集群网络原理
如下的流程,是当你已经基本会用k8s创建pod、以及使用IP地址之后。
学习背后的创建pod、分配IP的流程,当出现问题后,可以有思路排查网络相关配置文件。
如下是官网资料查询而来、也是固定的用法,反复阅读、理解流程即可。
如果没学过计算机网络,忽略本章节知识点。
如果说你初学k8s、这部分知识,不太理解也不影响部署的学习。
为什么要学集群网络原理
Kubernetes(简称K8s)是一个开源的容器编排系统,它可以帮助开发人员自动部署、扩展和管理容器化应用程序。在Kubernetes集群中,网络是一个非常重要的组成部分,它负责将容器连接起来,使它们可以相互通信。
学习Kubernetes集群网络有以下几个原因:
- 网络是Kubernetes集群的核心组件之一,理解Kubernetes网络可以帮助您更好地了解Kubernetes集群的工作原理。
- 学习Kubernetes集群网络可以帮助您识别和解决Kubernetes网络问题。在Kubernetes集群中,网络问题可能会导致应用程序无法正常工作,因此了解如何诊断和解决这些问题至关重要。
- Kubernetes网络具有一些独特的特性,例如负载均衡、服务发现和网络策略等,学习这些特性可以帮助您更好地利用Kubernetes的优势。
- 最后,学习Kubernetes集群网络可以帮助您更好地理解容器网络。Kubernetes网络使用容器网络技术来连接容器,了解这些技术可以帮助您更好地管理和部署容器化应用程序。
因此,学习Kubernetes集群网络是成为一名优秀的Kubernetes开发人员或运维人员的必备技能之一。
学习Kubernetes集群网络,您需要掌握以下知识点:
- Kubernetes网络模型:了解Kubernetes网络模型及其组件,包括节点网络、Pod网络、服务网络和集群网络。
- 容器网络接口(CNI):了解CNI规范以及CNI插件的作用和实现原理,CNI插件是Kubernetes集群网络的核心组件之一。
- 容器网络:了解常用的容器网络技术,例如flannel、Calico、Weave Net等,它们可以用于实现Kubernetes集群网络。
- 服务发现:了解Kubernetes如何实现服务发现,包括DNS和Kubernetes服务发现机制。
- 负载均衡:了解Kubernetes集群中负载均衡的原理和实现方式。
- 网络策略:了解Kubernetes网络策略的作用和实现原理,以及如何使用它来控制网络流量。
- 网络安全:了解如何保护Kubernetes集群网络的安全,包括网络隔离、访问控制和安全加密等。
- 故障排除:了解如何诊断和解决Kubernetes集群网络故障,包括网络连接问题、DNS问题和负载均衡问题等。
https://kubernetes.io/zh-cn/docs/concepts/cluster-administration/networking/
回顾docker网络
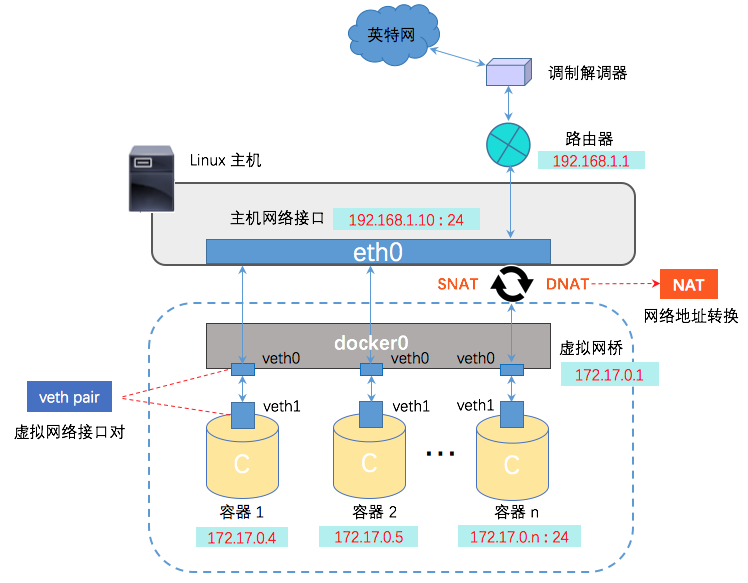
Docker 创建一个容器的时候,会执行如下操作:
- 创建一对虚拟接口/网卡,也就是veth pair;
- veth pair的一端桥接 到默认的 docker0 或指定网桥上,并具有一个唯一的名字,如 vethxxxxxx;
- veth pair的另一端放到新启动的容器内部,并修改名字作为 eth0,这个网卡/接口只在容器的命名空间可见;
- 从网桥可用地址段中(也就是与该bridge对应的network)获取一个空闲地址分配给容器的 eth0
- 配置容器的默认路由
k8s如何保障pod的唯一IP
无类别域间路由(英語:Classless Inter-Domain Routing,簡稱CIDR)是一个用于给用户分配IP地址以及在互联网上有效地路由IP数据包的对IP地址进行归类的方法。
Kubernetes网络模型的核心要求之一是每个Pod应该获得自己的IP地址,如何实现?
Kubernetes网络模型中的核心要求之一是为每个Pod分配一个独立的IP地址,以实现Pod之间的通信和负载均衡。为了实现这一点,Kubernetes采用了多种网络解决方案,其中最常见的是CNI插件。
CNI插件是一种通用的网络接口,用于在Kubernetes中为Pod分配IP地址。它可以与各种不同类型的网络实现集成,例如Overlay网络和物理网络等。当Pod启动时,CNI插件会被调用,为该Pod分配一个唯一的IP地址,并配置该Pod的网络设置,以确保它可以与其他Pod和外部网络通信。
集群默认设置的ip网段
kube-controller-manager 是 Kubernetes 控制平面的一个组件,它管理各种控制器,自动化集群中的不同任务。它负责维护集群的期望状态,确保集群的实际状态与期望状态相匹配。
kube-controller-manager 运行几个内置控制器,包括:
- 节点控制器:监视集群中每个节点的状态,如果节点关闭或变得无法访问,则采取行动。
- 副本控制器:确保在任何时候都有指定数量的 pod 副本在运行。
- Endpoints 控制器:基于集群的当前状态填充 Endpoints 对象(包含正在运行的 pod 的 IP 地址和端口)。
- Service Account 和 Token 控制器:为 pod 创建默认帐户和访问令牌。
在 Kubernetes 集群中,kube-controller-manager 是一个必不可少的组件,它自动化了很多日常管理任务,并确保集群的稳定性和高可用性。
# 查看kube-controller-manager 配置文件
[root@k8s-master /k8s-mysql]#cat /etc/kubernetes/manifests/kube-controller-manager.yaml |grep cidr
- --allocate-node-cidrs=true
- --cluster-cidr=10.244.0.0/16 # kubeadm初始化时指定的网段
# 当初于超老师设置的kubeadm.yaml
[root@k8s-master ~]#cat kubeadm.yaml |grep -i subnet
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
这是一个kubectl命令在Kubernetes集群的Master节点上执行的输出结果,它查找了kube-controller-manager Pod的配置文件kube-controller-manager.yaml,并使用grep命令在该文件中查找了包含cidr关键字的行。
在这个输出中,我们可以看到kube-controller-manager启动参数中有两个与cidr相关的选项:
- --allocate-node-cidrs=true:启用了为Pod分配CIDR地址的功能,这样每个Pod都可以拥有一个唯一的IP地址。
- --cluster-cidr=10.244.0.0/16:指定了Kubernetes集群中使用的CIDR地址池,该地址池用于分配给Pod和Service。
这些参数都与Kubernetes网络模型相关。为每个Pod分配一个唯一的IP地址,并确保Pod可以相互通信和与外部网络通信,是Kubernetes网络模型的核心要求之一。
node可用的ip网段
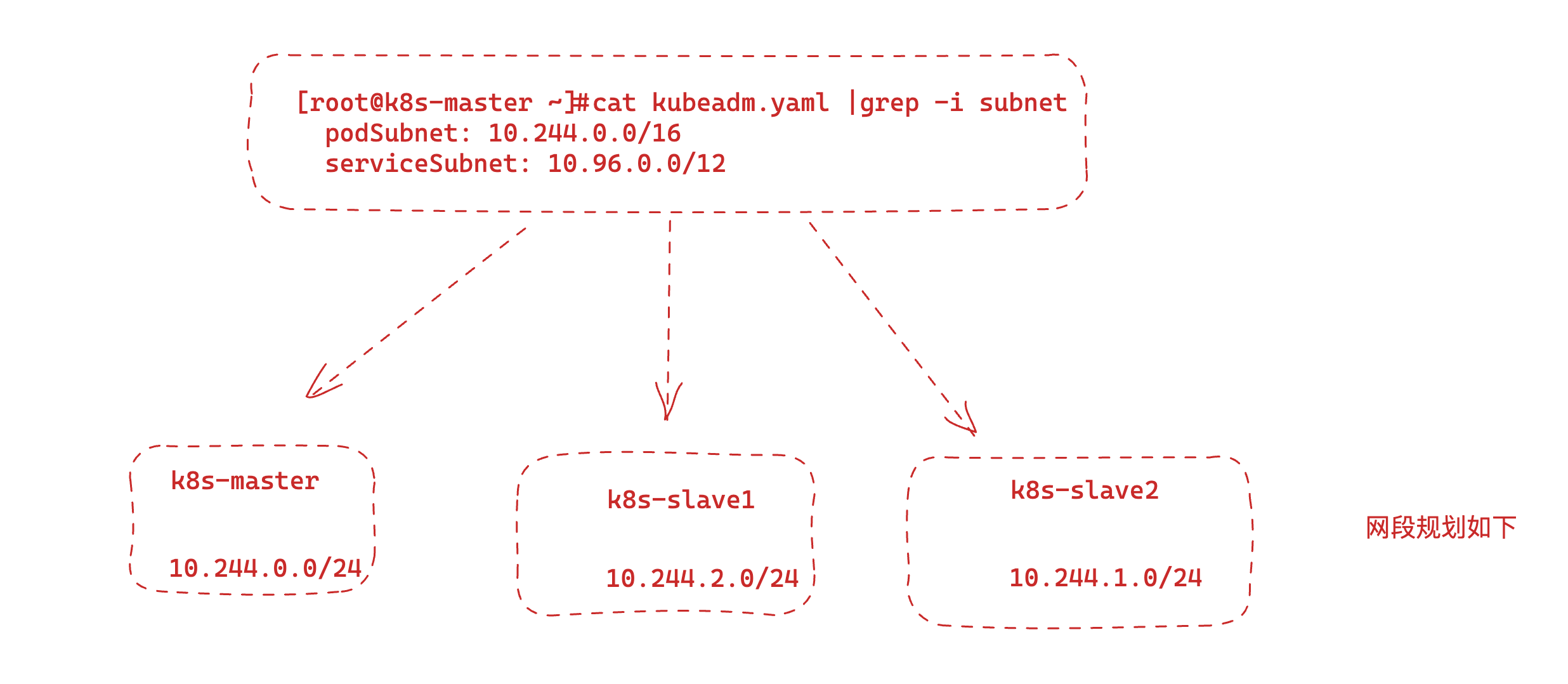
# k8s为每个节点从cidr中分配一个网段,供该节点分配pod ip
[root@k8s-master /k8s-mysql]#kubectl describe node k8s-slave1 |grep -i cidr
PodCIDR: 10.244.2.0/24
PodCIDRs: 10.244.2.0/24
[root@k8s-master /k8s-mysql]#kubectl describe node k8s-slave2 |grep -i cidr
PodCIDR: 10.244.1.0/24
PodCIDRs: 10.244.1.0/24
[root@k8s-master /k8s-mysql]#kubectl describe node k8s-master |grep -i cidr
PodCIDR: 10.244.0.0/24
PodCIDRs: 10.244.0.0/24
这是一个kubectl命令在Kubernetes集群的Master节点上执行的输出结果,它使用describe命令查看名为k8s-slave1的Node节点的详细信息,并使用grep命令过滤包含cidr关键字的行。
在这个输出中,我们可以看到该节点上的两个CIDR地址:
- PodCIDR: 10.244.2.0/24:该节点上分配给Pod的CIDR地址范围。这个CIDR地址池是从Master节点上指定的--cluster-cidr参数中分配的。
- PodCIDRs: 10.244.2.0/24:该节点上分配给Pod的CIDR地址范围的列表。如果有多个CIDR地址池被分配给该节点,则会出现多个条目。
这些CIDR地址用于分配给Pod的IP地址。在Kubernetes集群中,每个节点上运行的Pod都会被分配一个唯一的IP地址,这个IP地址位于该节点的CIDR地址池中。
这样,每个Pod都可以拥有一个唯一的IP地址,并且可以相互通信和与外部网络通信。
是谁去配置pod的网络?
