ETCD
官网: https://github.com/etcd-io/etcd
下载贝etcdctl命令行工具:
wget https://github.com/etcd-io/etcd/releases/download/v3.5.3/etcd-v3.5.3-linux-amd64.tar.gz
tar -xf etcd-v3.5.3-linux-amd64.tar.gz
[root@k8s-master /opt/etcd-v3.5.3-linux-amd64]#ls
Documentation etcd etcdctl etcdutl README-etcdctl.md README-etcdutl.md README.md READMEv2-etcdctl.md
[root@k8s-master ~]#etcdctl version
etcdctl version: 3.5.3
API version: 3.5
连接ETCD服务端
# etcd有早期的v2版本,读写都是v2的api
# 如今是v3版本,k8s写入etcd数据是v3版本
# 先声明api版本
export ETCDCTL_API=3
# 连接etcd,需要引入证书
[root@k8s-master ~]#netstat -tunlp|grep 2379
tcp 0 0 127.0.0.1:2379 0.0.0.0:* LISTEN 2012/etcd
tcp 0 0 10.0.0.80:2379 0.0.0.0:* LISTEN 2012/etcd
# 为什么是这个端口2379
[root@k8s-master ~]#kubectl -n kube-system get po -owide |grep etcd
etcd-k8s-master 1/1 Running 2 (6d2h ago) 21d 10.0.0.80 k8s-master <none> <none>
# 可知etcd的pod、是以hostNetwork网络启动的
[root@k8s-master ~]#kubectl -n kube-system get po etcd-k8s-master -oyaml|grep -i host
host: 127.0.0.1
host: 127.0.0.1
hostNetwork: true
- hostPath:
- hostPath:
hostIP: 10.0.0.80
# 连接命令
# 存放k8s的证书目录,证书是成对出现,私钥+证书
# /etc/kubernetes/pki/
[root@k8s-master ~]#etcdctl --endpoints=https://[127.0.0.1]:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt --key=/etc/kubernetes/pki/etcd/healthcheck-client.key member list -w table
