Scheduler
Kubernetes是一个开源的容器编排平台,它提供了许多功能来自动化应用程序的部署、扩展、管理和升级。其中一个重要的组件是Pod Scheduler(Pod调度器),它负责将应用程序的容器(Pod)分配到可用的节点(Node)上。
Pod Scheduler的作用非常重要,因为它可以确保应用程序在集群中的运行是高效、稳定、可靠的。
如果没有Pod Scheduler,管理员可能需要手动将容器分配到节点上,并需要时刻监控集群状态以保证应用程序的高可用性。而这样的方式是非常低效且容易出错的。
为什么要学pod调度策略
学习Pod Scheduler的知识可以帮助管理员更好地了解Kubernetes的工作原理,从而更好地管理和运维集群。
学习 Kubernetes 中的 Pod 调度 (scheduling) 是非常重要的,因为 Pod 调度是 Kubernetes 中的核心功能之一。Pod 是 Kubernetes 中的最小调度单位,它包含了一个或多个容器,而 Pod 调度是 Kubernetes 集群将 Pod 分配到节点的过程。
学习 Pod 调度的预选、优选、驱逐和容忍等概念,可以帮助你更好地理解 Kubernetes 中的调度机制和原理。这些概念与 Kubernetes 集群的可用性、可靠性和性能密切相关。
以下是一些具体的原因:
- 了解 Kubernetes 中的 Pod 调度策略可以帮助你更好地规划和管理集群资源。你可以通过配置调度策略来确保 Pod 在运行时满足资源需求,以及最大化利用集群资源。
- 了解 Pod 调度的预选、优选、驱逐和容忍等过程可以帮助你更好地排查和解决调度问题。当你遇到调度失败或 Pod 被驱逐的问题时,你可以通过了解这些概念来确定问题的根本原因,并作出相应的调整。
- 熟悉 Pod 调度的预选、优选、驱逐和容忍等机制可以帮助你更好地设计和管理应用程序。在应用程序设计时,你可以考虑集群中的节点资源情况,以及应用程序对资源的需求,从而使应用程序更好地适应 Kubernetes 环境。
学习pod调度是为了理解,在业务本身的k8s化部署以外,需要学习k8s自身提供的一些pod调度相关的功能。