思考:谁来配置Pod网络?当Pod调度到 k8s-slave1节点后,网络的配置流程是怎样
在Kubernetes中,Pod网络的配置是由CNI(Container Network Interface)插件负责的。CNI插件是一组标准化的网络接口,它可以与各种容器运行时进行交互,并为Pod分配IP地址和配置网络。Kubernetes中支持多种CNI插件,例如Calico、Flannel、Weave等。
当一个Pod调度到k8s-slave1节点上时,CNI插件会自动在该节点上启动,并分配一个唯一的IP地址给这个Pod。具体的网络配置流程如下:
- 当一个Pod被调度到k8s-slave1节点上时,Kubernetes会向CNI插件发出一个网络配置请求。
- CNI插件会检查该节点上已经存在的网络配置,并为新的Pod分配一个唯一的IP地址。
- CNI插件会为该Pod配置网络,例如设置路由规则和防火墙规则,以确保该Pod可以与其他Pod和外部网络通信。
- CNI插件将网络配置信息返回给Kubernetes,Kubernetes将该信息存储在etcd中,以供其他Pod和Service使用。
总的来说,Kubernetes网络模型是一个高度自动化的系统,它可以自动配置Pod的网络,并确保Pod之间可以相互通信和与外部网络通信。CNI插件是这个模型中不可或缺的一部分,它负责将Kubernetes的网络策略转化为实际的网络配置。
pod配置网络流程
CNI:容器网络接口(Container Network Interface), 主要能力是对接 Kubelet 完成容器网卡的创建,申请和设置 ip 地址,路由设置,网关设置,实现kubernetes集群的Pod网络通信及管理。
CNI的具体实现有很多种:
- 通用类型:flannel、calico、Cilium 等,部署使用简单
- 其他:根据具体的网络环境及网络需求选择,比如
- 公有云机器,可以选择厂商与网络插件的定制Backend,如AWS、阿里、腾讯针对flannel均有自己的插件,也有AWS ECS CNI
- 私有云厂商,比如Vmware NSX-T等
- 网络性能等,MacVlan
k8s本身不提供cni的实现,因此安装完k8s集群后,需要单独安装网络组件。
怎么理解接口?interface
好比你笔记本,默认不提供鼠标,但是提供了USB接口,你可以用符合该USB规范的有线鼠标,给这个笔记本加上个鼠标功能!
pod调度流程
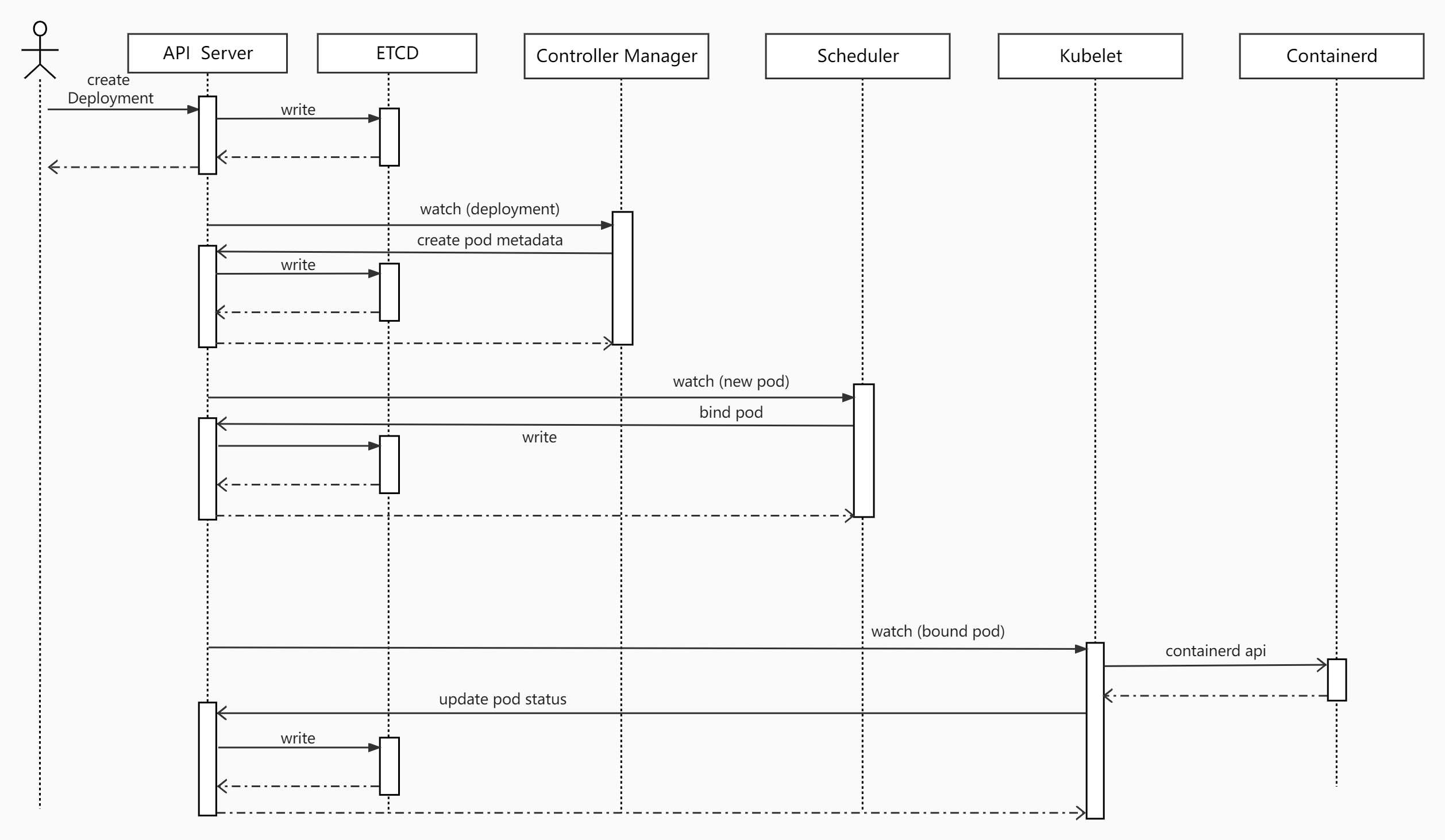
pod网络配置流程(反复阅读即可)
pod调度到目标机器之后,它如何自动设置的一个唯一IP?
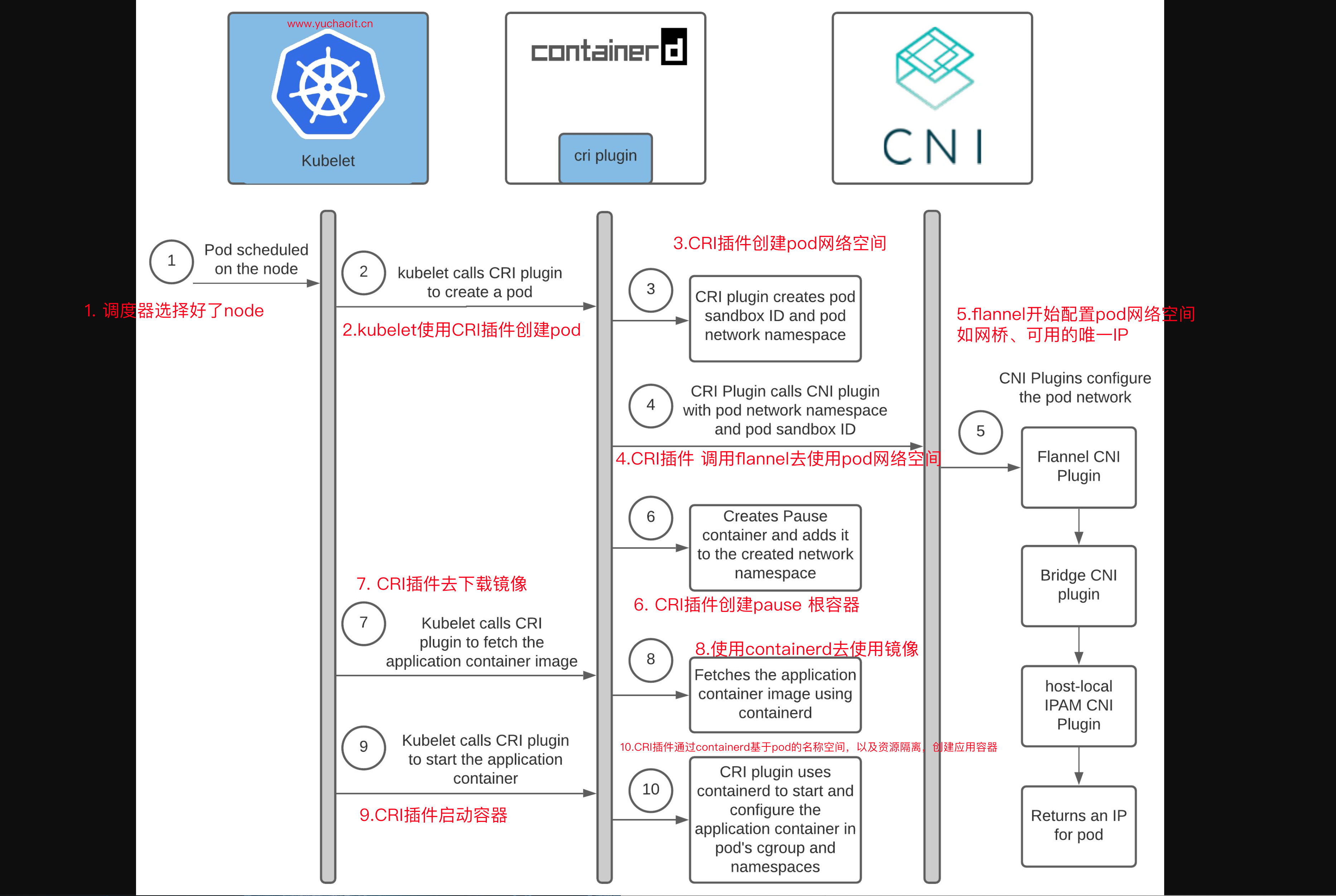
文字理解
- Pod调度到k8s的节点k8s-slave1中
- slave1的kubelet调用containerd创建Pod
- containerd创建Pod沙箱和pod所用的网络空间
- containerd查找配置目录
/etc/cni/net.d/,发现10-flannel.conflist,使用flannel作为网络插件。 - CNI开始为Pod配置网络
- flannel启动时候,写入了本机配置文件
/run/flannel/subnet.env - flannel将本机网段等信息传递给bridge插件
- bridge插件创建cni0网桥
- 创建veth pair,分别接入到pod网络空间和cni0网桥
- 调用 本地IPAM(自动管理IP地址的工具) CNI 插件,设置pod ip地址并记录已分配地址
- IPAM CNI 插件 从子网返回容器的IP地址,并将分配的IP本地存储在主机上
/var/lib/cni/networks/cbr0/
- flannel启动时候,写入了本机配置文件
- containerd创建pause容器,并配置到新建的网络空间
- kubelet调用containerd开始拉取业务镜像
- 启动业务容器并设置namespace和cgroup
学习小结
- kubelet、containerd、cni的工作边界和职责
- cni是被containerd进行调用,cni的实现是可以根据不同的网络环境配置的
- 配置Pod网络的过程,实际上是一个网络工具的链式调用
containerd怎么选择的插件
/etc/cni/net.d 是一个目录,它通常用于存储 CNI (Container Network Interface) 插件的配置文件。CNI 是一个开放的标准,它定义了容器网络接口,使容器运行时能够与网络插件进行交互,从而为容器提供网络连接。
在 /etc/cni/net.d 目录中,每个文件对应一个 CNI 插件的配置文件,其中包含该插件的配置信息,例如网络配置和 IP 地址分配等。在容器启动时,容器运行时会根据容器的配置文件中指定的 CNI 插件配置文件的路径,查找对应的插件配置文件,并将其加载到容器中,以提供网络连接。
因此,/etc/cni/net.d 目录对于容器的网络连接至关重要,如果需要配置容器的网络连接,需要修改或添加相应的配置文件到该目录中。
[root@k8s-master /etc/containerd]#cat config.toml |grep -A 5 'plugins."io.containerd.grpc.v1.cri".cni'
[plugins."io.containerd.grpc.v1.cri".cni]
bin_dir = "/opt/cni/bin"
conf_dir = "/etc/cni/net.d"
conf_template = ""
ip_pref = ""
