特定的Pod访问。
总之,ConfigMap和Secret都是Kubernetes中用于管理应用程序配置和敏感信息的重要工具。
它们可以提高应用程序的可移植性和安全性,并且可以轻松地在不同的环境中管理应用程序的配置和敏感信息。
configmap
很简单,就是原本写在yaml里明文的数据库密码
改为让pod去configmap中读取
configMap,通常用来管理应用的配置文件或者环境变量。
这些值,是从eladmin-api中env提取而来。
apiVersion: v1
kind: ConfigMap
metadata:
name: eladmin
namespace: yuchao
data:
DB_HOST: "10.110.3.172"
DB_USER: "root"
REDIS_HOST: "10.111.94.30"
REDIS_PORT: "6379"
创建cm资源
$ kubectl create -f configmap.yaml
$ kubectl -n yuchao get configmap eladmin -oyaml
还有更方便的用法,从文件中读取key-value创建configmap
是工作里常用的方式
# 文件
cat env-configs.txt
DB_HOST=10.110.3.172
REDIS_HOST=10.111.94.30
REDIS_PORT=6379
# 创建
kubectl -n yuchao create configmap eladmin --from-env-file=env-configs.txt
# 查看
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get cm
NAME DATA AGE
eladmin 3 8s
kube-root-ca.crt 1 4d1h
查看创建的cm信息,可以看到是明文的信息
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get cm eladmin -oyaml
apiVersion: v1
data:
DB_HOST: 10.110.3.172
REDIS_HOST: 10.111.94.30
REDIS_PORT: "6379"
kind: ConfigMap
metadata:
creationTimestamp: "2023-03-15T13:56:28Z"
name: eladmin
namespace: yuchao
resourceVersion: "720163"
secret
Secret,管理敏感类的信息,默认会base64编码存储,有三种类型
Service Account:用来访问Kubernetes API,由Kubernetes自动创建,并且会自动挂载到Pod的/run/secrets/kubernetes.io/serviceaccount目录中;- 创建
ServiceAccount后,Pod中指定serviceAccount后,自动创建该ServiceAccount对应的secret;
- 创建
Opaque:base64编码格式的Secret,用来存储密码、密钥等;(常用)kubernetes.io/dockerconfigjson:用来存储私有docker registry的认证信息。
cat >env-secret.txt<<'EOF'
DB_PWD=www.yuchaoit.cn
DB_USER=root
EOF
kubectl -n yuchao create secret generic eladmin-secret --from-env-file=env-secret.txt
kubectl -n yuchao get secret
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get secret eladmin-secret -oyaml
apiVersion: v1
data:
DB_PWD: d3d3Lnl1Y2hhb2l0LmNu
DB_USER: cm9vdA==
kind: Secret
metadata:
creationTimestamp: "2023-03-15T14:05:15Z"
name: eladmin-secret
namespace: yuchao
resourceVersion: "720903"
uid: a13e9455-ffe8-4aba-8d17-ba6bd5c3d0a3
type: Opaque
[root@k8s-master ~/k8s-all]#
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get secrets
NAME TYPE DATA AGE
eladmin-secret Opaque 2 14m
registry-10.0.0.66 kubernetes.io/dockerconfigjson 1 3d22h
也可以写成yaml的形式创建
也可以通过如下方式:
apiVersion: v1
kind: Secret
metadata:
name: eladmin-secret
namespace: yuchao
type: Opaque
data:
DB_USER: cm9vdA== #注意加-n参数, echo -n root|base64