为什么要限制pod调度规则
因为默认pod调度室schduler自动取选择的,我们也可以加上一些pod调度的策略。
- 集群中有些机器的配置高(SSD,更好的内存等),我们希望核心的服务(比如说数据库)运行在上面
- 某两个服务的网络传输很频繁,我们希望它们最好在同一台机器上
- ......
Kubernetes Scheduler 的作用是将待调度的 Pod 按照一定的调度算法和策略绑定到集群中一个合适的 Worker Node 上,并将绑定信息写入到 etcd 中,之后目标 Node 中 kubelet 服务通过 API Server 监听到 Scheduler 产生的 Pod 绑定事件获取 Pod 信息,然后下载镜像启动容器。
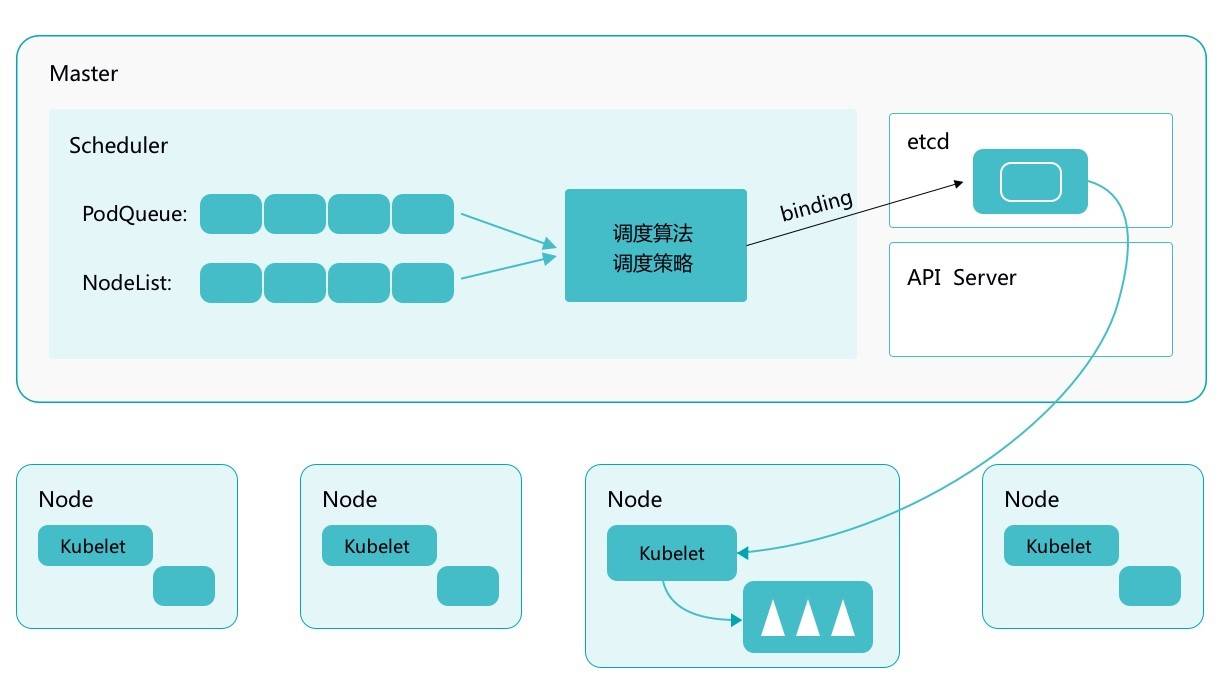
理解调度阶段
在Kubernetes中,调度器(Scheduler)是一种组件,它负责将Pod分配到可用的节点上。在Scheduler中,预选和优选是两个不同的阶段,它们帮助Scheduler选择最佳的节点来运行Pod。
预选阶段是指Scheduler在考虑节点是否可用时所执行的第一轮筛选。在预选阶段,Scheduler会对所有可用的节点进行评估,并根据预设的策略和Pod的要求进行筛选,剔除那些无法满足Pod的要求的节点。例如,如果Pod需要特定的资源(如CPU或内存),Scheduler会排除那些不符合要求的节点。
优选阶段是指Scheduler在预选阶段之后所执行的第二轮筛选。在优选阶段,Scheduler会对通过预选的节点进行再次评估,并根据更多的因素(如负载均衡、亲和性、反亲和性等)来选择最佳的节点。例如,Scheduler可以考虑已经运行在节点上的其他Pod,以确保节点的资源分配合理。
总之,预选和优选是Kubernetes调度器中的两个重要阶段,它们可以帮助Scheduler选择最适合Pod的节点,并确保Pod的健康和高可用性。
Scheduler 提供的调度流程分为预选 (Predicates) 和优选 (Priorities) 两个步骤:
预选,K8S会遍历当前集群中的所有 Node,筛选出其中符合要求的 Node 作为候选。- 预选是0、1的关系
- 例如端口冲突
- 例如nodeSelector
优选,K8S将对候选的 Node 进行打分- 例如候选机器的机器负载情况,CPU、内存等
经过预选筛选和优选打分之后,K8S选择分数最高的 Node 来运行 Pod,如果最终有多个 Node 的分数最高,那么 Scheduler 将从当中随机选择一个 Node 来运行 Pod。
总之,预选和优选是Kubernetes调度器中的两个阶段,它们有助于调度器选择最适合Pod的节点,并确保Pod的高可用性和资源利用率。
图解2个调度阶段
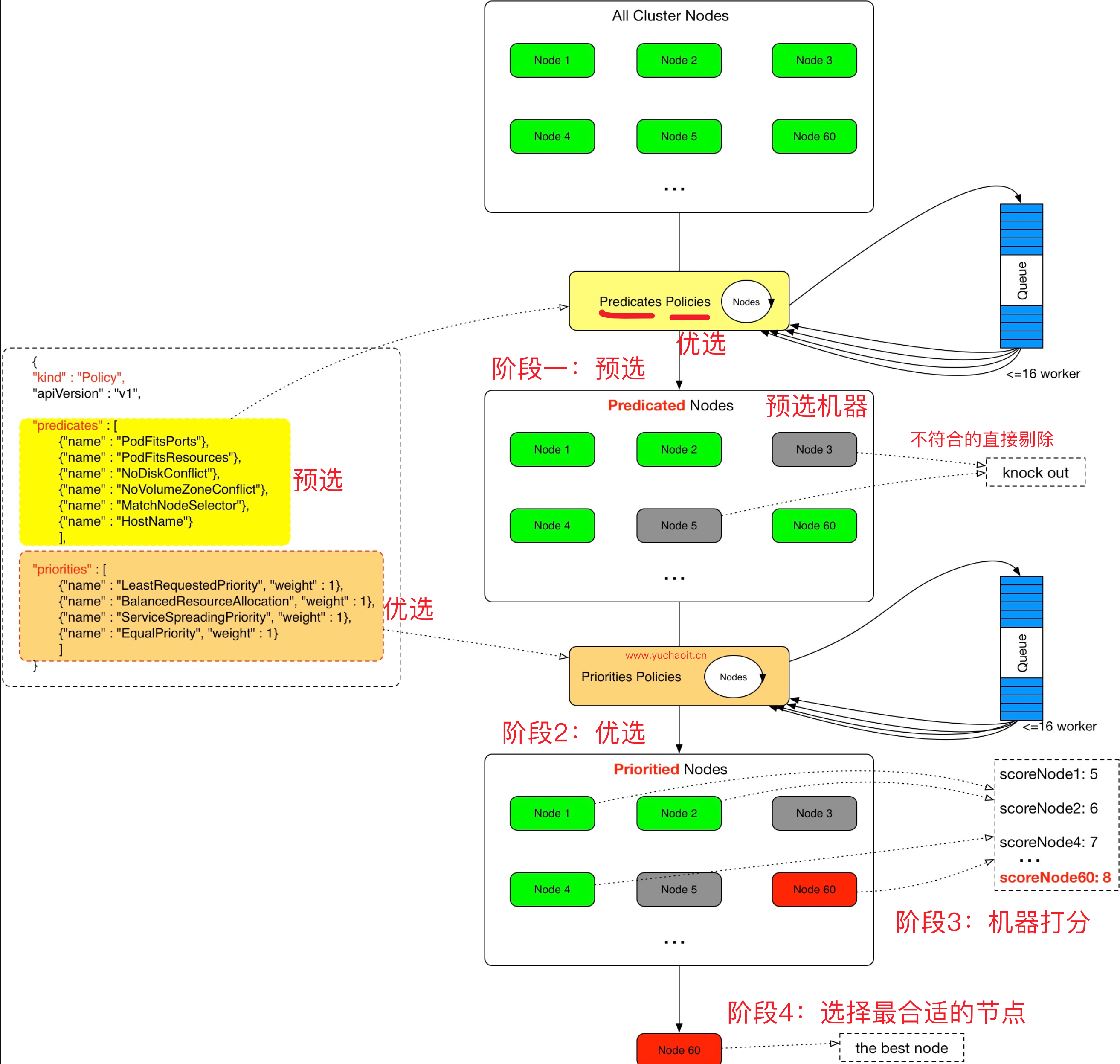
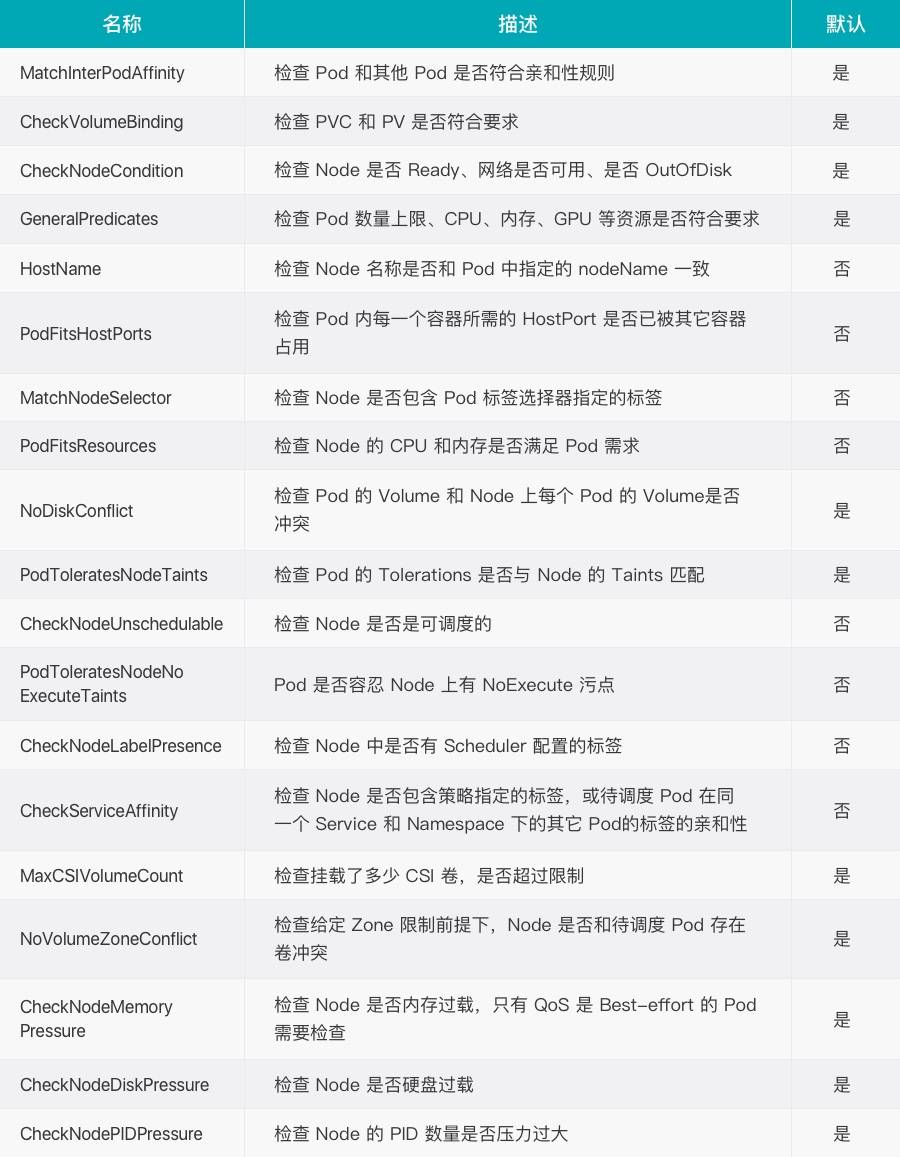
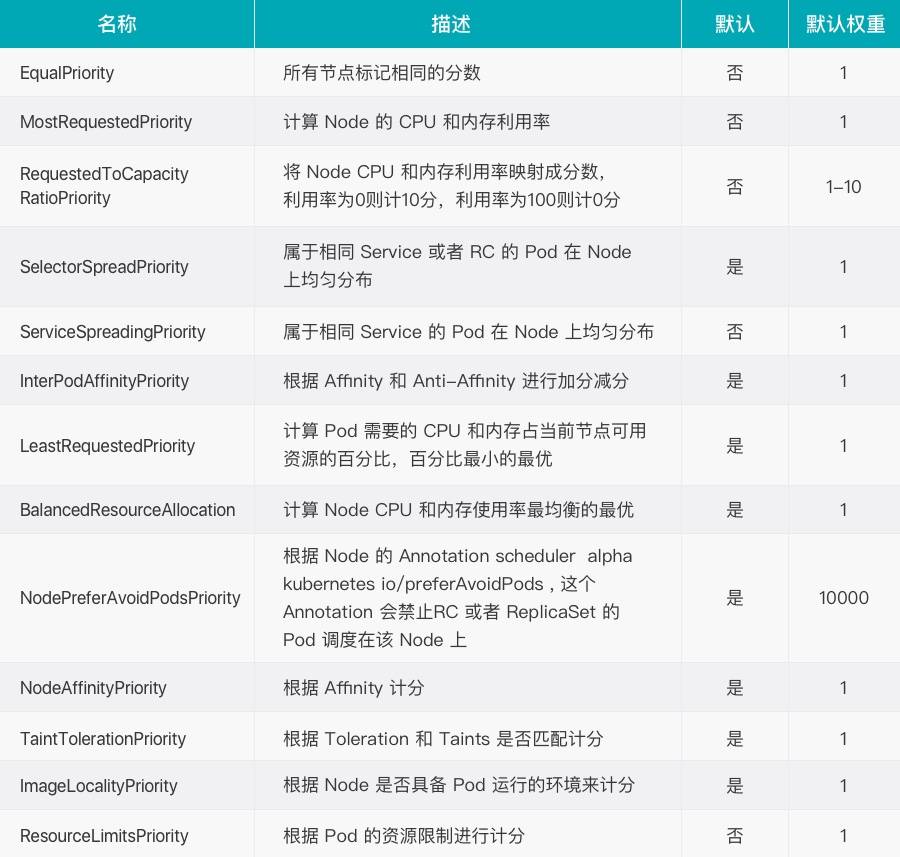
预选策略
优选策略
NodeSelector
官网文档
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/
label是kubernetes中一个非常重要的概念,用户可以非常灵活的利用 label 来管理集群中的资源,POD 的调度可以根据节点的 label 进行特定的部署。
查看节点的label:
kubectl get nodes --show-labels
为节点打label:
$ kubectl label node k8s-master disktype=ssd
当 node 被打上了相关标签后,在调度的时候就可以使用这些标签了,只需要在spec 字段中添加nodeSelector字段,里面是我们需要被调度的节点的 label。
...
spec:
volumes:
- name: mysql-data
hostPath:
path: /opt/mysql/data
nodeSelector: # 使用节点选择器将Pod调度到指定label的节点
mysql: "true"
containers:
- name: mysql
image: mysql:5.7
...