+---------------+---------+------------+------------------------+------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+---------------+---------+------------+------------------------+------------------------+------------+
| bbb7bc08dd69e | started | k8s-master | https://10.0.0.80:2380 | https://10.0.0.80:2379 | false |
+---------------+---------+------------+------------------------+------------------------+------------+
[root@k8s-master ~]#
# 做个别名,省事
[root@k8s-master ~]#tail -2 ~/.bashrc
export ETCDCTL_API=3
alias etcdctl='etcdctl --endpoints=https://[127.0.0.1]:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt --key=/etc/kubernetes/pki/etcd/healthcheck-client.key'
[root@k8s-master ~]#
# 省事了
[root@k8s-master ~]#etcdctl member list -w table
+---------------+---------+------------+------------------------+------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+---------------+---------+------------+------------------------+------------------------+------------+
| bbb7bc08dd69e | started | k8s-master | https://10.0.0.80:2380 | https://10.0.0.80:2379 | false |
+---------------+---------+------------+------------------------+------------------------+------------+
[root@k8s-master ~]#
查看etcd集群节点
[root@k8s-master ~]#etcdctl endpoint status -w table
+--------------------------+---------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+--------------------------+---------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://[127.0.0.1]:2379 | bbb7bc08dd69e | 3.5.3 | 4.1 MB | true | false | 4 | 1936598 | 1936598 | |