max_conf_num = 1
[root@k8s-master /etc/containerd]#cd /etc/cni/net.d
[root@k8s-master /etc/cni/net.d]#ls
10-flannel.conflist
[root@k8s-master /etc/cni/net.d]#cat 10-flannel.conflist
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
# flannel部署在每一个节点上,并且自动写了一个配置文件,定义pod的网段
# 三个节点都有、cat /run/flannel/subnet.env
# containerd如何找到的flannel插件、命令?
[root@k8s-master /etc/containerd]#cat config.toml |grep -A 5 bin_dir
bin_dir = "/opt/cni/bin"
conf_dir = "/etc/cni/net.d"
conf_template = ""
ip_pref = ""
max_conf_num = 1
# containerd发现集群插件是flannel后,就去这里找命令且执行
[root@k8s-master /etc/containerd]#ls /opt/cni/bin
bandwidth bridge dhcp dummy firewall flannel host-device host-local ipvlan loopback macvlan portmap ptp sbr static tuning vlan vrf
# flannel又去执行bridge命令
# bridge命令,就是具体给容器创建虚拟网络接口了

更详细理解flannel创建网络的流程
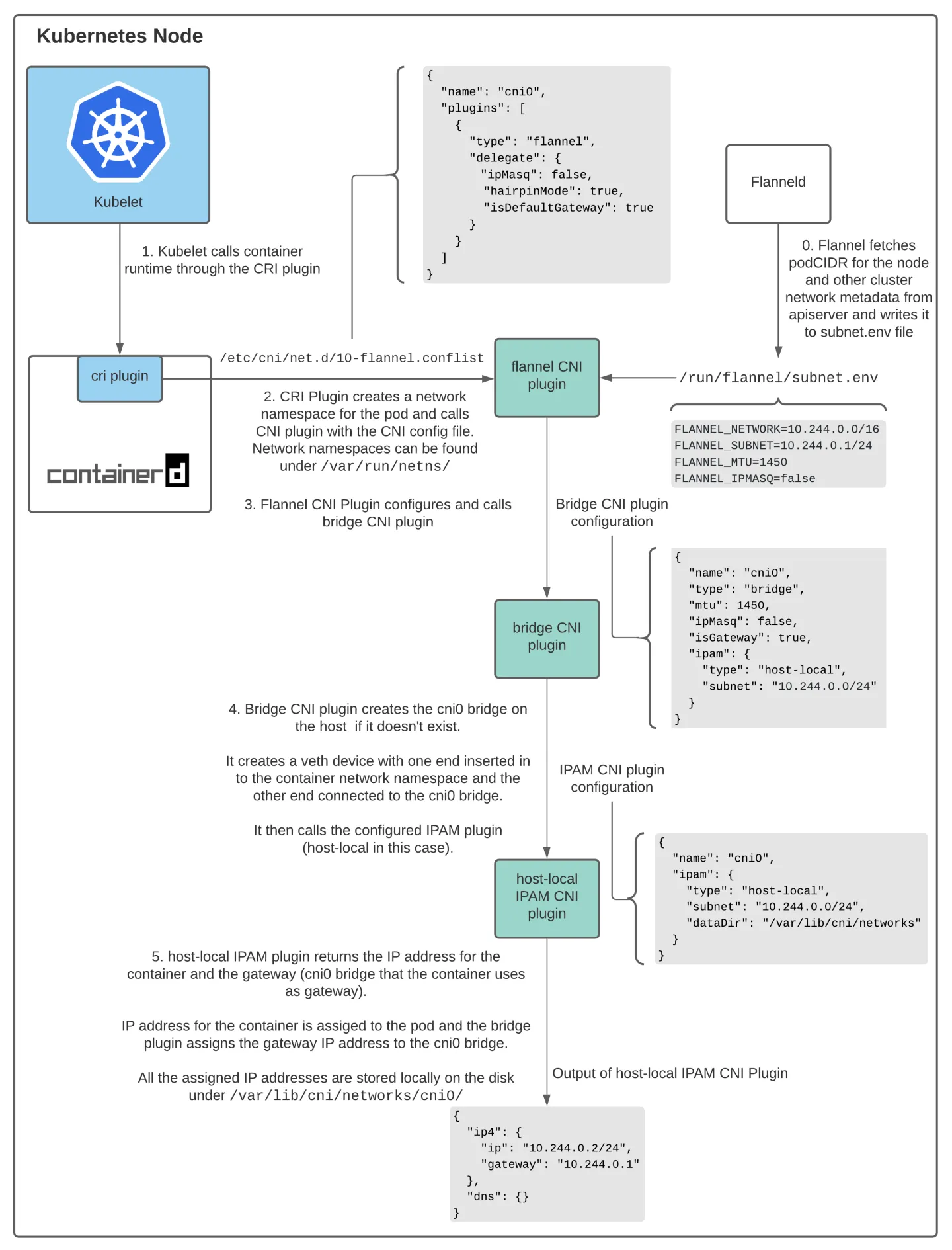
Flannel CNI
- 使用Flannel作为网络提供程序时,Containered CRI插件使用CNI配置文件
/etc/cni/net.d/10-flannel.conflist调用Flannel CNI插件 - Fannel CNI插件与Flanneld结合使用。当Flanneld启动时,它会从apiserver中获取podCIDR和其他与网络相关的详细信息,并将它们存储在文件
/run/flannel/subnet.env中 - Flannel CNI插件使用
/run/flannel/subnet.env中的信息来配置和调用网桥CNI插件。
- 使用Flannel作为网络提供程序时,Containered CRI插件使用CNI配置文件
Bridge CNI
首次调用Bridge CNI插件时,它将使用配置文件中指定的
"name": "cni0"创建一个Linux网桥。然后,它为每个Pod创建veth对-该对的一端在容器的网络名称空间中,另一端连接到主机网络上的linux桥。使用Bridge CNI插件,主机上的所有容器都连接到主机网络上的linux网桥。配置完veth对后,Bridge插件将调用主机本地IPAM CNI插件
host-local IPAM CNI
Host-local IPAM(IP地址管理)插件从子网返回容器的IP地址,并将分配的IP本地存储在主机上
经过Pod网络配置后,本机的Pod应该是这样的:
[root@k8s-master /etc/containerd]#ifconfig cni0
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.1 netmask 255.255.255.0 broadcast 10.244.0.255
inet6 fe80::e851:1cff:fe31:649a prefixlen 64 scopeid 0x20<link>
ether ea:51:1c:31:64:9a txqueuelen 1000 (Ethernet)
RX packets 1073908 bytes 180622775 (172.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1193490 bytes 101571587 (96.8 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 每个机器节点,可以去改目录下,查看flannel插件,如何记录的每个节点pod的IP地址,保证唯一
ls /var/lib/cni/networks/cbr0/
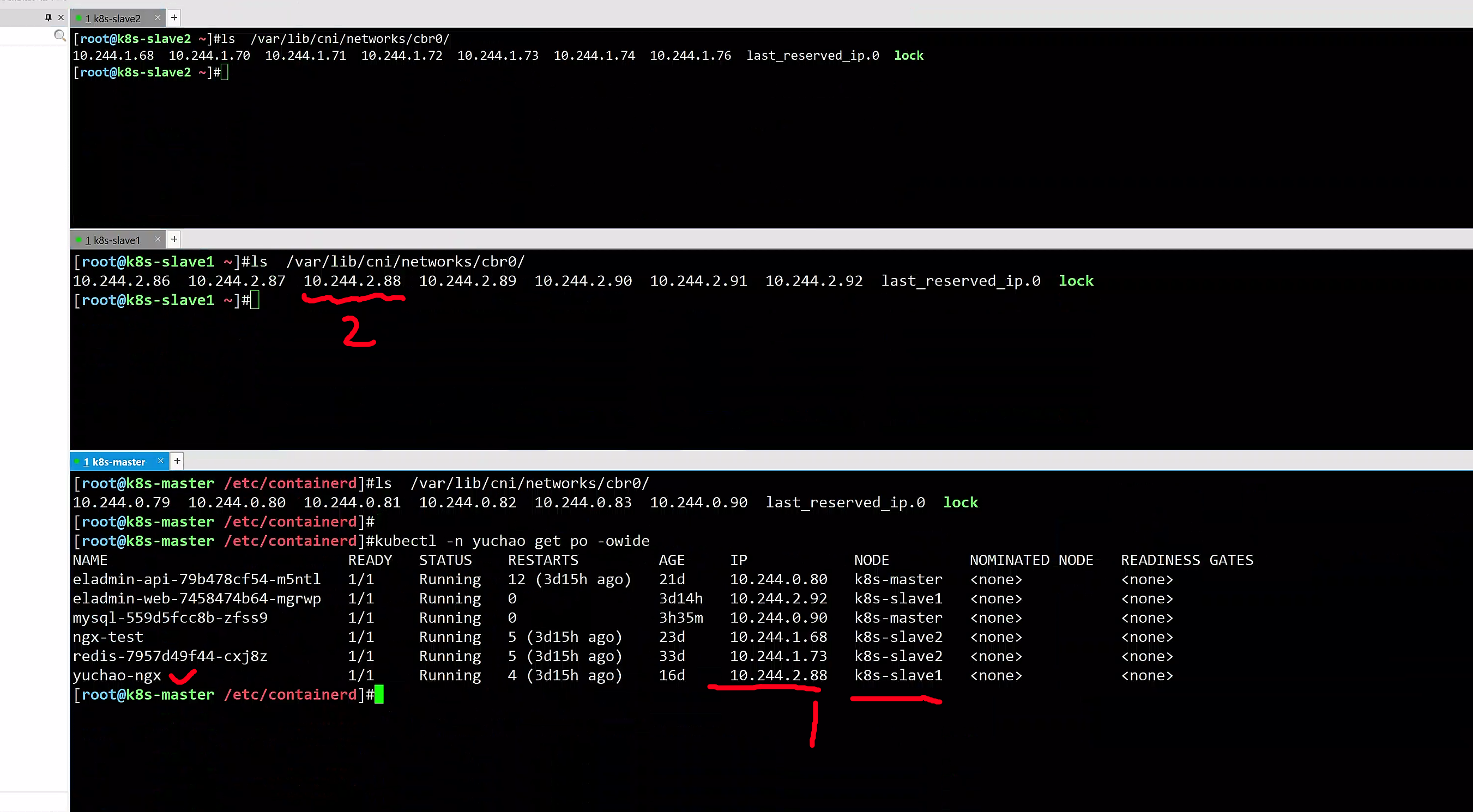
以及查看网桥cni0,同样的是三个机器都有。
[root@k8s-master /etc/containerd]#yum install bridge-utils -y
[root@k8s-master /etc/containerd]#brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.ea511c31649a no veth1866709e
veth4fc4eb9c
veth5b553c2b
veth81f7ed4b
veth9f97fedb
vethc397b7d4
docker0 8000.02421a0b0645 no

至此,在node单机上,flannel如何设置的pod IP过程,基本了解了。
还得思考更近一步的,node集群之间的pod如何通信
思考
flannel插件和kube-flannel的Pod什么关系
Flannel插件和kube-flannel的Pod是密切相关的,因为kube-flannel是使用Flannel作为底层网络的一种实现方式。
Flannel是Kubernetes中一个非常流行的网络插件,用于在Kubernetes集群中创建一个覆盖整个集群的虚拟网络。它使用Overlay网络技术,可以将多个物理主机上的Docker容器连接在一起,使它们看起来像在同一个子网中。Flannel还使用etcd等分布式键值存储系统来管理网络配置和状态信息。
kube-flannel是一个特定的Flannel实现,专门用于Kubernetes集群。它通过创建一个名为kube-flannel的DaemonSet Pod来实现,该Pod在每个节点上运行一个Flannel代理,以确保所有节点上的容器都可以互相通信。 kube-flannel还使用了Kubernetes CNI(Container Network Interface)插件,以与Kubernetes API交互,管理Pod网络配置和状态信息。
因此,kube-flannel的Pod是Flannel插件在Kubernetes中的一种具体实现方式,是Kubernetes中使用Flannel网络插件的重要组成部分。
跨主机的Pod间如何实现通信
在 Kubernetes 集群中,跨主机的 Pod 间可以使用 flannel 等 CNI 插件来实现通信。
flannel 是 Kubernetes 中常用的 CNI 插件之一,它可以为 Pod 分配一个唯一的虚拟 IP 地址,并确保集群内的所有节点能够通过该 IP 地址进行通信。
flannel 的工作原理是在每个节点上创建一个虚拟网络,将 Pod 的网络流量封装在该虚拟网络中,并通过节点之间的路由转发实现跨节点的通信。
下面是使用 flannel 实现跨主机的 Pod 间通信的步骤:
在 Kubernetes 集群中的每个节点上安装并配置 flannel 插件。
创建一个 Deployment 或 StatefulSet 对象,用于创建多个 Pod 实例。
确保 Pod 所在的节点已经加入了 flannel 的虚拟网络中,并分配了一个唯一的虚拟 IP 地址。
在其他 Pod 中,可以使用该虚拟 IP 地址访问该 Pod。
需要注意的是,flannel 需要确保节点之间的网络互通,即集群中的所有节点都能够互相通信。在 Kubernetes 中,可以通过在节点上配置正确的网络路由和防火墙规则来实现网络互通。
总之,使用 CNI 插件(如 flannel)可以方便地实现跨主机的 Pod 间通信,并且能够提供稳定、高效、安全的网络连接。
kube-flannel是什么
查看kube-flannel的pod
[root@k8s-master /etc/containerd]#kubectl -n kube-flannel get pod
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-f6fpt 1/1 Running 8 (3d16h ago) 44d
kube-flannel-ds-gs9dt 1/1 Running 8 (3d16h ago) 44d
kube-flannel-ds-mdbpf 1/1 Running 9 (3d16h ago) 44d
# 查看进程
[root@k8s-master /etc/containerd]#ps -ef|grep flannel
root 3135 2364 0 Apr19 ? 00:05:51 /opt/bin/flanneld --ip-masq --iface=ens33 --kube-subnet-mgr
# 查看flannel网络插件容器内信息
[root@k8s-master /etc/containerd]#kubectl -n kube-flannel exec -it kube-flannel-ds-f6fpt -c kube-flannel -- bash
k8s-slave2:/#
k8s-slave2:/# ps -ef
PID USER TIME COMMAND
1 root 5:42 /opt/bin/flanneld --ip-masq --iface=ens33 --kube-subnet-mgr
17622 root 0:00 bash
17649 root 0:00 ps -ef
k8s-slave2:/#