为什么需要学nodeAffinity
机器数量较少的话就别整亲和性了。。
至少几百个节点,需要设置复杂规则时,用亲和性
nodeAffinity和nodeSelector都是用来控制Pod在哪些节点上运行的机制,但它们有一些区别:
- 灵活性:nodeAffinity比nodeSelector更加灵活。nodeSelector只能使用等于操作符进行节点标签匹配,而nodeAffinity支持使用in、notIn、exists、doesNotExist、gt、lt等多种操作符,同时还支持使用节点的资源使用情况、节点的角色、节点的拓扑位置等信息进行选择。
- 粒度:nodeAffinity可以实现更细粒度的控制。nodeSelector只能指定一个或多个节点标签,而nodeAffinity可以通过使用多个节点标签或其他属性来实现更加精确的控制。
- 复杂性:nodeAffinity相对于nodeSelector来说更加复杂。由于其支持更多的操作符和属性,因此需要更多的学习和配置成本。
综上所述,nodeAffinity比nodeSelector更加灵活和精确,但同时也更加复杂。在实际应用中,用户需要根据自己的需求来选择适合自己的节点选择机制。
nodeSelector 和nodeAffinity的区别
nodeSelector 、我要吃红烧排骨、没有我就不吃了。
nodeAffinity、我要吃饭,有红烧排骨优先。。不行就吃其他的吧
nodeAffinity(节点亲和性)
Pod -> Node的标签
Label标签是0和1的关系,行或不行。
而节点亲和性 , 比上面的nodeSelector更加灵活,它可以进行一些简单的逻辑组合,不只是简单的相等匹配 。
硬策略和软策略
requiredDuringSchedulingIgnoredDuringExecution : 硬策略,如果没有满足条件的节点的话,就不断重试直到满足条件为止,简单说就是你必须满足我的要求,不然我就不会调度Pod。
preferredDuringSchedulingIgnoredDuringExecution:软策略,如果你没有满足调度要求的节点的话,Pod就会忽略这条规则,继续完成调度过程,说白了就是满足条件最好了,没有满足就忽略掉的策略。
详细解释
这两个参数是 Kubernetes Pod 中的调度策略字段,它们的作用是指定 Pod 调度时节点的要求。
preferredDuringSchedulingIgnoredDuringExecution表示希望 Pod 能够调度到具有指定标签的节点,但如果没有满足条件的节点也不会阻止 Pod 调度到其他节点。这个参数是一个列表,可以指定多个标签和权重,Kubernetes 将根据权重决定选择哪个节点。如果有多个节点都满足要求,则会随机选择一个节点。requiredDuringSchedulingIgnoredDuringExecution表示 Pod 必须调度到具有指定标签的节点上,否则调度将失败。如果没有满足条件的节点,Pod 将一直处于 Pending 状态。
两个参数的共同点是它们都会被忽略在 Pod 运行时。也就是说,一旦 Pod 被调度到节点上并且开始运行,这两个参数的值将被忽略,不会对运行时产生任何影响。
使用这两个参数可以帮助你控制 Pod 的调度,以便让它们运行在特定的节点上,或者让它们尽可能地均匀地分布在集群中的节点上。
使用案例
要求 Pod 不能运行在k8s-slave1和k8s-slave2两个节点上,如果有节点满足disktype=ssd或者sas的话就优先调度到这类节点上 ...
...
spec:
containers:
- name: eladmin-api
image: 10.0.0.66:5000/eladmin-api:v1
ports:
- containerPort: 8000
affinity:
nodeAffinity:
# 硬策略
# 强制要求,只要label出现如下字符串,就禁止调度。
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- k8s-slave1
- k8s-slave2
# 软策略
# 在所有node上进行判断,如果label有符合是ssd、或者sas优先调度
#
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
- sas
...
该配置中包含一个权重(weight)和一个偏好(preference)。当节点满足偏好条件时,权重越高的节点将优先被选择。
在这个特定的配置中,偏好条件是节点的磁盘类型必须是SSD或SAS。这个偏好使用了matchExpressions的方式进行匹配,即只有当节点的标签中包含disktype且其值为SSD或SAS时,才会被认为是符合条件的。
这里的匹配逻辑是 label 的值在某个列表中,现在Kubernetes提供的操作符有下面的几种:
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
注意
如果nodeSelectorTerms下面有多个选项的话,满足任何一个条件就可以了;
如果matchExpressions有多个选项的话,则必须同时满足这些条件才能正常调度 Pod;
pod亲和性、反亲和性
Pod 亲和性和反亲和性的主要目的是为了帮助 Kubernetes 集群管理员更好地控制 Pod 的调度和部署,从而实现更高的可用性、可靠性和性能。
以下是一些常见的原因和用例:
- 提高可用性和可靠性:Pod 亲和性可以将相关的 Pod 调度到同一节点上,这样可以降低节点故障对应用的影响。同时,反亲和性可以将相关的 Pod 分散到不同的节点上,避免单点故障影响整个应用。
- 改善性能和资源利用率:Pod 亲和性可以将需要共享资源的 Pod 调度到同一节点上,这样可以降低网络延迟和提高吞吐量。同时,反亲和性可以将需要竞争资源的 Pod 分散到不同的节点上,避免资源竞争导致的性能下降。
- 分离敏感数据:Pod 亲和性可以将处理敏感数据的 Pod 调度到同一节点上,避免数据泄露和安全漏洞。同时,反亲和性可以将处理不同数据的 Pod 分散到不同的节点上,避免数据交叉和混淆。
总之,Pod 亲和性和反亲和性是 Kubernetes 集群管理的重要工具,可以帮助管理员更好地管理 Pod 的调度和部署,提高应用的可用性、可靠性和性能。
语法
eladmin-web启动多副本,但是期望可以尽量分散到集群的可用节点中
[root@k8s-master ~]#kubectl -n yuchao get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
eladmin-api-9446bcc45-jrpk4 1/1 Running 0 11d 10.244.0.44 k8s-master <none> <none>
eladmin-api-9446bcc45-mhrmp 1/1 Running 1 (143m ago) 11d 10.244.2.56 k8s-slave1 <none> <none>
eladmin-api-9446bcc45-p5q2r 1/1 Running 0 11d 10.244.2.57 k8s-slave1 <none> <none>
eladmin-api-9446bcc45-pkpjr 1/1 Running 0 11d 10.244.1.39 k8s-slave2 <none> <none>
eladmin-web-95f5dcd64-z9b2n 1/1 Running 0 3d2h 10.244.2.53 k8s-slave1 <none> <none>
mysql-7c7cf8495f-5w5bk 1/1 Running 0 12d 10.244.0.43 k8s-master <none> <none>
ngx-test 1/1 Running 0 2d1h 10.244.1.36 k8s-slave2 <none> <none>
redis-7957d49f44-cxj8z 1/1 Running 0 12d 10.244.1.37 k8s-slave2 <none> <none>
[root@k8s-master ~]#
分析:为了让eladmin-web应用的多个pod尽量分散部署在集群中,可以利用pod的反亲和性,告诉调度器,如果某个节点中存在了eladmin-web的pod,则可以根据实际情况,实现如下调度策略:
不允许同一个node节点,调度两个
eladmin-web的副本(硬策略)
# 如果某个节点中,存在了app=eladmin-web的label的pod,那么 调度器一定不要给我调度过去
...
spec:
affinity:
# pod反亲和性
podAntiAffinity:
# 硬策略
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- eladmin-web
topologyKey: kubernetes.io/hostname
containers:
...
其中,affinity字段用于指定Pod的调度策略,podAntiAffinity表示Pod的反亲和性(即避免与具有某些标签的其他Pod调度到同一个节点上)。
requiredDuringSchedulingIgnoredDuringExecution则表示Pod的反亲和性规则是硬策略(即强制执行),如果违反规则则不会被调度。
在本例中,labelSelector指定了匹配Pod标签的方式,topologyKey表示反亲和性规则应该在节点级别上执行,基于节点的主机名进行匹配。
可以允许同一个node节点中调度两个
eladmin-web的副本,前提是尽量把pod分散部署在集群中(软策略)
这是一段给pod设置的反亲和性
...