+--------------------------+---------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
[root@k8s-master ~]#
# 一般关注DB SIZE ,存储数据量
# 健康检查
[root@k8s-master ~]#etcdctl endpoint health -w table
+--------------------------+--------+-----------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+--------------------------+--------+-----------+-------+
| https://[127.0.0.1]:2379 | true | 3.84725ms | |
+--------------------------+--------+-----------+-------+
etcd数据规律
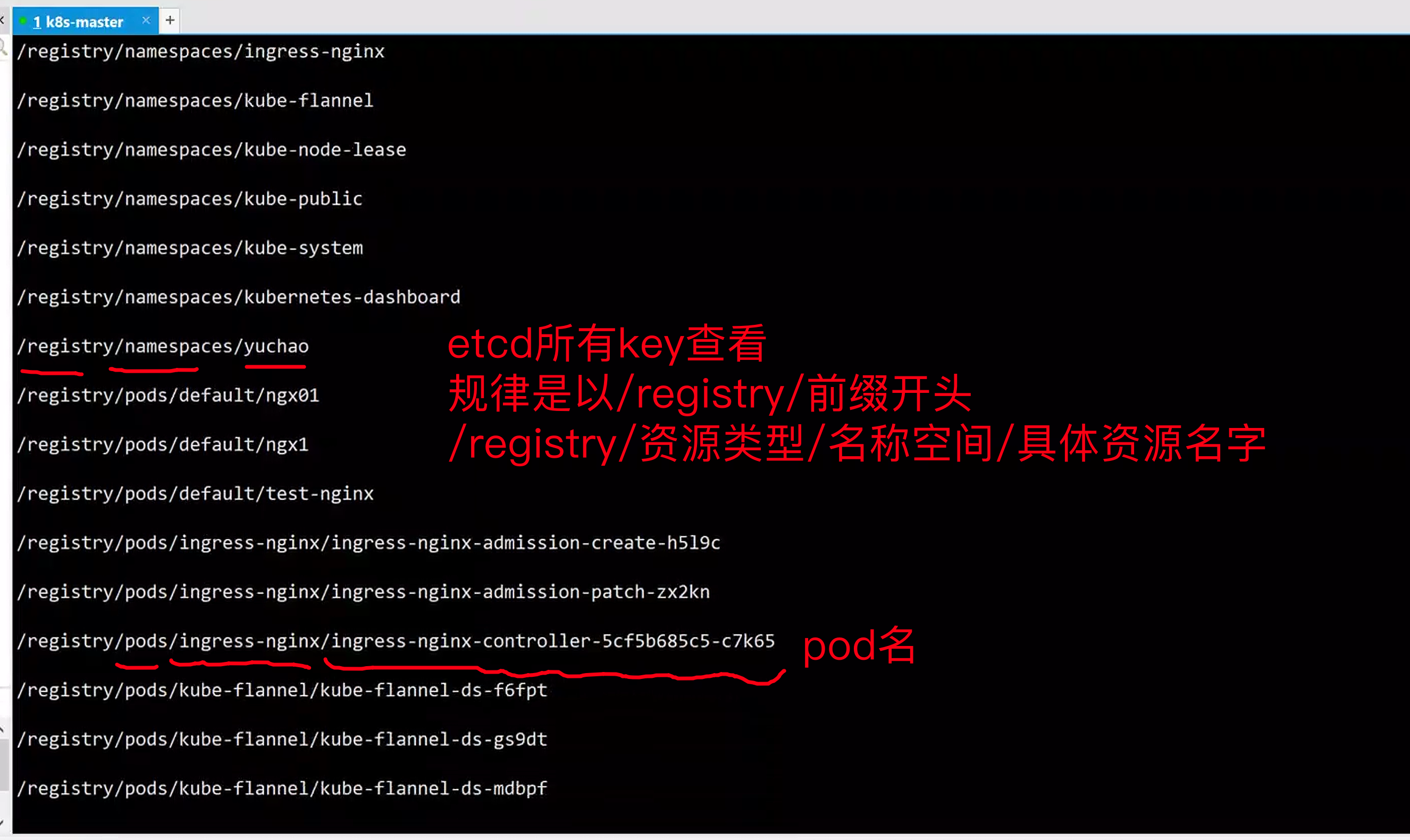
查看之前练习的eladmin的所有资源
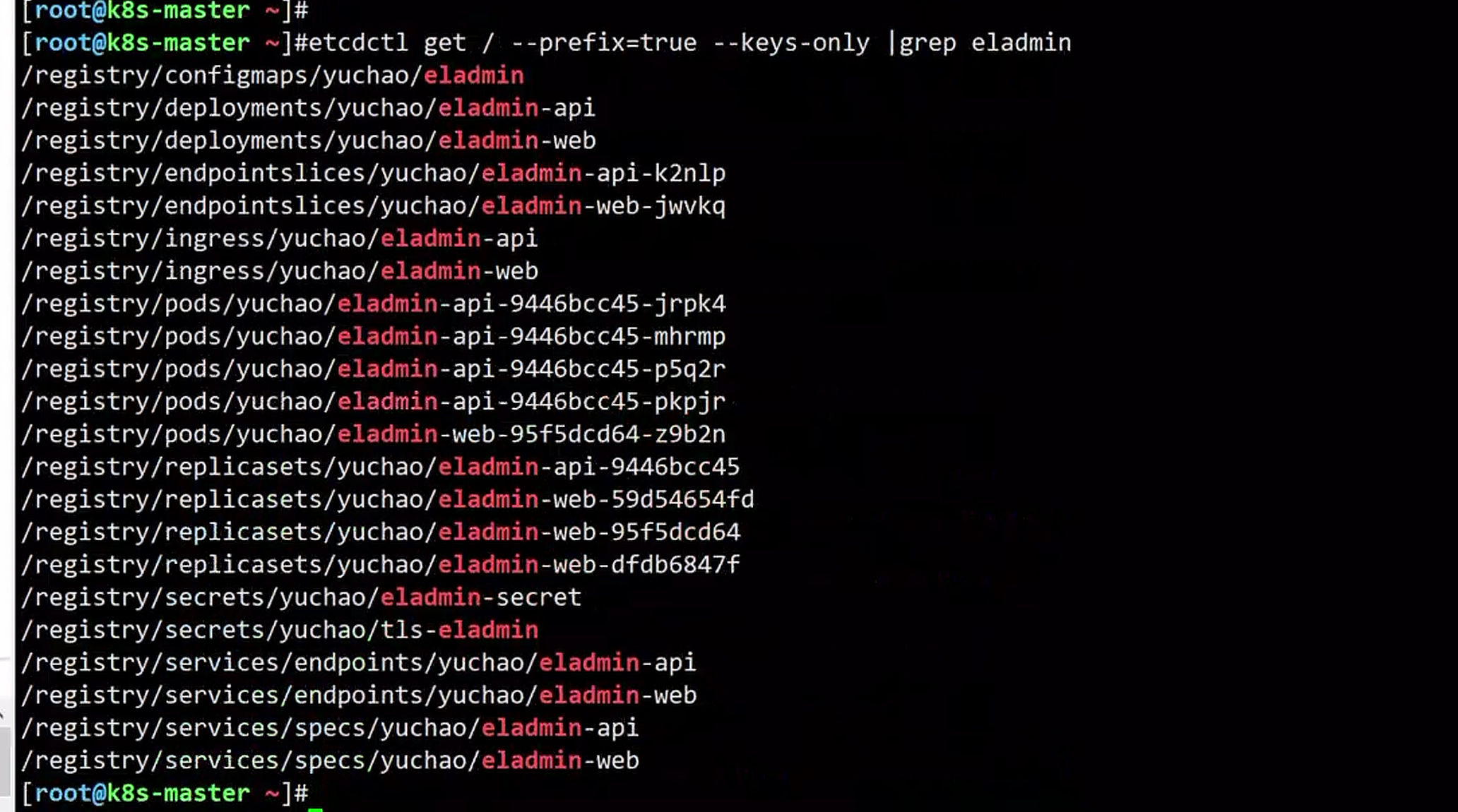
etcd数据管理
参考redis理解即可
[root@k8s-master ~]#etcdctl put name yuchao
OK
[root@k8s-master ~]#etcdctl get name
name
yuchao
# 查看所有key,且只显示key、不显示value
[root@k8s-master ~]#etcdctl get / --prefix=true --keys-only
# 读取key数据、有一些是是压缩过默认无法阅读的
[root@k8s-master ~]#etcdctl get /registry/secrets/yuchao/eladmin-secret
/registry/secrets/yuchao/eladmin-secret
k8s
v1Secretþ
Ł
eladmin-secretyuchao"*$9ca94034-9a2c-4a8a-baf8-420ef9fedac72»➆zr
kubectl-createUpdatev»➆FieldsV1:>
<{"f:data":{".":{},"f:DB_PWD":{},"f:DB_USER":{}},"f:type":{}}B
DB_PWDwww.yuchaoit.cn
DB_USERrootOpaque"
理解list-watch机制
k8s组件的更新都是与etcd通过监听机制实现的