k8s-slave2:/# ls /opt/
bin
k8s-slave2:/# ls /opt/bin
flanneld mk-docker-opts.sh
k8s-slave2:/# ls /etc/kube-flannel/
cni-conf.json net-conf.json
# 查看kube-flannel这个pod都定义了什么功能
[root@k8s-master /etc/containerd]#kubectl -n kube-flannel get pod kube-flannel-ds-f6fpt -oyaml
# 解读yaml,也就是pod都干了什么事
containers:
- args:
- --ip-masq
- --iface=ens33
- --kube-subnet-mgr
command:
- /opt/bin/flanneld
# 等于容器内执行/opt/bin/flanneld --ip-masq --iface=ens33 --kube-subnet-mgr
# 有出现一波初始化容器的操作
initContainers:
- args:
- -f
- /flannel
- /opt/cni/bin/flannel
command:
- cp
- args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
command:
- cp
# 这两步骤就等于
# 2. cp -f /flannel /opt/cni/bin/flannel
# 3. cp -f /etc/kube-flannel/cni-conf.json /etc/cni/net.d/10-flannel.conflist
# 等于flannel这个插件程序,获取了宿主机上的配置文件
这些任务的完成可以确保"kube-flannel"插件正确地配置和运行,从而提供网络互联和通信服务,使得Kubernetes集群中的Pod可以相互访问和通信。
# /etc/cni/net.d/10-flannel.conflist作用
该配置文件指定了 Flannel 应在节点上创建的网络接口(cbr0),以及 Flannel 使用的两个 CNI 插件 flannel 和 portmap 的配置。
flannel 插件负责设置 Flannel 网络,而 portmap 插件则为容器启用端口映射。
通过读取配置文件,flanneld 知道如何设置必要的网络接口、路由和规则,以在节点上启用使用 Flannel 的容器网络。
# 从进程可以得知:
启动flanneld进程,功能未知
拷贝flannel的网络插件到宿主机中,为containerd调用
考虑flannel的配置文件,当成宿主机的CNI配置,告知containerd使用flannel
/opt/bin/flanneld 是一个二进制可执行文件,通常用于在 Kubernetes 集群中为 Pod 提供网络连接。它实现了 Kubernetes 网络模型中的 CNI 插件,为 Pod 分配和管理网络地址,并提供网络隔离和路由功能。
具体来说,flanneld 实现了一个虚拟网络层,称为 flannel 网络,该网络为每个节点和 Pod 分配唯一的 IP 地址。它还负责将这些 IP 地址映射到物理网络接口上,以便实现节点之间的通信和与外部网络的连接。
在集群中,每个节点都需要运行 flanneld 以确保网络正常工作。它还需要与 Kubernetes 的其他组件集成,如 kubelet、kube-proxy 等,以确保 Pod 能够正确地访问网络资源。
总之,/opt/bin/flanneld 的作用是为 Kubernetes 集群提供网络支持,确保 Pod 能够正常通信,并且可以连接到外部网络。
查看pod跨主机通信(vxlan)

问题就在于,如何理解中间这个flennel创建的vxlan
flannel的网络有多种后端实现:
- udp
- vxlan
- host-gw
- ...
不特殊指定的话,默认会使用vxlan技术作为Backend,可以通过如下查看:
[root@k8s-master /etc/containerd]#kubectl -n kube-flannel exec -it kube-flannel-ds-f6fpt -c kube-flannel -- cat /etc/kube-flannel/net-conf.json
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
使用vxlan作为后端实现时,flanneld进程的作用:
- 启动flannel.1作为VTEP设备,用来封包、解包,实现跨主机通信
- 监听宿主机的Pod CIDR,维护本机路由表
vxlan是什么
本部分需要有一定的网络基础知识方可理解,否则作为了解即可。
Vlan基础知识
https://support.huawei.com/enterprise/zh/doc/EDOC1100086528
VLAN(Virtual Local Area Network)即虚拟局域网,是将一个物理的LAN在逻辑上划分成多个广播域的通信技术。
每个VLAN是一个广播域,VLAN内的主机间通信就和在一个LAN内一样,而VLAN间则不能直接互通,这样,广播报文就被限制在一个VLAN内。
两台交换机放置在不同的地点,比如写字楼的不同楼层,每台交换机分别连接两台属于不同企业用户的计算机,此时就可以将两台计算机划分到不同的VLAN,实现对不同企业用户的隔离。
vxlan基础知识
覆盖网络(overlay network),不直接与物理网络相连。
https://support.huawei.com/enterprise/zh/doc/EDOC1100087027
VXLAN(Virtual eXtensible Local Area Network,虚拟扩展局域网),是由IETF定义的NVO3(Network Virtualization over Layer 3)标准技术之一,是对传统VLAN协议的一种扩展。
VXLAN的特点是将L2的以太帧封装到UDP报文(即L2 over L4)中,并在L3网络中传输。
如图1-1所示,VXLAN本质上是一种隧道技术,在源网络设备与目的网络设备之间的IP网络上,建立一条逻辑隧道,将用户侧报文经过特定的封装后通过这条隧道转发。从用户的角度来看,接入网络的服务器就像是连接到了一个虚拟的二层交换机的不同端口上(可把蓝色虚框表示的数据中心VXLAN网络看成一个二层虚拟交换机),可以方便地通信。

VXLAN已经成为当前构建数据中心的主流技术,是因为它能很好地满足数据中心里虚拟机动态迁移和多租户等需求。
VXLAN 全称是虚拟可扩展的局域网( Virtual eXtensible Local Area Network),它是一种 overlay 技术,通过三层的网络来搭建虚拟的二层网络。
VXLAN(Virtual Extensible LAN)是一种网络虚拟化技术,用于扩展数据中心网络的规模,允许将大量虚拟机连接到一个统一的逻辑网络中。它通过在现有的物理网络基础设施上建立一个虚拟网络来实现这一点。
VXLAN使用一个24位的虚拟网络标识符(VNI)来区分虚拟网络。在VXLAN中,虚拟机的MAC地址被封装在一个VXLAN头中,然后通过物理网络进行传输。这样,虚拟机可以在逻辑上位于不同的子网中,但实际上它们可以通过VXLAN头被转发到同一个子网中。
VXLAN使用UDP协议在物理网络上传输虚拟机的数据包。这允许VXLAN可以穿过不同的网络设备和防火墙,并且具有更好的可扩展性和灵活性。
总之,VXLAN是一种用于虚拟化数据中心网络的技术,它通过建立一个虚拟网络来扩展物理网络的规模,并且使用UDP协议在物理网络上传输虚拟机的数据包。
通过华为的官网技术文章、可以对虚拟交换机有一点认识。
理解vxlan与点对点通信
传统VM虚拟机架构
传统的数据中心物理服务器利用率太低,平均只有10%~15%,浪费了大量的电力能源和机房资源,所以出现了服务器虚拟化技术。
如图1-2所示,服务器虚拟化技术是把一台物理服务器虚拟化成多台逻辑服务器,这种逻辑服务器被称为虚拟机(VM)。
每个VM都可以独立运行,有自己的操作系统、APP,当然也有自己独立的MAC地址和IP地址,它们通过服务器内部的虚拟交换机(vSwitch)与外部实体网络连接。
也就是我们正在用的vmnet8(NAT)

通过服务器虚拟化,可以有效地提高服务器的利用率,降低能源消耗,降低数据中心的运营成本,所以虚拟化技术目前得到了广泛的应用。
什么是二层交换机

二层交换机工作在OSI模型的第二层,数据链路层,所以称为二层交换机。
二层交换技术是发展比较成熟,二层交换机属数据链路层设备,可以识别数据包中的MAC地址信息,根据MAC地址进行转发,并将这些MAC地址与对应的端口记录在自己内部的一个地址表中。
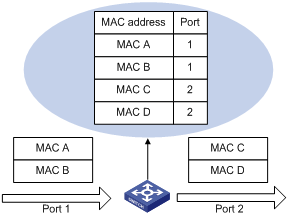
- 当交换机从某个端口收到一个数据包,它先读取包头中的源MAC地址,这样它就知道源MAC地址的机器是连在哪个端口上;
- 再去读取包头中的目的MAC地址,并在地址表中查找相应的端口;
- 如表中有与这目的MAC地址对应的端口,把数据包直接复制到这端口上;
虚拟机迁移
所谓虚拟机动态迁移,就是在保证虚拟机上服务正常运行的同时,将一个虚拟机系统从一个物理服务器移动到另一个物理服务器的过程。
该过程对于最终用户来说是无感知的,从而使得管理员能够在不影响用户正常使用的情况下,灵活调配服务器资源,或者对物理服务器进行维修和升级。
在服务器虚拟化后,虚拟机动态迁移变得常态化,为了保证迁移时业务不中断,就要求在虚拟机迁移时,不仅虚拟机的IP地址不变,而且虚拟机的运行状态也必须保持原状(例如TCP会话状态),所以虚拟机的动态迁移只能在同一个二层域中进行,而不能跨二层域迁移。
如图1-3所示,传统的二三层网络架构限制了虚拟机的动态迁移范围,迁移只能在一个较小的局部范围内进行,应用受到了极大的限制。
图1-3 传统的二三层网络架构限制了虚拟机的动态迁移范围

VXLAN如何满足虚拟机动态迁移时对网络的要求?