DB_PWD: d3d3Lnl1Y2hhb2l0LmNu # 别加任何其他符号 echo -n www.yuchaoit.cn|base64
eladmin引入配置
图解
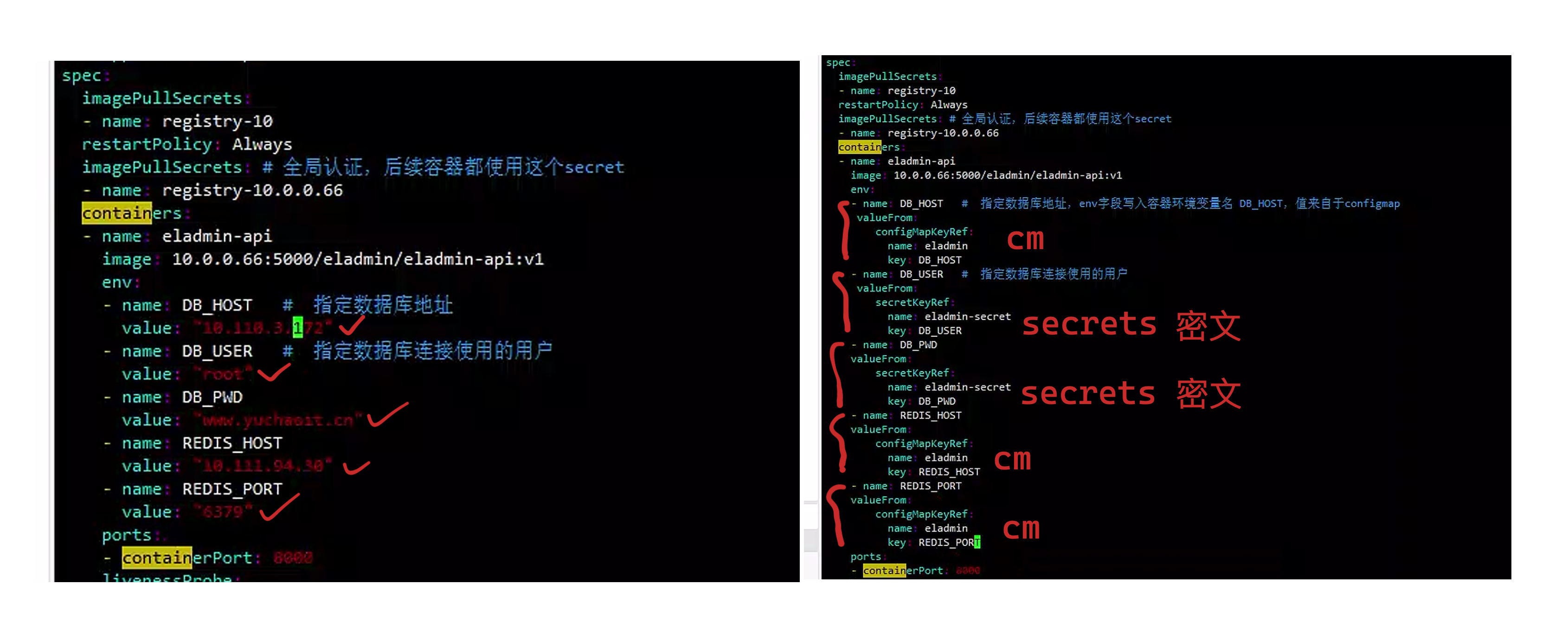
yaml优化
[root@k8s-master ~/k8s-all]#cat elamin-api-resources.yml
apiVersion: v1
kind: Pod
metadata:
name: eladmin-api
namespace: yuchao
labels:
app: eladmin-api
spec:
imagePullSecrets:
- name: registry-10
restartPolicy: Always
imagePullSecrets: # 全局认证,后续容器都使用这个secret
- name: registry-10.0.0.66
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin/eladmin-api:v1
env:
- name: DB_HOST # 指定数据库地址,env字段写入容器环境变量名 DB_HOST,值来自于configmap
valueFrom:
configMapKeyRef:
name: eladmin
key: DB_HOST
- name: DB_USER # 指定数据库连接使用的用户
valueFrom:
secretKeyRef:
name: eladmin-secret
key: DB_USER
- name: DB_PWD
valueFrom:
secretKeyRef:
name: eladmin-secret
key: DB_PWD
- name: REDIS_HOST
valueFrom:
configMapKeyRef:
name: eladmin
key: REDIS_HOST
- name: REDIS_PORT
valueFrom:
configMapKeyRef:
name: eladmin
key: REDIS_PORT
ports:
- containerPort: 8000
livenessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 15 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
readinessProbe:
httpGet:
path: /auth/code
port: 8000
scheme: HTTP
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 30 # 执行探测的频率
timeoutSeconds: 3 # 探测超时时间
resources:
requests:
memory: 200Mi
cpu: 50m
limits:
memory: 3Gi
cpu: 1
创建pod,查看pod
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po -owide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
eladmin-api 0/1 Running 0 22s 10.244.2.36 k8s-slave1 <none> <none>
mysql 1/1 Running 0 81m 10.244.0.14 k8s-master <none> <none>
redis 1/1 Running 0 88m 10.244.2.33 k8s-slave1 <none> <none>
eladmin-api 1/1 Running 0 32s 10.244.2.36 k8s-slave1 <none> <none>
# 查看pod详细
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po eladmin-api -o yaml
# 查看启动日志,是否正常
[root@k8s-master ~/k8s-all]#kubectl -n yuchao logs eladmin-api
重点,查看eladmin-api的环境变量
root@eladmin-api:/opt/eladmin# env|grep -iE 'db_host|db_user|db_pwd|redis_host|redis_port'
REDIS_PORT_6379_TCP_PROTO=tcp
DB_HOST=10.110.3.172
REDIS_PORT_6379_TCP_ADDR=10.111.94.30
REDIS_PORT_6379_TCP_PORT=6379
REDIS_HOST=10.111.94.30
REDIS_PORT_6379_TCP=tcp://10.111.94.30:6379
DB_PWD=www.yuchaoit.cn
REDIS_PORT=6379
DB_USER=root
root@eladmin-api:/opt/eladmin#
# secret注入到pod的环境变量后,还是做了解码
当然,k8s的secret是对字符串进行编码处理,只要你能有操作k8s机器的权限,也可以base64解码。