# 自己创建一个前缀、理解就是个文件夹,可以存储key
# 监听key
[root@k8s-master ~]#etcdctl watch /www.yuchaoit.cn/ --prefix
# 写入目录下的key数据试试
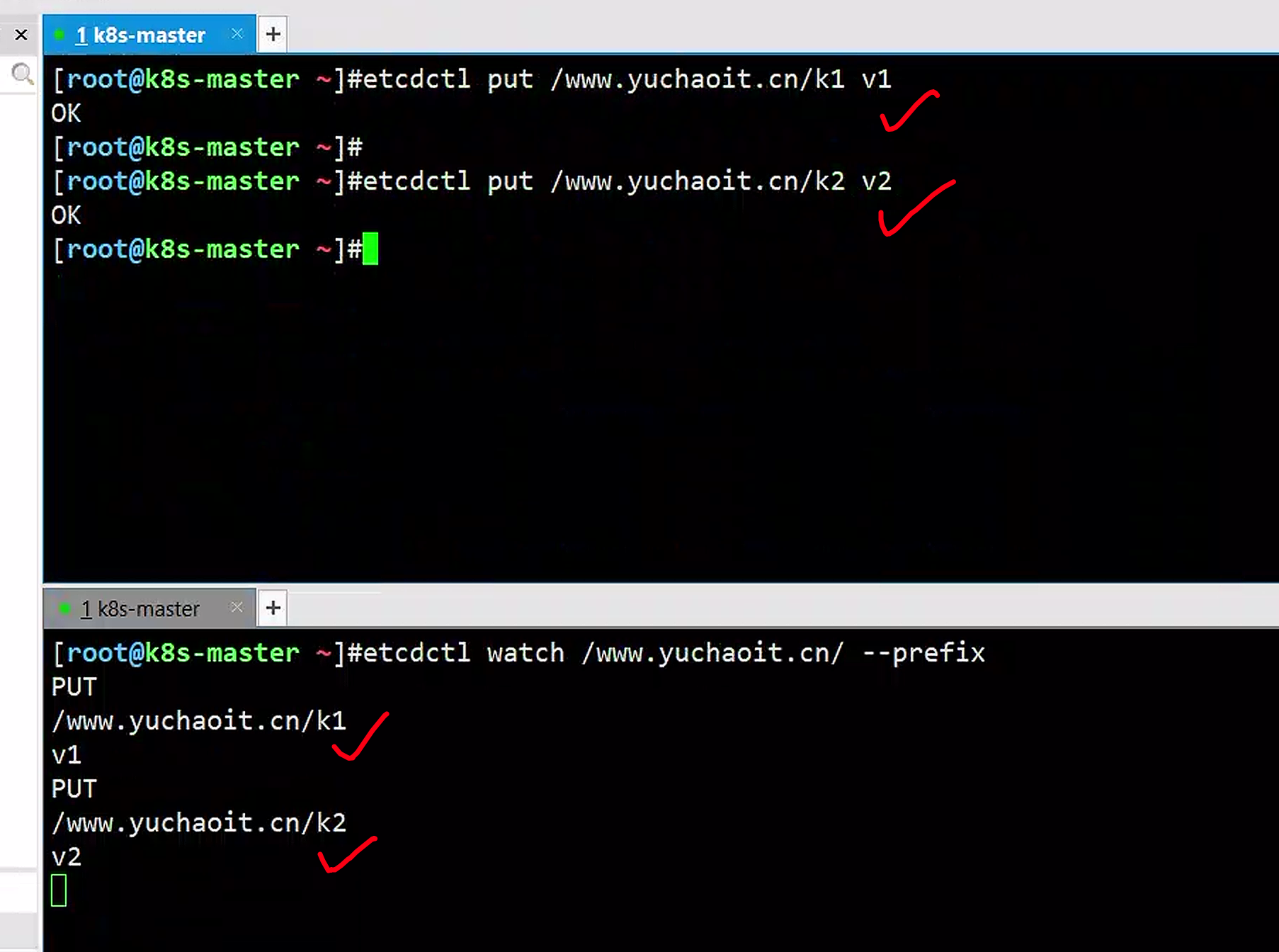
监听ns下的pod变化
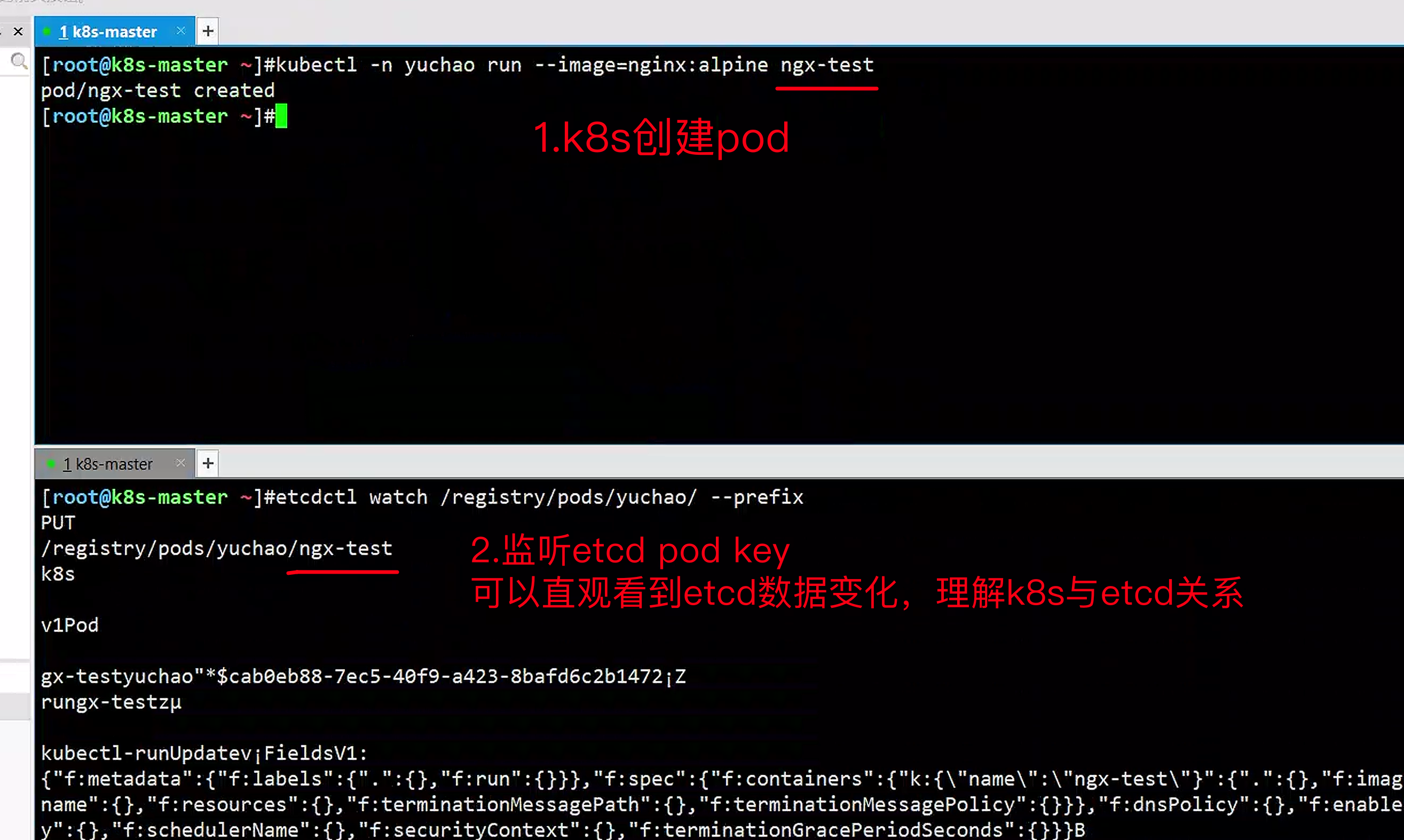
过程解读

etcd备份(运维必会)
一句话,etcd出问题,你k8s就完蛋了,必须给备份好。
你也别想跑路。。跑不掉。。哈哈
[root@k8s-master ~]#mkdir etcd_bak
[root@k8s-master ~]#cd etcd_bak/
[root@k8s-master ~/etcd_bak]#
[root@k8s-master ~/etcd_bak]#
[root@k8s-master ~/etcd_bak]#etcdctl snapshot save `hostname`-etcd_`date +%Y%m%d%H%M`.db
{"level":"info","ts":"2023-03-31T02:22:55.181+0800","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"k8s-master-etcd_202303310222.db.part"}
{"level":"info","ts":"2023-03-31T02:22:55.186+0800","logger":"client","caller":"v3/maintenance.go:211","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":"2023-03-31T02:22:55.186+0800","caller":"snapshot/v3_snapshot.go:73","msg":"fetching snapshot","endpoint":"https://[127.0.0.1]:2379"}
{"level":"info","ts":"2023-03-31T02:22:55.220+0800","logger":"client","caller":"v3/maintenance.go:219","msg":"completed snapshot read; closing"}
{"level":"info","ts":"2023-03-31T02:22:55.223+0800","caller":"snapshot/v3_snapshot.go:88","msg":"fetched snapshot","endpoint":"https://[127.0.0.1]:2379","size":"4.1 MB","took":"now"}
{"level":"info","ts":"2023-03-31T02:22:55.223+0800","caller":"snapshot/v3_snapshot.go:97","msg":"saved","path":"k8s-master-etcd_202303310222.db"}