众所周知,同一台二层交换机可以实现下挂服务器之间的二层通信,而且服务器从该二层交换机的一个端口迁移到另一个端口时,IP地址是可以保持不变的。这样就可以满足虚拟机动态迁移的需求了。VXLAN的设计理念和目标正是由此而来的。
从上一个小节我们可以知道,VXLAN本质上是一种隧道技术,当源和目的之间有通信需求时,便在数据中心IP网络之上创建一条虚拟的隧道,透明转发用户数据。而数据中心内相互通信的需求众多,这种隧道的建立方式几乎是全互联形态才能满足通信需求。
VXLAN可以提供一套方法论,在数据中心IP网络基础上,构建一张全互联的二层隧道虚拟网络,保证任意两点之间都能通过VXLAN隧道来通信,并忽略底层网络的结构和细节。从服务器的角度看,VXLAN为它们将整个数据中心基础网络虚拟成了一台巨大的“二层交换机”,所有服务器都连接在这台虚拟二层交换机上。而基础网络之内如何转发都是这台“巨大交换机”内部的事情,服务器完全无需关心。
图1-4 VXLAN将整个数据中心基础网络虚拟成了一台巨大的“二层交换机”

理解flannel的通信
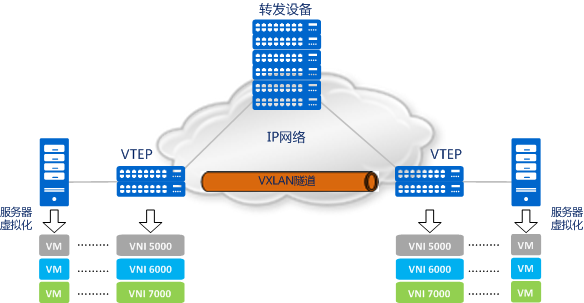
它创建在原来的 IP 网络(三层)上,只要是三层可达(能够通过 IP 互相通信)的网络就能部署 vxlan。在每个端点上都有一个 vtep 负责 vxlan 协议报文的封包和解包,也就是在虚拟报文上封装 vtep 通信的报文头部。物理网络上可以创建多个 vxlan 网络,这些 vxlan 网络可以认为是一个隧道,不同节点的虚拟机能够通过隧道直连。每个 vxlan 网络由唯一的 VNI 标识,不同的 vxlan 可以不相互影响。
- VTEP(VXLAN Tunnel Endpoints):vxlan 网络的边缘设备,用来进行 vxlan 报文的处理(封包和解包)。vtep 可以是网络设备(比如交换机),也可以是一台机器(比如虚拟化集群中的宿主机)
- VNI(VXLAN Network Identifier):VNI 是每个 vxlan 的标识,一共有 2^24 = 16,777,216,一般每个 VNI 对应一个租户,也就是说使用 vxlan 搭建的公有云可以理论上可以支撑千万级别的租户
实践vxlan创建
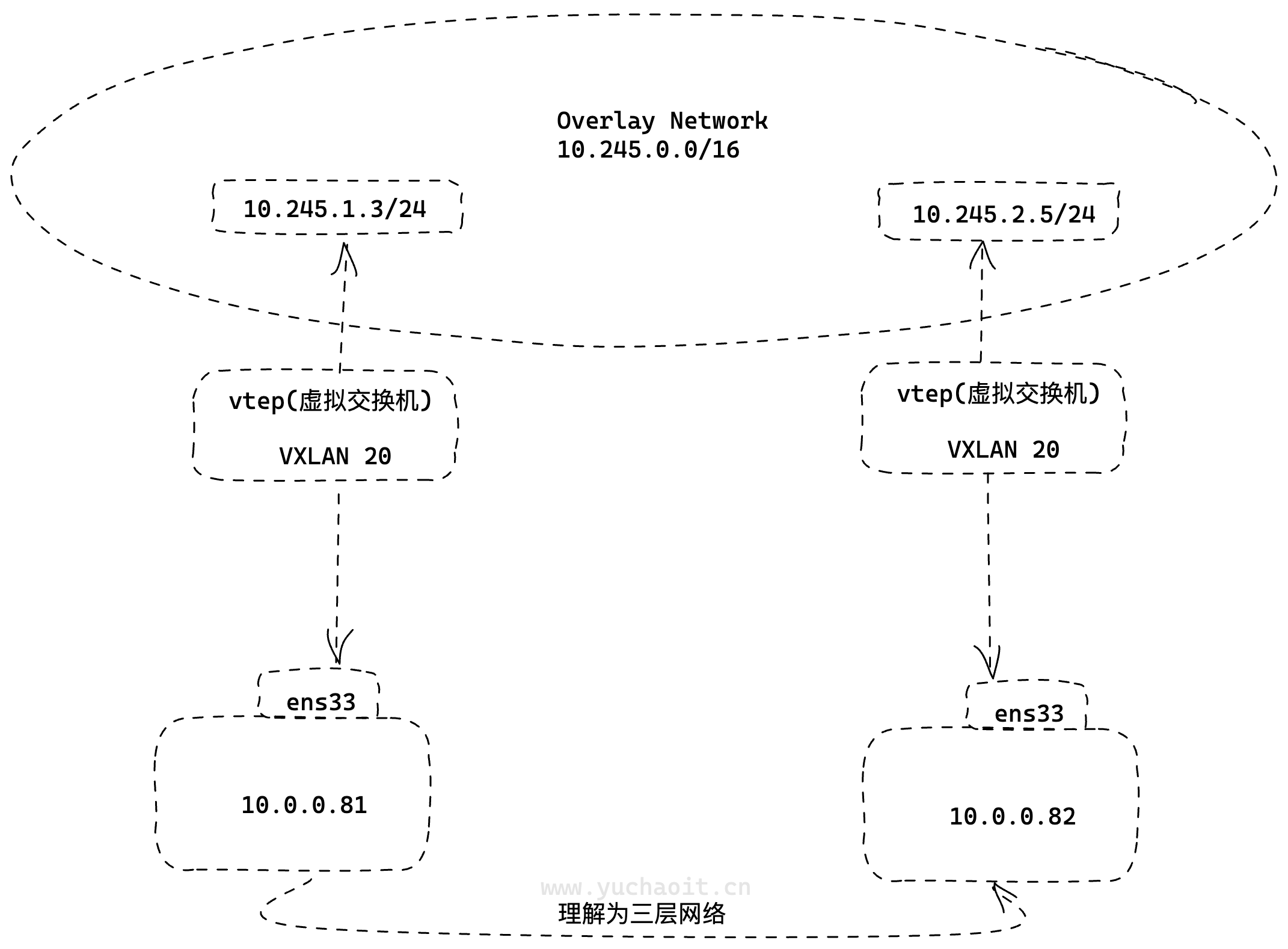
按上图架构,自定义创建一个vxlan三层网络。
先在两端的机器,创建一对VTEP
[root@k8s-slave1 ~]#ip link add vxlan20 type vxlan id 20 remote 10.0.0.82 dstport 4789 dev ens33
[root@k8s-slave1 ~]#
[root@k8s-slave2 ~]#ip link add vxlan20 type vxlan id 20 remote 10.0.0.81 dstport 4789 dev ens33
两个设备都设置ip且启动
# 查看VTEP接口详细信息
# VXLAN是一种虚拟化技术,可在现有网络基础设施上创建逻辑隔离的虚拟网络。
ip -d link show vxlan20
# 启动vxlan网卡
ip link set vxlan20 up
分别设置两端的ip
[root@k8s-slave1 ~]#ip addr add 10.245.1.3/24 dev vxlan20
[root@k8s-slave2 ~]#ip addr add 10.245.2.5/24 dev vxlan20
默认两端是不通的,需要添加路由发送到vxlan20
# 默认是不通的
[root@k8s-slave1 ~]#ping 10.245.2.5
PING 10.245.2.5 (10.245.2.5) 56(84) bytes of data.