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- eladmin-web
topologyKey: kubernetes.io/hostname
containers:
...
# 如果某个节点中,存在了app=eladmin-web的label的pod,那么调度器尽量不要调度过去.
参数解释
- affinity 段定义了 Pod 的亲和性规则。
- 在这个例子中,使用 podAntiAffinity 配置来确保同一节点上不会调度多个具有相同标签的 Pod。
- preferredDuringSchedulingIgnoredDuringExecution 指定了调度器如何偏好调度的 Pod。
- weight 字段指定权重,此处为 100。
- podAffinityTerm 指定了 Pod 亲和性的条件,其中 labelSelector 选择了具有 app=eladmin-web 标签的
- Pod,topologyKey 则指定 Pod 应该在不同主机上分配。
实践软策略
这里的规则是,如果节点上有了eladmin-web的标签,就尽量不会再调取eladmin-api。
[root@k8s-master ~]#kubectl -n yuchao edit deployments.apps eladmin-api
...
30 template:
31 metadata:
32 creationTimestamp: null
33 labels:
34 app: eladmin-api
35 spec:
36 affinity:
37 podAntiAffinity:
38 preferredDuringSchedulingIgnoredDuringExecution:
39 - podAffinityTerm:
40 labelSelector:
41 matchExpressions:
42 - key: app
43 operator: In
44 values:
45 - eladmin-web
46 topologyKey: kubernetes.io/hostname
47 weight: 100
48 containers:
49 - env:
50 - name: DB_HOST
# 看新的pod调度情况
[root@k8s-master ~]#kubectl -n yuchao get po -owide |grep eladmin-api
eladmin-api-79b478cf54-24snm 1/1 Running 0 94s 10.244.1.41 k8s-slave2 <none> <none>
eladmin-api-79b478cf54-m5ntl 1/1 Running 0 94s 10.244.0.46 k8s-master <none> <none>
eladmin-api-79b478cf54-qfwr9 1/1 Running 0 2m5s 10.244.1.40 k8s-slave2 <none> <none>
eladmin-api-79b478cf54-zr9pr 1/1 Running 0 2m5s 10.244.0.45 k8s-master <none> <none>
# 很明显,不会去eladmin-web所在节点部署了
污点Taint、容忍tolerations
污点、理解为坏毛病
你要是不能忍,你就别跟我做朋友
对于nodeAffinity无论是硬策略还是软策略方式,都是调度 Pod 到预期节点上;
而Taints恰好与之相反,如果一个节点标记为 Taints ,除非 Pod 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度Pod。
Taints(污点)是Node的一个属性,设置了Taints(污点)后,因为有了污点,所以Kubernetes是不会将Pod调度到这个Node上的。
还记得初始化安装k8s时,k8s-master有taints而默认不允许调度pos吗。
于是Kubernetes就给Pod设置了个属性Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去。
为什么需要有taints
nodeAffinity 和 taints 是 Kubernetes 中用于调度和管理 Pod 的两个重要概念,它们之间有密切的关系。
NodeAffinity 是用于指定 Pod 调度到哪些节点的策略,可以根据节点的标签和其他属性对节点进行匹配。与之对应的是 PodAffinity 和 PodAntiAffinity,用于指定 Pod 与其他 Pod 之间的调度关系。
Taints 则是用于标记节点的一种机制,它可以阻止一些不希望运行在该节点上的 Pod 调度到该节点上。与之对应的是 Tolerations,用于让某个 Pod 可以容忍某个节点的 Taint。
因此,NodeAffinity 和 Taints 可以结合起来使用,以实现更灵活的 Pod 调度和管理。例如,我们可以为某个节点设置 Taint,表示该节点只能运行特定类型的 Pod,然后使用 NodeAffinity 来指定只有特定的 Pod 能够被调度到该节点上。另外,如果某个 Pod 需要运行在某个被 Taint 标记的节点上,我们可以为该 Pod 设置对应的 Tolerations,以允许它在该节点上运行。
因此,可以说 NodeAffinity 和 Taints 是 Kubernetes 中非常重要的概念,它们可以帮助用户更好地管理和控制 Pod 的调度和运行。
使用taint场景
场景一:私有云服务中,某业务使用GPU进行大规模并行计算。为保证性能,希望确保该业务对服务器的专属性,避免将普通业务调度到部署GPU的服务器。
场景二:用户希望把 Master 节点保留给 Kubernetes 系统组件使用,或者把一组具有特殊资源预留给某些 Pod,则污点就很有用了,Pod 不会再被调度到 taint 标记过的节点。
taint 标记节点举例如下:
设置taints
$ kubectl taint node [node_name] key=value:[effect]
其中[effect] 可取值: [ NoSchedule | PreferNoSchedule | NoExecute ]
NoSchedule:一定不能被调度。
PreferNoSchedule:尽量不要调度。
NoExecute:不仅不会调度,还会驱逐Node上已有的Pod。
在选择这三个策略时,需要考虑以下因素:
节点资源:如果节点资源已经用尽,可以将其标记为 NoSchedule 或 NoExecute,以防止在该节点上调度新的 Pod,或者将现有的 Pod 驱逐出该节点。这样可以保证节点不会过载,从而确保其他 Pod 的可用性和性能。
特殊节点:如果有某些节点具有特殊的限制或需求,可以将其标记为 PreferNoSchedule,以便调度器优先考虑在其他可用节点上调度 Pod。这可以确保这些特殊节点上不会调度太多的 Pod,从而满足它们的限制和需求。
安全性问题:如果节点存在安全性问题,例如存在漏洞或被攻击,可以将其标记为 NoExecute,以避免任何进一步的攻击或数据泄露。在这种情况下,运行在该节点上的所有 Pod 都将被删除,以确保集群的安全性。
因此,在选择这三个策略时,应该考虑节点的资源状况、特殊的限制或需求,以及安全性问题,选择最适合的策略以确保集群的高可用性、资源利用率和安全性。
示例:kubectl taint node k8s-slave1 smoke=true:NoSchedule
去掉污点
去除指定key及其effect:
kubectl taint nodes [node_name] key:[effect]- #这里的key不用指定value
kubectl taint node k8s-slave1 smoke-
去除指定key所有的effect:
kubectl taint nodes node_name key-
示例:
kubectl taint node k8s-master smoke=true:NoSchedule
kubectl taint node k8s-master smoke:NoExecute-
kubectl taint node k8s-master smoke-
实战污点玩法
## 给k8s-slave1打上污点,smoke=true:NoSchedule
$ kubectl taint node k8s-master gamble=true:NoSchedule
$ kubectl taint node k8s-slave1 drunk=true:NoSchedule
$ kubectl taint node k8s-slave2 smoke=true:NoSchedule
## 扩容eladmin-web的Pod,观察新Pod的调度情况
$ kubectl -n yuchao scale deploy eladmin-web --replicas=0
$ kubectl -n yuchao scale deploy eladmin-web --replicas=1
[root@k8s-master ~]#kubectl -n yuchao get po |grep web
eladmin-web-95f5dcd64-t9mg9 0/1 Pending 0 25s
# 为什么?
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 39s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {drunk: true}, 1 node(s) had untolerated taint {gamble: true}, 1 node(s) had untolerated taint {smoke: true}. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.