Snapshot saved at k8s-master-etcd_202303310222.db
[root@k8s-master ~/etcd_bak]#ll -h
total 4.0M
-rw------- 1 root root 4.0M Mar 31 02:22 k8s-master-etcd_202303310222.db
# etcd高可用集群,肯定是3台机器都备份
etcd恢复
恢复教程文档
https://github.com/etcd-io/etcd/blob/release-3.3/Documentation/op-guide/recovery.md
api-server与kubelet配置文件关系
# 恢复前置动作
# 1.停止etcd、apiserver,防止数据写入
# 移走k8s的配置文件,就会导致api-server连接不上了
[root@k8s-master ~/etcd_bak]#ls /etc/kubernetes/manifests/
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
# 这个目录是kubelet管理的静态pod,所有配置文件
# kubelet是在node节点上创建了几个静态pod的组件
[root@k8s-master ~/etcd_bak]#ps -ef|grep kubelet |grep config.yaml
root 1042 1 1 Mar24 ? 01:59:10 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --container-runtime=remote --container-runtime-endpoint=unix:///var/run/containerd/containerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
# kubelet默认的配置文件
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
[root@k8s-master ~/etcd_bak]#cat /var/lib/kubelet/config.yaml
# 只要在这个目录下的配置,kubelet会自动创建该pod资源。
# /etc/kubernetes/manifests
# 2.移走api-server的配置文件
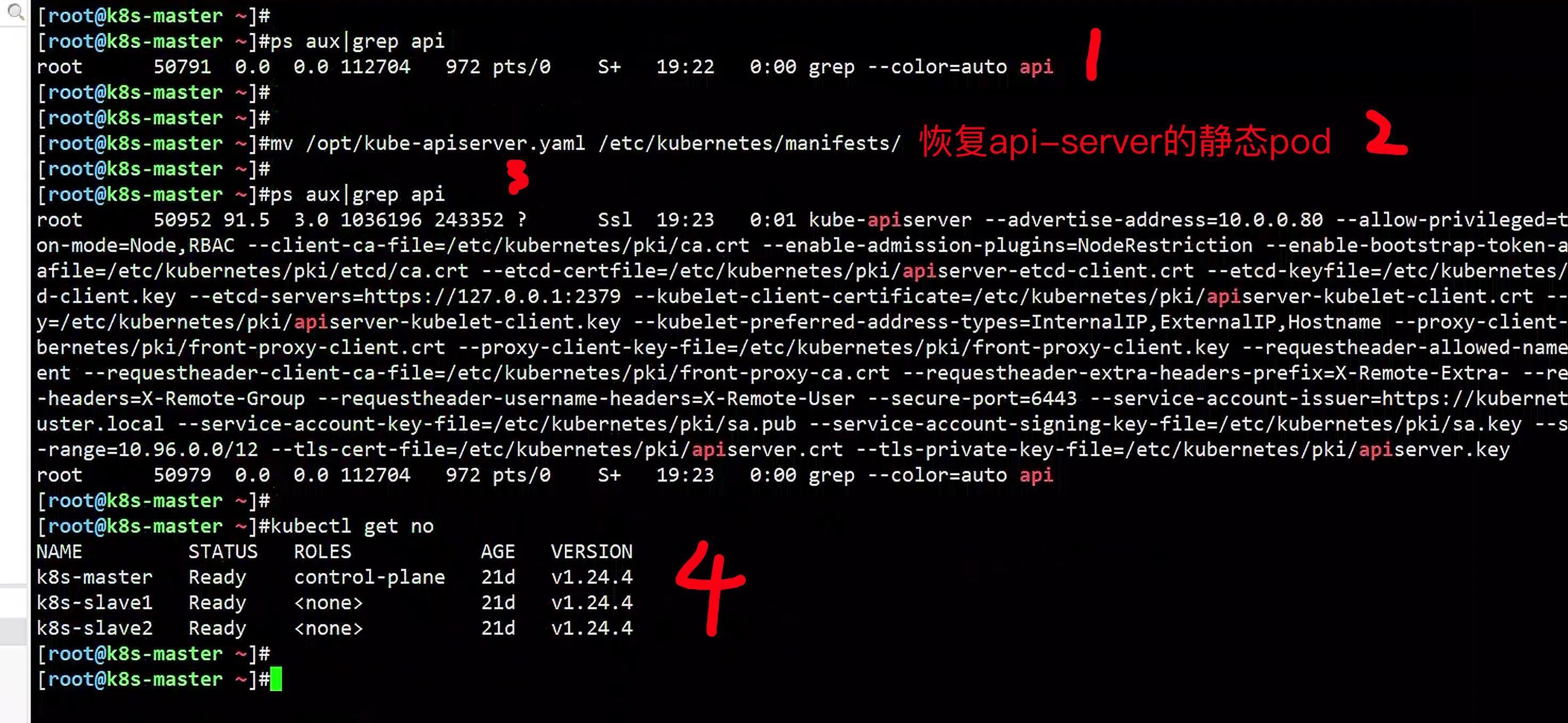
[root@k8s-master ~/etcd_bak]#mv /etc/kubernetes/manifests/kube-apiserver.yaml /root
# 3.集群挂了,无法操作k8s
[root@k8s-master ~/etcd_bak]#kubectl get po
The connection to the server 10.0.0.80:6443 was refused - did you specify the right host or port?