# 在10.0.0.81机器
ip route add 10.245.2.0/24 dev vxlan20
# 10.0.0.82机器
[root@k8s-slave2 ~]#ping 10.245.1.3
PING 10.245.1.3 (10.245.1.3) 56(84) bytes of data.
ip route add 10.245.1.0/24 dev vxlan20
至此,双端就可以ping通了。
理解隧道
隧道是一个逻辑上的概念,在 vxlan 模型中并没有具体的物理实体相对应。隧道可以看做是一种虚拟通道,vxlan 通信双方(图中的虚拟机)认为自己是在直接通信,并不知道底层网络的存在。
从整体来说,每个 vxlan 网络像是为通信的虚拟机搭建了一个单独的通信通道,也就是隧道。
实现的过程:
虚拟机的报文通过 vtep 添加上 vxlan 以及外部的报文层,然后发送出去,对方 vtep 收到之后拆除 vxlan 头部然后根据 VNI 把原始报文发送到目的虚拟机。
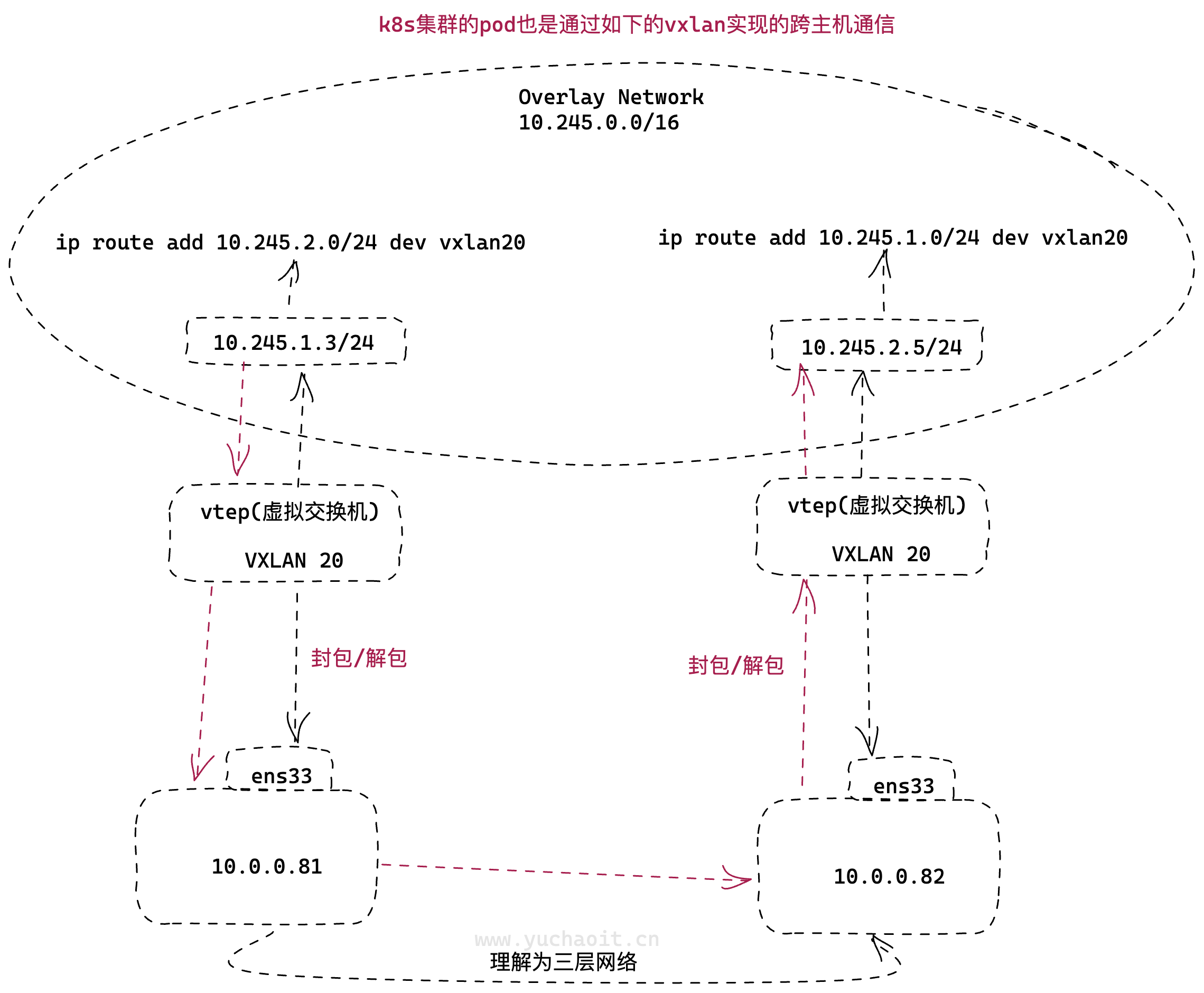
清理vxlan
ip link del vxlan20
实践pod通信流量过程
# 本地网桥,实现本地pod之间通信
[root@k8s-slave1 ~]#ifconfig cni0
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.2.1 netmask 255.255.255.0 broadcast 10.244.2.255
inet6 fe80::6ce6:7dff:fe2c:ee4e prefixlen 64 scopeid 0x20<link>
ether 6e:e6:7d:2c:ee:4e txqueuelen 1000 (Ethernet)
RX packets 1815873 bytes 526540329 (502.1 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2446847 bytes 191647468 (182.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@k8s-slave1 ~]#
# 查看VTEP设备
[root@k8s-slave1 ~]#ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.2.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::8854:58ff:fecd:7fc1 prefixlen 64 scopeid 0x20<link>
ether 8a:54:58:cd:7f:c1 txqueuelen 0 (Ethernet)
RX packets 2256876 bytes 147134890 (140.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1713437 bytes 520670804 (496.5 MiB)
TX errors 0 dropped 1143 overruns 0 carrier 0 collisions 0
[root@k8s-slave1 ~]#
[root@k8s-slave2 ~]#ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.1.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::f0f3:3dff:fe6d:76ac prefixlen 64 scopeid 0x20<link>
ether f2:f3:3d:6d:76:ac txqueuelen 0 (Ethernet)
RX packets 960650 bytes 86183169 (82.1 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 925012 bytes 527732765 (503.2 MiB)
TX errors 0 dropped 275 overruns 0 carrier 0 collisions 0
这个flannel.1就参考是我们刚才创建的vxlan20
查看机器路由
[root@k8s-master ~]#ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::e8be:7fff:fed0:f0f4 prefixlen 64 scopeid 0x20<link>
ether ea:be:7f:d0:f0:f4 txqueuelen 0 (Ethernet)
RX packets 2891162 bytes 1060474965 (1011.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3222539 bytes 233686911 (222.8 MiB)
TX errors 0 dropped 258 overruns 0 carrier 0 collisions 0
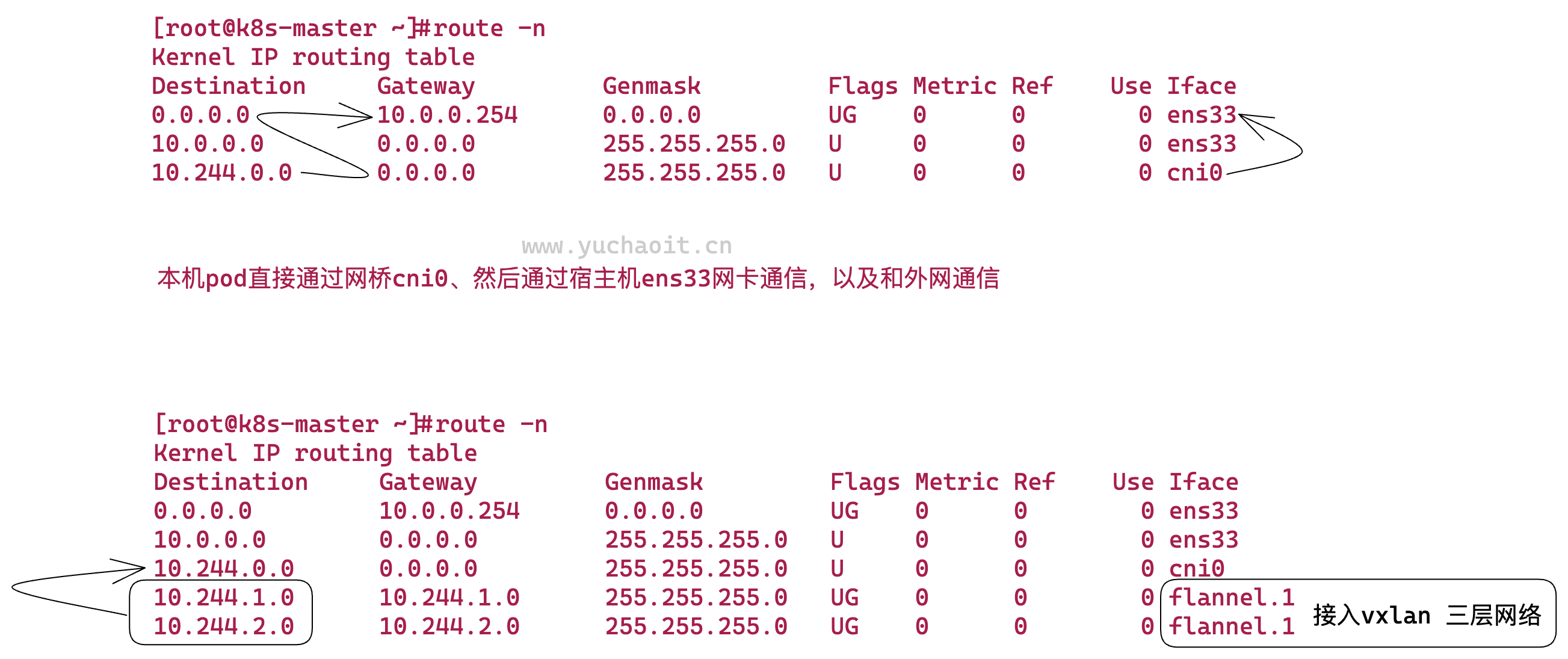
[root@k8s-master ~]#route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.254 0.0.0.0 UG 0 0 0 ens33
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 ens33
169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 ens37
172.16.1.0 0.0.0.0 255.255.255.0 U 0 0 0 ens37
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
[root@k8s-master ~]#
查看pod跨节点通信
[root@k8s-master ~]#kubectl -n yuchao get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
eladmin-api-79b478cf54-m5ntl 1/1 Running 12 (3d19h ago) 21d 10.244.0.80 k8s-master <none> <none>
eladmin-web-7458474b64-mgrwp 1/1 Running 0 3d18h 10.244.2.92 k8s-slave1 <none> <none>
mysql-559d5fcc8b-zfss9 1/1 Running 0 7h22m 10.244.0.90 k8s-master <none> <none>
ngx-test 1/1 Running 5 (3d19h ago) 23d 10.244.1.68 k8s-slave2 <none> <none>
redis-7957d49f44-cxj8z 1/1 Running 5 (3d19h ago) 33d 10.244.1.73 k8s-slave2 <none> <none>