[root@k8s-master ~]#kubectl -n yuchao describe po eladmin-web-95f5dcd64-t9mg9
# 3个节点,都有污点(坏习惯、抽烟、喝酒、赌博、)
# 并且你这个pod没有提前说,你能容忍这些污点,所以就拒绝做朋友!!!
# 除非你能容忍他这个污点
pod加上容忍
[root@k8s-master ~]#kubectl -n yuchao edit deployments.apps eladmin-web
deployment.apps/eladmin-web edited
...
spec:
containers:
- name: eladmin-web
image: 10.0.0.66:5000/eladmin/eladmin-web:v2
tolerations: #设置容忍性
- key: "smoke"
operator: "Equal" #不指定operator,默认为Equal
value: "true"
effect: "NoSchedule"
- key: "drunk"
operator: "Exists"
# 如果操作符为Exists,那么value属性可省略,不指定operator,默认为Equal
# 允许你喝酒,值是什么随意,都容忍了
# 意思是这个Pod要容忍的有污点的Node的key是smoke Equal true,效果是NoSchedule,
# tolerations属性下各值必须使用引号,容忍的值都是设置Node的taints时给的值。
# 这里是一个比较全的案例,等于你想找对象,容忍了抽烟、喝酒,两个坏习惯。
继续查看刚才的pod这一次是成功调度了,以及查看pod的容忍有哪些
Tolerations: drunk op=Exists # 只要有这个drunk污点,就容忍
node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
smoke=true:NoSchedule
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 36s default-scheduler Successfully assigned yuchao/eladmin-web-759f77b7cb-v7bpw to k8s-slave1
Normal Pulled 36s kubelet Container image "10.0.0.66:5000/eladmin/eladmin-web:v5" already present on machine
Normal Created 36s kubelet Created container eladmin-web
Normal Started 36s kubelet Started container eladmin-web
[root@k8s-master ~]#
[root@k8s-master ~]#kubectl -n yuchao describe po eladmin-web-759f77b7cb-v7bpw
drunk op=Exists:表示 Pod 可以被调度到一个被标记为 "drunk" 的节点上,"op=Exists" 表示只要这个污点存在就允许调度。node.kubernetes.io/not-ready:NoExecute op=Exists for 300s:表示 Pod 可以被调度到一个被标记为 "not-ready" 的节点上,"NoExecute" 表示该污点标记的节点上的 Pod 会被驱逐(Eviction),"op=Exists for 300s" 表示只有该污点存在 300 秒以上时才允许调度。node.kubernetes.io/unreachable:NoExecute op=Exists for 300s:表示 Pod 可以被调度到一个被标记为 "unreachable" 的节点上,同样 "NoExecute" 表示该污点标记的节点上的 Pod 会被驱逐,"op=Exists for 300s" 表示只有该污点存在 300 秒以上时才允许调度。smoke=true:NoSchedule:表示 Pod 可以被调度到一个被标记为 "smoke=true" 的节点上,"NoSchedule" 表示该污点标记的节点上不会再调度新的 Pod,只会等待现有 Pod 的终止或迁移。
容忍所有的污点(最大接受度)
spec:
containers:
- name: eladmin-web
image: 10.0.0.66:5000/eladmin/eladmin-web:v2
tolerations:
- operator: "Exists"
# 这段意思是,随你是什么污点,只要有,就容忍
有一个内置的组件,就是容忍所有污点,都可以调度
QoS Class: BestEffort
Node-Selectors: kubernetes.io/os=linux
Tolerations: op=Exists
node.kubernetes.io/disk-pressure:NoSchedule op=Exists
node.kubernetes.io/memory-pressure:NoSchedule op=Exists
node.kubernetes.io/network-unavailable:NoSchedule op=Exists
node.kubernetes.io/not-ready:NoExecute op=Exists
node.kubernetes.io/pid-pressure:NoSchedule op=Exists
node.kubernetes.io/unreachable:NoExecute op=Exists
node.kubernetes.io/unschedulable:NoSchedule op=Exists
Events: <none>
[root@k8s-master ~]#kubectl -n kube-system describe pod kube-proxy-np8rb
# 或者导出pod-yaml也可以看到容忍
[root@k8s-master ~]#kubectl -n kube-system get pod kube-proxy-np8rb -oyaml
去掉污点
[root@k8s-master ~]#kubectl describe no k8s-master |grep -i taint
Taints: gamble=true:NoSchedule
[root@k8s-master ~]#kubectl taint node k8s-master gamble-
node/k8s-master untainted