# 4.移走etcd默认数据,模拟数据丢失
[root@k8s-master ~/etcd_bak]#mv /var/lib/etcd/ /tmp/
# 5.恢复etcd数据
etcdctl snapshot restore `hostname`-etcd_`date +%Y%m%d%H%M`.db --data-dir=/var/lib/etcd/
# 6.恢复api-server
[root@k8s-master ~/etcd_bak]#mv /root/kube-apiserver.yaml /etc/kubernetes/manifests/
# kubelet会自动重新启动api-server
[root@k8s-master ~/etcd_bak]#kubectl get po
NAME READY STATUS RESTARTS AGE
ngx01 1/1 Running 1 (6d4h ago) 8d
ngx1 1/1 Running 2 (6d4h ago) 19d
test-nginx 1/1 Running 2 (6d4h ago) 21d
# 7.证明k8s、etcd都恢复数据了,集群正常
图解
etcd可以直接删除k8s资源
当然这个操作,不建议去用,是在无法正常操作k8s的时候,才去删除etcd。
很多情况下,会出现namespace删除卡住的问题,此时可以通过操作etcd来删除数据。
创建测试namespace
[root@k8s-master ~]#kubectl create ns chaoge
namespace/chaoge created
[root@k8s-master ~]#
[root@k8s-master ~]#etcdctl get / --prefix=true --keys-only |grep chaoge
/registry/configmaps/chaoge/kube-root-ca.crt
/registry/namespaces/chaoge
/registry/serviceaccounts/chaoge/default
直接删数据库etcd
[root@k8s-master ~]#etcdctl del /registry/namespaces/chaoge
1
[root@k8s-master ~]#etcdctl del /registry/namespaces/chaoge
0
又或者说直接删掉pod
[root@k8s-master ~]#etcdctl del /registry/pods/chaoge/ngx-chaoge
1
正确删除姿势
[root@k8s-master ~]#kubectl delete ns chaoge
namespace "chaoge" deleted
[root@k8s-master ~]#etcdctl get / --prefix=true --keys-only |grep chaoge
[root@k8s-master ~]#
走kubectl删除会校验、清理所有有关chaoge namespace资源的内容
etcd救命操作(重要)
- k8s服务器突然断电、爆炸、水淹等特殊情况
- 机器硬盘直接故障,如何恢复k8s?
- 会导致etcd数据库直接损坏,无法使用,也无法操作k8s集群,怎么办?
你只能跑路了。。。打开boss直聘
恢复etcd数据技巧
思路就是
1.前提是你有备份(一般都是异地备份)。。。没备份你赶紧买车票跑路
2.重新装新etcd机器,恢复数据
[root@docker01 /opt]#ls
containerd etcd-v3.5.3-linux-amd64 etcd-v3.5.3-linux-amd64.tar.gz k8s-mysql-data mysql zbx-yaml
[root@docker01 /opt]#
# 恢复数据
export ETCDCTL_API=3
# 恢复数据是不需要认证的
etcdctl snapshot restore k8s-master-etcd_202303310222.db --data-dir=/root/etcd/data
# 检查数据
[root@docker01 /opt]#du -sh /root/etcd/data/member/
65M /root/etcd/data/member/
# 启动etcd,这里用docker去测试,都是http协议的,以及新集群的测试,默认是https的
# 因此可以连接本地的2379测试etcd
name="etcd-single"
host="10.0.0.66"
cluster="etcd1=http://10.0.0.66:2380"
docker run -d --privileged=true \
-p 2379:2379 \
-p 2380:2380 \
-v /root/etcd/data:/data/etcd \
--name $name \
--net=host \
quay.io/coreos/etcd:v3.5.0 \
/usr/local/bin/etcd \
--name $name \
--data-dir /data/etcd \
--listen-client-urls http://$host:2379 \
--advertise-client-urls http://$host:2379 \
--listen-peer-urls http://$host:2380 \
--initial-advertise-peer-urls http://$host:2380 \
--initial-cluster $cluster \
--initial-cluster-token=yuchao \
--initial-cluster-state=new \
--force-new-cluster \
--log-level info \
--logger zap \
--log-outputs stderr
验证恢复etcd的情况
[root@docker01 /opt]#docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d98cba33619a quay.io/coreos/etcd:v3.5.0 "/usr/local/bin/etcd…" 3 seconds ago Up 3 seconds etcd-single
0d32fd9da7d2 registry "/entrypoint.sh /etc…" 10 days ago Up 6 days 0.0.0.0:5000->5000/tcp, :::5000->5000/tcp registry
[root@docker01 /opt]#
# 验证集群
# 验证集群
export ETCDCTL_API=3
export ETCD_ENDPOINTS=10.0.0.66:2379
etcdctl --endpoints=$ETCD_ENDPOINTS -w table member list
etcdctl --endpoints=$ETCD_ENDPOINTS -w table endpoint status
# 能拿到这个,就是能拿到你宕机之前的k8s数据了
etcdctl --endpoints=$ETCD_ENDPOINTS get / --prefix --keys-only
# 能看到这些,你就不用跑路了。。。《备份的重要性!》
[root@docker01 /opt]#etcdctl --endpoints=$ETCD_ENDPOINTS get / --prefix --keys-only |grep yuchao
k8s恢复整个名称空间(技巧)