yuchao-ngx 1/1 Running 4 (3d19h ago) 16d 10.244.2.88 k8s-slave1 <none> <none>
[root@k8s-master ~]#
# 跨节点的pod IP是通的
[root@k8s-master ~]#kubectl -n yuchao exec yuchao-ngx -- ping 10.244.1.73 -c 3
PING 10.244.1.73 (10.244.1.73): 56 data bytes
64 bytes from 10.244.1.73: seq=0 ttl=62 time=0.878 ms
64 bytes from 10.244.1.73: seq=1 ttl=62 time=0.559 ms
64 bytes from 10.244.1.73: seq=2 ttl=62 time=0.370 ms
--- 10.244.1.73 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.370/0.602/0.878 ms
# 查看pod路由
[root@k8s-master ~]#kubectl -n yuchao exec yuchao-ngx -- route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.2.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.2.1 255.255.0.0 UG 0 0 0 eth0
10.244.2.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
[root@k8s-master ~]#
# 最后由flannel.1进行封包、解包
[root@k8s-slave1 ~]#route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.254 0.0.0.0 UG 0 0 0 ens33
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.2.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 ens33
169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 ens37
172.16.1.0 0.0.0.0 255.255.255.0 U 0 0 0 ens37
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0

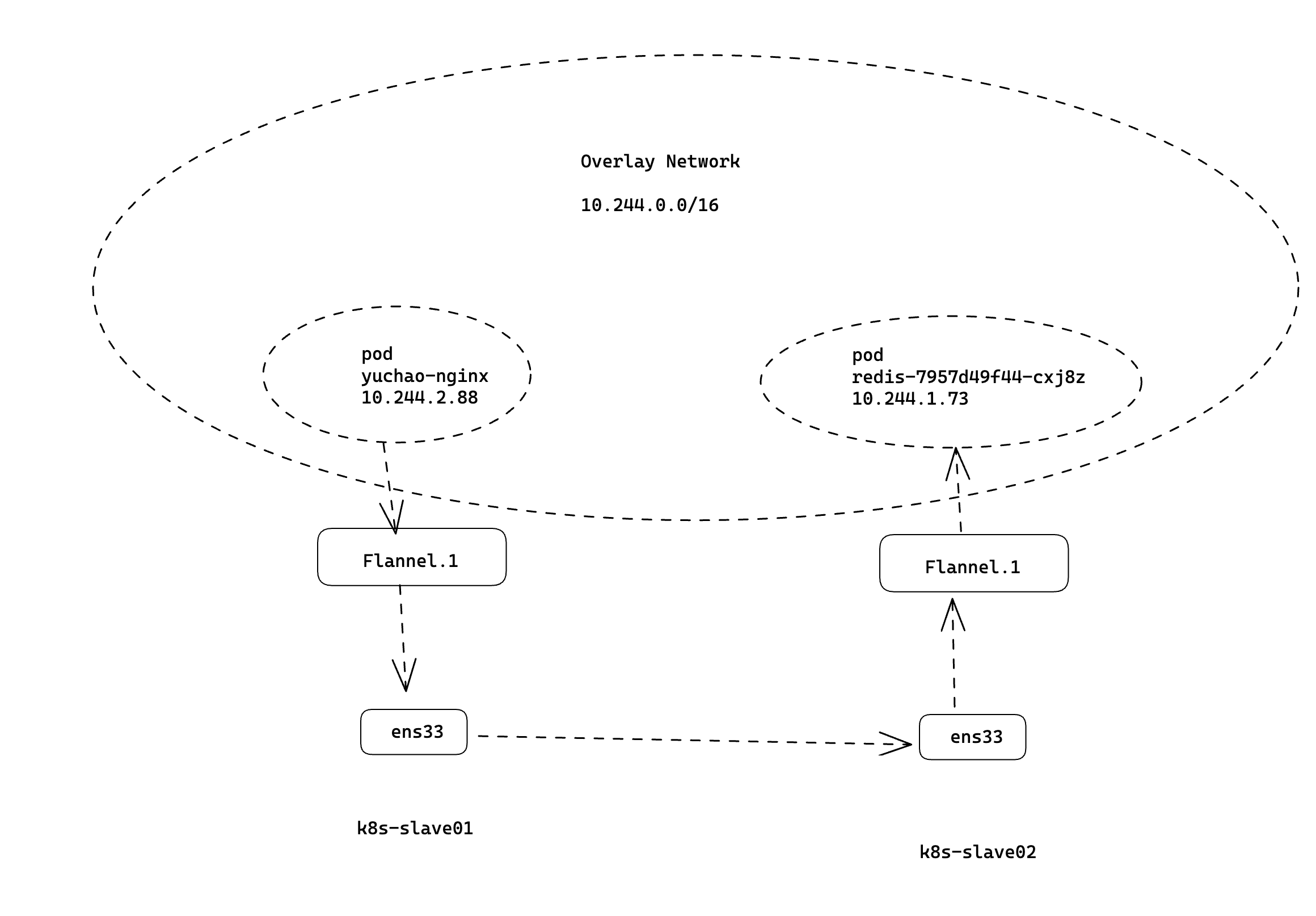
flannel工作原理图
- pod内多个容器,共享pause容器网络,流量通过
veth-pair发到CNI网桥 - 跨主机pod的流量通过
UG路由,到达flannel.1三层网络进行封包,还得通过物理网卡出口,到达目标机器网卡ens33 - 然后同样的进行解包过程
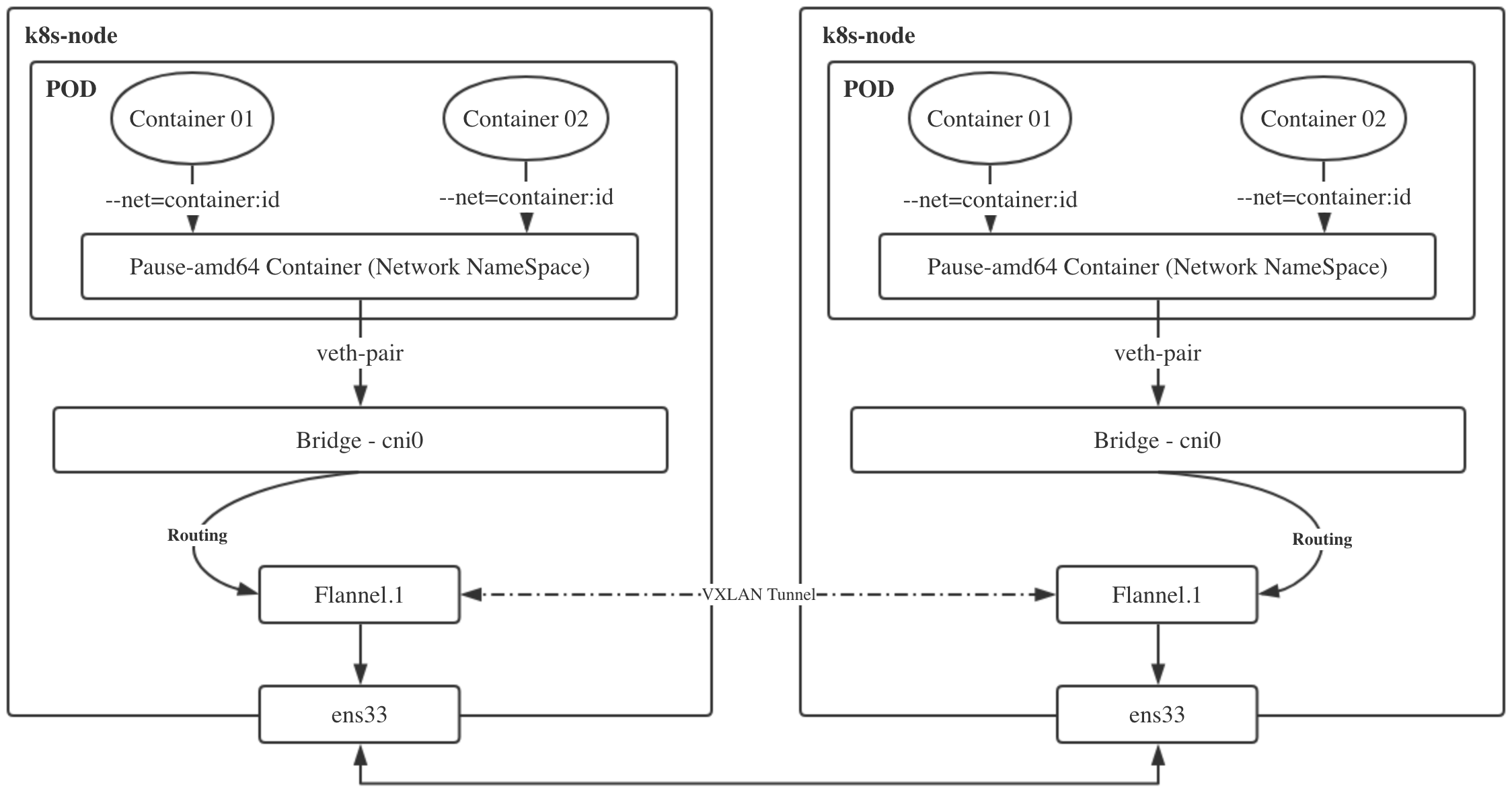
1.flanned以pod形式运行在每个节点,由它创建VTEP。
flanneld是一种用于容器网络的轻量级网络组件,它使用VXLAN(Virtual Extensible LAN)来实现容器之间的通信。VXLAN是一种网络虚拟化技术,它通过在现有网络之上创建逻辑网络来扩展现有网络。
当使用flanneld插件创建VTEP(VXLAN Tunnel End Point)时,flanneld将创建一个VXLAN隧道,该隧道将容器网络中的数据包封装在VXLAN报文中并转发到目标VTEP。
每个VTEP都有一个唯一的VXLAN标识符(VNI),它用于识别不同的VXLAN逻辑网络。
在创建VTEP之前,flanneld需要将节点配置为VXLAN模式,并分配一个唯一的VXLAN VNI。然后,flanneld将在节点上创建一个VTEP,该VTEP将使用节点的IP地址作为其VXLAN源地址,并且将使用VXLAN VNI作为其标识符。
创建VTEP后,容器可以通过VXLAN隧道进行通信,并且它们的通信将被封装在VXLAN报文中,并在VTEP之间转发。
2.Flanned维护集群路由表
# 每个节点上都可以看到flannel.1的路由
[root@k8s-master ~]#route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.254 0.0.0.0 UG 0 0 0 ens33
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 ens33
169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 ens37
172.16.1.0 0.0.0.0 255.255.255.0 U 0 0 0 ens37
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
host-gw网络模式
学习该模式,也是为了更好理解pod跨集群通信,可选择的模式。
Host-gw和VXLAN都是用于虚拟化网络的技术,但它们的实现方式和性能表现有所不同。
Host-gw(host gateway)是一种基于路由的虚拟网络技术,使用物理主机上的路由表将虚拟机通信转发到物理网络。它的优点是实现简单,不需要额外的网络设备支持。但它的性能受限于物理主机的处理能力和路由表的大小,当虚拟机数量增多时,可能会出现性能瓶颈。
VXLAN(Virtual eXtensible Local Area Network)是一种基于隧道的虚拟网络技术,它使用UDP封装虚拟机通信,将虚拟机数据包封装在VXLAN报文中,通过物理网络传输。VXLAN的优点是可以扩展到大规模虚拟网络中,并支持多租户网络隔离。但它需要额外的网络设备支持(如VTEP),并且会增加网络延迟和开销。
因此,Host-gw和VXLAN的性能比较需要考虑具体场景和需求。在小规模虚拟化场景中,Host-gw可能更加适合,而在大规模虚拟化场景中,VXLAN可能更适合。
怎么理解flannel的host-gw模式
vxlan模式适用于三层可达的网络环境,对集群的网络要求很宽松,但是同时由于会通过VTEP设备进行额外封包和解包,因此给性能带来了额外的开销。
网络插件的目的其实就是将本机的cni0网桥的流量送到目的主机的cni0网桥。
实际上有很多集群是部署在同一二层网络环境下的,可以直接利用二层的主机当作流量转发的网关。
这样的话,可以不用进行封包解包,直接通过路由表去转发流量。
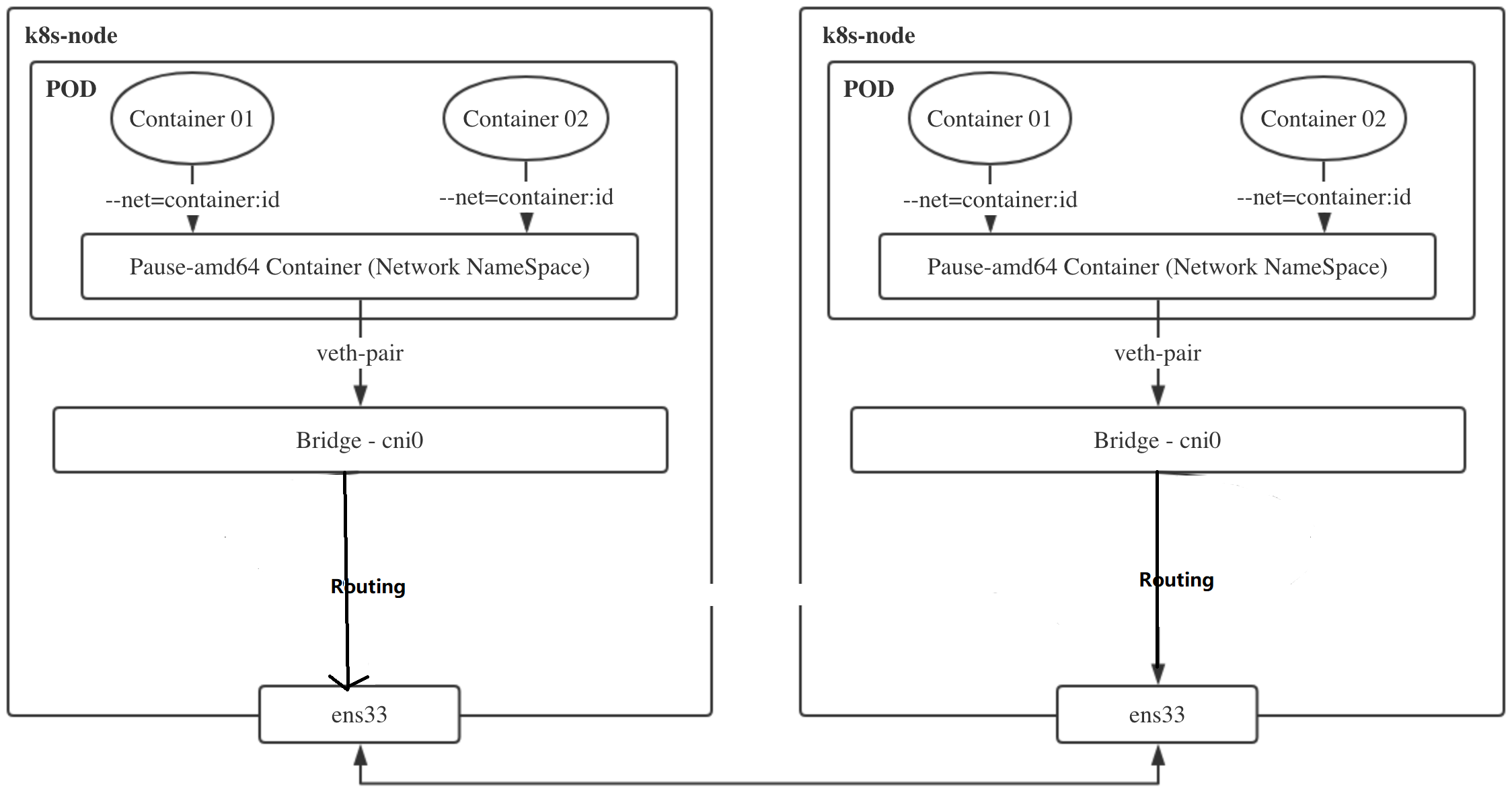
"host-gw"是指在Kubernetes集群中使用的一种网络模式,它允许容器直接使用宿主机的网络栈,包括使用宿主机的IP地址和网关。
在这种模式下,容器可以直接使用宿主机上的路由表,包括默认网关路由。这样,当容器需要访问集群外部的网络资源时,数据包将被直接路由到宿主机的默认网关,从而完成数据转发。
在使用host-gw网络模式时,容器使用宿主机的默认网关路由完成数据转发。

为什么三层可达的网络不直接利用网关转发流量?