[root@k8s-master ~]#kubectl describe no k8s-slave1 |grep -i taint
Taints: drunk=true:NoSchedule
[root@k8s-master ~]#
[root@k8s-master ~]#kubectl taint node k8s-slave1 drunk=true:NoSchedule-
node/k8s-slave1 untainted
[root@k8s-master ~]#kubectl taint node k8s-slave2 smoke-
node/k8s-slave2 untainted
cordon/drain
在Kubernetes中,cordon和drain是管理节点的两个命令。
cordon 标记不可用
drain 驱逐所有pod
cordon命令可以将节点标记为不可调度,这意味着Kubernetes调度器将不会将新的Pod调度到该节点上。但是该节点上已经运行的Pod不会被删除或迁移。
这个命令可以用于维护节点或者在节点出现问题时限制节点的使用。
drain命令则更加彻底,它除了标记节点为不可调度外,还会删除该节点上的所有Pod。这个命令通常用于将节点从集群中移除,以便进行维护或升级操作。
当我们需要对某个节点进行维护或者更新操作时,我们可以使用cordon命令将该节点标记为不可调度,等待该节点上的Pod自然结束或者迁移至其他节点。
在所有Pod都已经迁移后,我们可以使用drain命令来删除该节点上的所有Pod,然后进行节点维护操作。
需要注意的是,使用cordon和drain命令时,我们需要确保该节点上的Pod已经有备份,以便在需要时能够恢复。
# 等于给你机器,加上污点,就默认不允许调度了
$ kubectl cordon k8s-slave1
# cordon就等于用taint命令,加上一个污点
[root@k8s-master ~]#kubectl describe no k8s-slave1 |grep -i taint
Taints: node.kubernetes.io/unschedulable:NoSchedule
[root@k8s-master ~]#kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ngx01 1/1 Running 3 (8m51s ago) 11d 10.244.0.51 k8s-master <none> <none>
ngx1 1/1 Running 4 (8m54s ago) 22d 10.244.2.59 k8s-slave1 <none> <none>
test-nginx 1/1 Running 4 (8m54s ago) 24d 10.244.2.61 k8s-slave1 <none> <none>
[root@k8s-master ~]#
# 驱逐节点上所有pod,默认会驱逐失败,因为不允许直接干掉daemonset的pod
$ kubectl drain k8s-slave1
$ kubectl drain k8s-slave1 --force --ignore-daemonsets
# 检查所有机器的pod,会发现普通pod都被删除了,忽略了daemonsets的pod
[root@k8s-master ~]#kubectl get po -A -owide|grep k8s-slave1
kube-flannel kube-flannel-ds-gs9dt 1/1 Running 4 (120m ago) 24d 10.0.0.81 k8s-slave1 <none> <none>
kube-system kube-proxy-np8rb 1/1 Running 3 (120m ago) 12d 10.0.0.81 k8s-slave1 <none> <none>
[root@k8s-master ~]#
# drain是包含cordon的污点操作的
# 没有撤销动作,需要撤销cordon
[root@k8s-master ~]#kubectl uncordon k8s-slave1
node/k8s-slave1 uncordoned
[root@k8s-master ~]#
[root@k8s-master ~]#kubectl describe no k8s-slave1 |grep -i taint
Taints: <none>
pod驱逐策略
pod驱逐解释
Pod驱逐(Pod Eviction)是指Kubernetes集群自动删除节点上运行的Pod的过程。Pod驱逐策略是指在何种情况下Kubernetes集群会自动驱逐Pod。
Pod驱逐策略通常与节点维护(Node Maintenance)相关。当需要对某个节点进行维护或升级时,需要将该节点上运行的Pod驱逐到其他节点上,以保证服务的高可用性。
Pod驱逐策略可以由用户指定,也可以由Kubernetes集群自动计算。用户可以通过PodDisruptionBudget对象来指定Pod的最小可用性要求,并且可以设置Pod的驱逐顺序、驱逐时间等参数。
Kubernetes集群自动计算Pod驱逐策略的方式是通过考虑Pod的调度约束、副本数、节点资源负载情况等因素,来确定哪些Pod需要被驱逐。
当需要驱逐Pod时,Kubernetes会先尝试进行Graceful Termination,即向Pod发送SIGTERM信号,让Pod自行清理工作并停止服务。
如果在一定时间内Pod仍未停止,则Kubernetes会强制终止Pod,并在其他节点上重新调度该Pod的副本。
故障场景
k8s是如何处理你的node节点,突然关机,上面的pod如何迁移的?
K8S 有个特色功能叫 pod eviction,它在某些场景下如节点 NotReady,或者资源不足时,把 pod 驱逐至其它节点,这也是出于业务保护的角度去考虑的。
- Kube-controller-manager: 周期性检查所有节点状态,当节点处于 NotReady 状态超过一段时间后,驱逐该节点上所有 pod。
pod-eviction-timeout:NotReady 状态节点超过该时间后,执行驱逐,默认 5 min,适用于k8s 1.13版本之前- 1.13版本后,集群开启
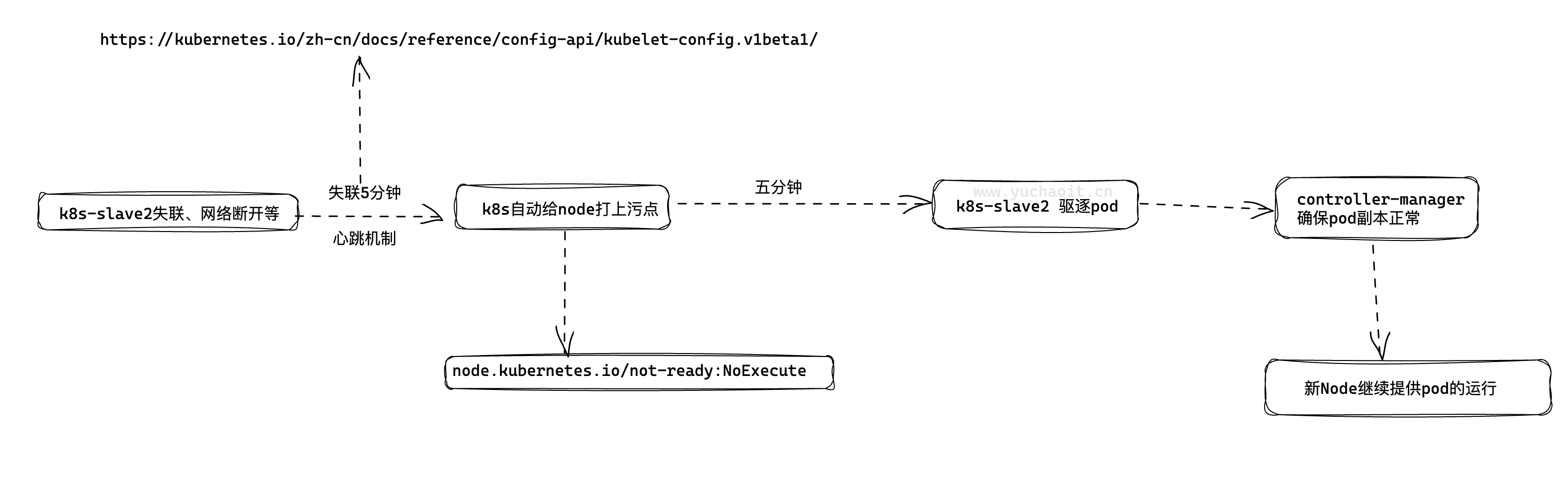
TaintBasedEvictions 与TaintNodesByCondition功能,即taint-based-evictions,即节点若失联或者出现各种异常情况,k8s会自动为node打上污点,同时为pod默认添加如下容忍设置:
TaintBasedEvictions(基于Taint的驱逐)和pod-eviction-timeout(Pod驱逐超时)都是Kubernetes中与Pod驱逐相关的概念。
TaintBasedEvictions是一种Pod驱逐策略,它基于节点的Taint设置来决定哪些Pod可以被驱逐。节点的Taint是一种标记,用于标识该节点是否允许运行一定类型的Pod。当节点需要被维护或升级时,管理员可以通过设置Taint来通知Kubernetes集群驱逐该节点上运行的一些Pod,以便在节点维护期间保持服务的高可用性。
pod-eviction-timeout是指在驱逐Pod时,Kubernetes等待Pod停止的最长时间。如果Pod在该时间内未能停止,则Kubernetes会强制终止Pod并进行重新调度。默认情况下,Pod驱逐超时时间是5分钟。
这两个概念之间的关系是:在TaintBasedEvictions策略中,如果节点上有一个Pod被标记为不可驱逐(例如Pod的PodDisruptionBudget对象设置了最小可用性),那么Pod-eviction-timeout参数将被忽略,Pod将不会被驱逐,以保证集群的最小可用性要求。否则,Pod将按照pod-eviction-timeout参数指定的时间进行Graceful Termination,并在超时后被强制终止和重新调度。
查看pod默认容忍
在 Kubernetes 中,当节点不可用或者不适合调度 Pod 时,Pod 会被调度器(Scheduler)拒绝调度。但是,在某些情况下,调度器拒绝调度一个 Pod 并不意味着该 Pod 无法在该节点上运行。例如,节点可能会因为维护或升级等原因暂时不可用,但是这种情况只是暂时的,节点很快就会恢复正常。
为了避免因为节点暂时不可用而频繁地调度 Pod,Kubernetes 允许在 Pod 中设置 tolerations 字段,来容忍一些特定的节点问题,例如节点不可用或者不稳定。其中 tolerationSeconds 字段可以设置容忍的时间(单位:秒)。如果节点的状态在容忍时间内得到了修复,Pod 就可以在该节点上运行,否则该 Pod 将被删除。
在这个例子中,tolerations 字段中的 tolerationSeconds: 300 表示 Pod 在节点不可用或者不稳定的情况下,可以容忍 300 秒。在这 300 秒内,如果节点状态得到修复,Pod 就可以在该节点上运行;否则该 Pod 将被删除。
这种容忍机制可以确保 Kubernetes 集群的稳定性和可用性。例如,当节点因为网络故障或其他原因暂时不可用时,容忍机制可以保证 Pod 不会频繁地被调度到不可用的节点上,从而提高应用程序的稳定性和可靠性。
[root@k8s-master ~]#kubectl -n yuchao get po ngx-test -oyaml
...
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
k8s会给pod默认的加上容忍时间300秒,是因为防止机器的断网问题,宕机问题,超过300秒,立马被驱逐走;
留下五分钟时间,允许你的机器恢复正常
如果五分钟后,这台机器,还是有污点,pod就会被驱逐。
默认情况下,Kubernetes创建的Pod会自动添加一些容忍度(tolerations),这是因为Kubernetes集群中的Node节点可能会出现故障或者维护,此时Pod可能会被调度到其他节点上,而这个过程可能会导致Pod的部分或者全部容器在短时间内无法正常工作。
容忍度的作用就是告诉Kubernetes调度器,允许Pod在某些特定的情况下继续运行,例如节点不可用、节点处于未就绪状态等。这可以保证Pod的高可用性和稳定性。
在上面提供的配置信息中,tolerations的作用是容忍节点处于不可用或者未就绪状态的情况,tolerationSeconds参数表示节点可以在这段时间内不可用或者未就绪。
在实际的生产环境中,tolerations的配置需要根据具体的应用场景和业务需求进行调整。
图解

即各pod可以独立设置驱逐容忍时间。
kubelet巡检
Kubelet: 周期性检查本节点资源,当资源不足时,按照优先级驱逐部分 pod
Kubernetes 中的 kubelet 组件负责管理每个节点上的容器,并与 API 服务器交互以接收 Pod 调度信息并报告节点的状态。为了确保节点的健康和稳定性,kubelet 组件需要定期对节点进行巡检,并向 Kubernetes API 服务器报告节点的资源使用情况和可用性。
在巡检期间,kubelet 会检查节点的各种资源,包括内存、存储空间和 inodes 等。具体来说,以下是一些常见的 kubelet 巡检项及其含义:
memory.available:节点可用内存,表示节点上未被占用的内存空间。nodefs.available:节点根盘可用存储空间,表示节点上根目录挂载的文件系统中未被占用的存储空间。nodefs.inodesFree:节点 inodes 可用数量,表示节点上根目录挂载的文件系统中未被占用的 inodes 数量。imagefs.available:镜像存储盘的可用空间,表示节点上 Docker 镜像存储目录中未被占用的存储空间。imagefs.inodesFree:镜像存储盘的 inodes 可用数量,表示节点上 Docker 镜像存储目录中未被占用的 inodes 数量。
通过对这些巡检项进行监控和报告,kubelet 可以帮助 Kubernetes 集群管理员了解节点的资源使用情况和健康状态,及时发现和解决潜在的问题,确保集群的稳定性和可用性。
/var/lib/containerd/
如磁盘超过80%,判断节点不可用。
回顾k8s调度
Kubernetes (k8s) Scheduler是一种重要的组件,它负责将Pods调度到合适的节点上运行。下面是Kubernetes Scheduler的用法总结:
- 默认情况下,Kubernetes Scheduler会尝试将Pods均匀地分配到可用的节点上,以保持集群的负载均衡。
- 如果您想将Pods调度到特定的节点上运行,可以通过为Pods设置节点选择器或节点亲和性规则来实现。
- 您还可以为Pods设置Pod优先级和调度期限,以确保高优先级的Pods尽快被调度,并在规定时间内完成调度。
- 如果您想要在节点上运行特定类型的工作负载,可以使用节点标签和Pod亲和性规则来实现。
- 您还可以自定义调度程序来实现更高级的调度策略,如优化资源利用率和降低资源浪费。
- Kubernetes Scheduler还支持预选和扩展,可以使用它们来扩展调度器的功能,并将自定义调度器集成到集群中。
总之,Kubernetes Scheduler是Kubernetes集群中一个非常重要的组件,可以根据不同的需求配置它的调度策略,以最大程度地提高集群的效率和性能。