不小心删除了特定的namespace下的数据,如何恢复
# 思路:k8s资源哪来的?
# 是 eladmin.yaml > k8s资源 > etcd 这个顺序
etcdhelper工具
etcdhelper是OpenShift Origin项目中的一个工具,用于与etcd键值存储系统交互并执行一些操作,例如备份和恢复etcd数据等。
OpenShift Origin是一个用于构建、部署和管理容器化应用程序的开源平台,它使用etcd作为其主要的分布式键值存储系统。etcdhelper提供了一些管理etcd数据的功能,包括备份和还原数据,以及打印特定键的值。
总的来说,etcdhelper是用于管理OpenShift Origin平台中的etcd存储的工具,它可以帮助管理员执行一些必要的操作来确保平台的稳定性和可靠性。
https://github.com/openshift/origin/tree/master/tools/etcdhelper
# 这个二进制文件很大,可以用docker构建golang的环境,就可以使用该工具了
# 手工下载好源码
[root@docker01 /opt]#ll -d /opt/origin-master
drwxr-xr-x 13 root root 4096 Mar 30 19:19 /opt/origin-master
# 编译操作
$ docker run -d --name go-builder golang:1.19 sleep 30000
$ docker cp origin-master go-builder:/go
$ docker exec -ti go-builder bash
# 修改go编译环境,源
root@8a3ca9ca75c7:/go# ls
bin origin-master src
root@8a3ca9ca75c7:/go# go env -w GOPROXY=https://goproxy.cn,direct
root@8a3ca9ca75c7:/go#
# 开始编译
root@8a3ca9ca75c7:/go# cd /go/origin-master/
root@8a3ca9ca75c7:/go/origin-master#
root@8a3ca9ca75c7:/go/origin-master# CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build tools/etcdhelper/etcdhelper.go
# 编译完事后,拷贝命令即可
root@a7c93a6d7be7:/go/origin-master# ls -lh etcdhelper
-rwxr-xr-x 1 root root 51M Mar 31 08:07 etcdhelper
[root@docker01 /opt]#cp etcdhelper /usr/bin/
# 回宿主机拷贝使用命令
[root@docker01 /opt]#docker cp go-builder:/go/origin-master/etcdhelper .
[root@docker01 /opt]#etcdhelper --help
Usage of etcdhelper:
-cacert string
Server TLS CA certificate.
-cert string
TLS client certificate.
-endpoint string
etcd endpoint. (default "https://127.0.0.1:2379")
-key string
TLS client key.
使用etcdhelper
export ETCDCTL_API=3
export ETCD_ENDPOINTS=10.0.0.66:2379
etcdhelper -endpoint $ETCD_ENDPOINTS ls
# 你会发现,很神器的,把etcd数据读取为了json格式
etcdhelper -endpoint $ETCD_ENDPOINTS get /registry/pods/yuchao/mysql-7c7cf8495f-5w5bk
# 当你有了该mysql-pod的json数据,只需要转为yaml,就又可以用k8s快乐的玩耍了
kubectl没法直接通过json创建资源,因此需要将json文件保存且转换成为yaml格式
批量保存所有key转json
# 通过etcdctl或者luffy相关的资源存储的key
export ETCDCTL_API=3
export ETCD_ENDPOINTS=10.0.0.66:2379
etcdctl --endpoints=$ETCD_ENDPOINTS get / --prefix --keys-only|grep yuchao >keys.txt
# 使用脚本利用etcdhelper将key转换成为json文件
cat >key_to_json.sh<<'EOF'
#!/bin/bash
i=0
export ETCDCTL_API=3
export ETCD_ENDPOINTS=10.0.0.66:2379
for line in `cat keys.txt`
do
etcdhelper -endpoint $ETCD_ENDPOINTS get $line >$i.json
sed -i '1d' $i.json # 删除第一行的玩意
let 'i+=1'
done
EOF
执行脚本
[root@docker01 /opt]#mkdir keys_json
[root@docker01 /opt]#cd keys_json/
[root@docker01 /opt/keys_json]#cat >key_to_json.sh<<'EOF'
> #!/bin/bash
>
> i=0
> export ETCDCTL_API=3
> export ETCD_ENDPOINTS=10.0.0.66:2379
> for line in `cat keys.txt`
> do
> etcdhelper -endpoint $ETCD_ENDPOINTS get $line >$i.json
> sed -i '1d' $i.json # 删除第一行的玩意
> let 'i+=1'
> done
> EOF
[root@docker01 /opt/keys_json]#etcdctl --endpoints=$ETCD_ENDPOINTS get / --prefix --keys-only|grep yuchao >keys.txt
[root@docker01 /opt/keys_json]#
[root@docker01 /opt/keys_json]#sh key_to_json.sh
[root@docker01 /opt/keys_json]#ls
0.json 12.json 15.json 18.json 20.json 23.json 26.json 29.json 31.json 34.json 37.json 4.json 7.json keys.txt
10.json 13.json 16.json 19.json 21.json 24.json 27.json 2.json 32.json 35.json 38.json 5.json 8.json key_to_json.sh
11.json 14.json 17.json 1.json 22.json 25.json 28.json 30.json 33.json 36.json 3.json 6.json 9.json
[root@docker01 /opt/keys_json]#
批量更换json为yaml
# 进入go环境
docker exec -ti go-builder bash
# 获取工具
root@a7c93a6d7be7:/go# git clone https://gitee.com/yuco/json2yaml-go
Cloning into 'json2yaml-go'...