内核当中的路由规则,网关必须在跟主机当中至少一个 IP 处于同一网段。
由于k8s集群内部各节点均需要实现Pod互通,因此,也就意味着host-gw模式需要整个集群节点都在同一二层网络内。
这里yuchao老师演示的机器10.0.0.80,10.0.0.81,10.0.0.82就是属于在二层网络下。
在Flannel中,三层可达的网络使用了虚拟网络技术,它通过在物理网络之上构建一个虚拟网络层,为容器提供一个独立的、可路由的IP地址空间。因此,Flannel网络中的容器不直接使用物理网络的网关进行通信。
在Flannel中,每个节点都会运行一个Flannel代理程序,该程序负责在节点之间建立虚拟网络,使得跨节点的容器可以通过该虚拟网络进行通信。Flannel代理程序会为每个节点分配一个虚拟子网,并为该节点上的容器分配一个独立的IP地址。
当容器之间需要通信时,Flannel代理程序会根据目标IP地址选择最佳路径,将数据包从源容器转发到目标容器所在的节点上。如果目标容器不在同一节点上,数据包将通过虚拟网络转发到目标容器所在的节点上。
在Flannel的实现中,虚拟网络的建立和数据包的路由选择是通过底层的网络协议来实现的,具体实现方式包括VXLAN、IPsec、UDP等。这些协议的主要作用是在物理网络之上构建一个虚拟网络层,并为容器提供独立的IP地址空间和路由选择能力。
因此,在Flannel中,三层可达的网络不能直接利用网关转发流量,而是需要通过虚拟网络技术来构建一个独立的、可路由的IP地址空间,实现容器之间的通信。
实践host-gw模式
# 修改flannel配置文件
27 net-conf.json: |
28 {
29 "Network": "10.244.0.0/16",
30 "Backend": {
31 "Type": "host-gw"
32 }
# [root@k8s-master ~]#kubectl edit cm kube-flannel-cfg -n kube-flannel
configmap/kube-flannel-cfg edited
# 重建pod
[root@k8s-master ~]#kubectl -n kube-flannel get po
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-f6fpt 1/1 Running 8 (3d20h ago) 44d
kube-flannel-ds-gs9dt 1/1 Running 8 (3d20h ago) 44d
kube-flannel-ds-mdbpf 1/1 Running 9 (3d20h ago) 44d
[root@k8s-master ~]#
[root@k8s-master ~]#kubectl -n kube-flannel delete po --all
pod "kube-flannel-ds-f6fpt" deleted
pod "kube-flannel-ds-gs9dt" deleted
pod "kube-flannel-ds-mdbpf" deleted
[root@k8s-master ~]#
[root@k8s-master ~]#kubectl -n kube-flannel get po
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-74gxd 1/1 Running 0 5s
kube-flannel-ds-wkjlj 1/1 Running 0 7s
kube-flannel-ds-wxk6p 1/1 Running 0 7s
[root@k8s-master ~]#
# 查看新的pod,因为daemonset会确保pod重建
[root@k8s-master ~]#
[root@k8s-master ~]#kubectl -n kube-flannel get daemonsets.apps
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-flannel-ds 3 3 3 3 3 <none> 44d
[root@k8s-master ~]#
# 查看flannel新模式
[root@k8s-master ~]#kubectl -n kube-flannel logs kube-flannel-ds-74gxd |grep host-gw
Defaulted container "kube-flannel" out of: kube-flannel, install-cni-plugin (init), install-cni (init)
I0423 20:14:57.793044 1 main.go:542] Found network config - Backend type: host-gw
I0423 20:14:57.828567 1 watch.go:51] Batch elem [0] is { subnet.Event{Type:0, Lease:subnet.Lease{EnableIPv4:true, EnableIPv6:false, Subnet:ip.IP4Net{IP:0xaf40000, PrefixLen:0x18}, IPv6Subnet:ip.IP6Net{IP:(*ip.IP6)(nil), PrefixLen:0x0}, Attrs:subnet.LeaseAttrs{PublicIP:0xa000050, PublicIPv6:(*ip.IP6)(nil), BackendType:"host-gw", BackendData:json.RawMessage{0x6e, 0x75, 0x6c, 0x6c}, BackendV6Data:json.RawMessage(nil)}, Expiration:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Asof:0}} }
I0423 20:14:57.830334 1 watch.go:51] Batch elem [0] is { subnet.Event{Type:0, Lease:subnet.Lease{EnableIPv4:true, EnableIPv6:false, Subnet:ip.IP4Net{IP:0xaf40200, PrefixLen:0x18}, IPv6Subnet:ip.IP6Net{IP:(*ip.IP6)(nil), PrefixLen:0x0}, Attrs:subnet.LeaseAttrs{PublicIP:0xa000051, PublicIPv6:(*ip.IP6)(nil), BackendType:"host-gw", BackendData:json.RawMessage{0x6e, 0x75, 0x6c, 0x6c}, BackendV6Data:json.RawMessage(nil)}, Expiration:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Asof:0}} }
W0423 20:14:57.830342 1 route_network.go:87] Ignoring non-host-gw subnet: type=vxlan
[root@k8s-master ~]#
# 查看路由表
[root@k8s-master ~]#route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.254 0.0.0.0 UG 0 0 0 ens33
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 10.0.0.82 255.255.255.0 UG 0 0 0 ens33
10.244.2.0 10.0.0.81 255.255.255.0 UG 0 0 0 ens33
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 ens33
169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 ens37
172.16.1.0 0.0.0.0 255.255.255.0 U 0 0 0 ens37
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
[root@k8s-master ~]#
# 可以看到pod相关的子网,都直接用宿主机作为网关转发流量
[root@k8s-master ~]#kubectl -n yuchao get po -owide
[root@k8s-master ~]#kubectl -n yuchao exec yuchao-ngx -- curl 10.244.0.80:8000/who -s
"Who are you ? I am teacher yuchao and my website is www.yuchaoit.cn ! "
# 查看pod,以及目标机器的路由
[root@k8s-master ~]#kubectl -n yuchao exec yuchao-ngx -- route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.2.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.2.1 255.255.0.0 UG 0 0 0 eth0
10.244.2.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
[root@k8s-master ~]#
# 该pod的目标机器
[root@k8s-slave1 ~]#cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.2.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=true
总结flannel工作流程
flannel pod做的几个事情:
- 为了配置本机的Pod网络
- flannel pod启动时,拷贝cni的配置文件
/etc/cni/net.d/10-flannel.conflist,告知CRI(containerd) 使用flannel插件进行配置网络 - 拷贝一份可执行文件到宿主机
/opt/cni/bin/flannel - 调用apiserver,得到分配到本机的PodCIDR,写入到
/run/flannel/subnet.env - 调用本机的bridge插件,创建本地cni0网桥,创建虚拟网卡对,链接cni0和Pod网络空间
- bridge cni调用local ipam插件(host-local),记录并分配pod ip,写入到
/var/lib/cni/networks/cbr0/
- flannel pod启动时,拷贝cni的配置文件
- 为了使得跨主机实现Pod的访问
- 创建flannel.1 vtep设备,支持vxlan模式下封包解包
- 维护本机路由表,转发Pod的流量
详解
- 拷贝CNI配置文件
Flannel Pod启动时,会将CNI的配置文件 /etc/cni/net.d/10-flannel.conflist 拷贝到容器内部,并告知CRI(Container Runtime Interface)使用Flannel插件来配置网络。
- 拷贝可执行文件
Flannel Pod还会将Flannel二进制文件拷贝到宿主机的 /opt/cni/bin/flannel 目录中。这个二进制文件是用来进行网络配置和管理的。
- 获取本机的PodCIDR
Flannel Pod会调用Kubernetes API server,以获取本机被分配的PodCIDR。这个CIDR范围是用来分配给Pod的IP地址。
- 创建本地CNI网桥
Flannel Pod会调用本地的CNI插件,创建一个名为 cni0 的本地网桥,创建一个虚拟网络接口对,连接 cni0 和Pod网络空间。
- 分配Pod IP地址
Flannel Pod会调用 bridge CNI插件,并使用 host-local IPAM插件来分配Pod的IP地址。分配的IP地址将被记录并写入到 /var/lib/cni/networks/cbr0/ 中。
- 创建Flannel VTEP设备
Flannel Pod会创建一个名为 flannel.1 的VTEP(Virtual Tunnel End Point)设备,用来支持VXLAN模式下的封包解包。
- 维护路由表
最后,Flannel Pod会维护本地的路由表,以便转发Pod的流量。这个路由表将包含其他主机上的Pod的IP地址和相应的VTEP设备。这样,当一个Pod需要与其他主机上的Pod通信时,Flannel就可以将流量封装在VXLAN报文中,并通过VTEP设备进行传输。