remote: Enumerating objects: 6, done.
remote: Counting objects: 100% (6/6), done.
remote: Compressing objects: 100% (5/5), done.
remote: Total 6 (delta 0), reused 6 (delta 0), pack-reused 0
Receiving objects: 100% (6/6), done.
root@a7c93a6d7be7:/go#
# 编译工具
root@a7c93a6d7be7:/go# cd json2yaml-go/
root@a7c93a6d7be7:/go/json2yaml-go# ls
README.md go.mod go.sum json2yaml.go
root@a7c93a6d7be7:/go/json2yaml-go# GO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -o json2yaml json2yaml.go
go: downloading github.com/ghodss/yaml v1.0.0
go: downloading gopkg.in/yaml.v2 v2.4.0
root@a7c93a6d7be7:/go/json2yaml-go#
root@a7c93a6d7be7:/go/json2yaml-go# ls -lh json2yaml
-rwxr-xr-x 1 root root 3.0M Mar 31 08:27 json2yaml
# 拷贝工具
[root@docker01 /opt/keys_json]#docker cp go-builder:/go/json2yaml-go/json2yaml .
# 批量转换json为yaml
[root@docker01 /opt/keys_json]#./json2yaml -jp .
[root@docker01 /opt/keys_json]#ls *.yaml
0.json.yaml 13.json.yaml 17.json.yaml 20.json.yaml 24.json.yaml 28.json.yaml 31.json.yaml 35.json.yaml 3.json.yaml 7.json.yaml
10.json.yaml 14.json.yaml 18.json.yaml 21.json.yaml 25.json.yaml 29.json.yaml 32.json.yaml 36.json.yaml 4.json.yaml 8.json.yaml
11.json.yaml 15.json.yaml 19.json.yaml 22.json.yaml 26.json.yaml 2.json.yaml 33.json.yaml 37.json.yaml 5.json.yaml 9.json.yaml
12.json.yaml 16.json.yaml 1.json.yaml 23.json.yaml 27.json.yaml 30.json.yaml 34.json.yaml 38.json.yaml 6.json.yaml
[root@docker01 /opt/keys_json]#
# 至此就拿到yuchao这个名称空间下,所有的yaml文件了
# 这时候,只需要在新的k8s机器中,kubectl apply -f ./*.yaml
# 即可一键恢复某个namespace下所有的内容
删库跑路试试
#删除整个namspace
[root@k8s-master ~]#
[root@k8s-master ~]#kubectl delete ns yuchao
namespace "yuchao" deleted
# 试试用刚才的恢复
[root@k8s-master ~/yuchao_yaml]#ls
0.json.yaml 13.json.yaml 17.json.yaml 20.json.yaml 24.json.yaml 28.json.yaml 31.json.yaml 35.json.yaml 3.json.yaml 7.json.yaml
10.json.yaml 14.json.yaml 18.json.yaml 21.json.yaml 25.json.yaml 29.json.yaml 32.json.yaml 36.json.yaml 4.json.yaml 8.json.yaml
11.json.yaml 15.json.yaml 19.json.yaml 22.json.yaml 26.json.yaml 2.json.yaml 33.json.yaml 37.json.yaml 5.json.yaml 9.json.yaml
12.json.yaml 16.json.yaml 1.json.yaml 23.json.yaml 27.json.yaml 30.json.yaml 34.json.yaml 38.json.yaml 6.json.yaml
[root@k8s-master ~/yuchao_yaml]#kubectl apply -f .
# nice完美恢复
[root@k8s-master ~/yuchao_yaml]#kubectl -n yuchao get po
NAME READY STATUS RESTARTS AGE
eladmin-api-9446bcc45-4m26n 1/1 Running 2 (65s ago) 101s
eladmin-api-9446bcc45-5mtkm 1/1 Running 2 (63s ago) 101s
eladmin-api-9446bcc45-6mrn4 1/1 Running 2 (62s ago) 101s
eladmin-api-9446bcc45-7h4vt 1/1 Running 2 (64s ago) 101s
eladmin-web-95f5dcd64-h47vz 1/1 Running 0 100s
mysql-7c7cf8495f-55b6v 1/1 Running 0 100s
ngx-test 1/1 Running 0 101s
redis-7957d49f44-bmcpt 1/1 Running 0 100s
[root@k8s-master ~/yuchao_yaml]#
小结
- etcdctl直接查询key数据,是压缩数据无法阅读
- etcdhelper可以读取etcd数据为json格式
- 再将json转yaml
- 也就拿到了k8s资源的可阅读数据对象
- 也可以用于恢复k8s资源
- 数据恢复是很麻烦的操作、还需要专门的DBA去维护
- 上述于超老师讲解的是,恢复namespace下所有资源的一个玩法,理解即可