流水线
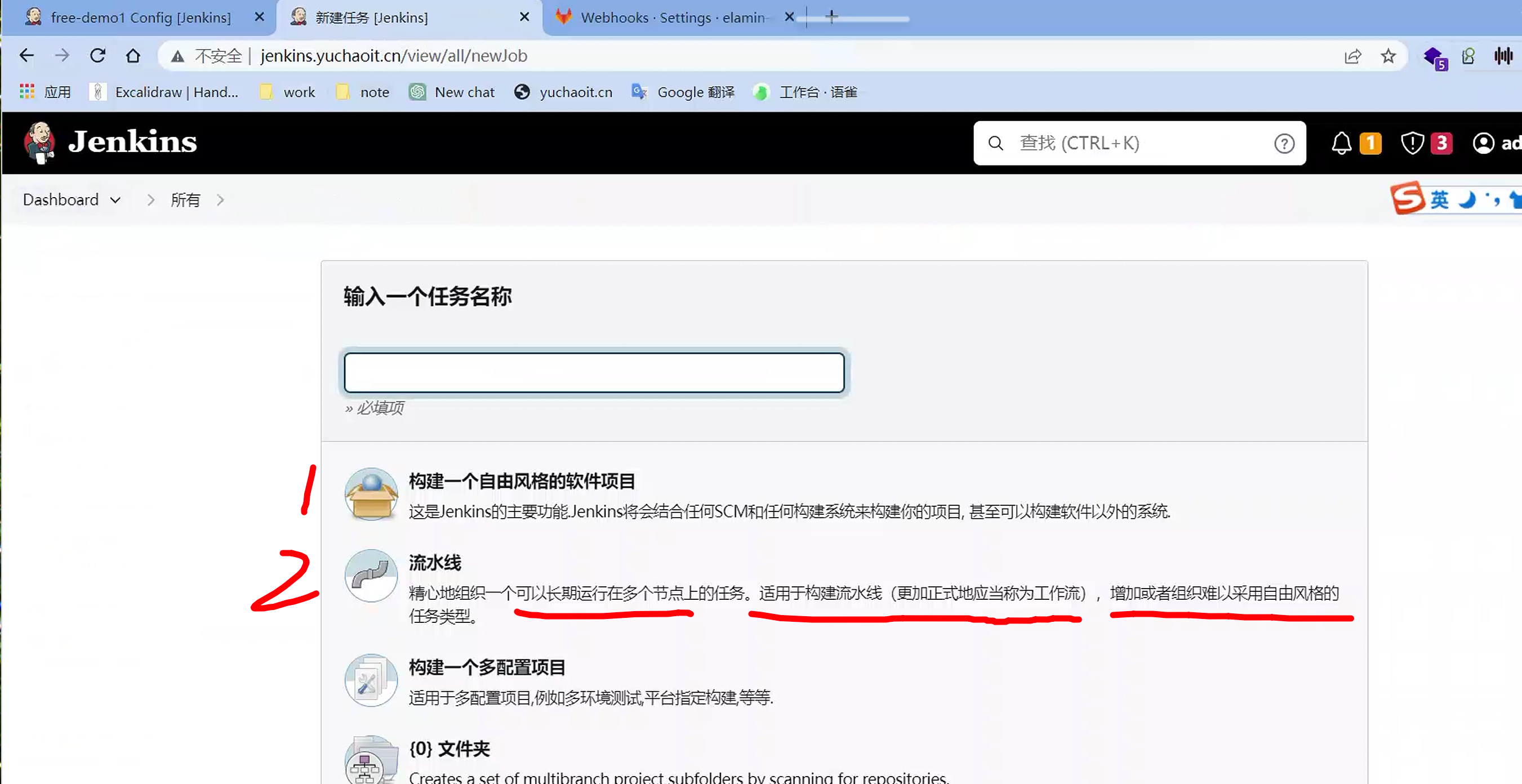
为什么学pipeline
Jenkins的流水线(Pipeline)是一种以可编程方式定义和执行持续集成和交付流程的方法。它提供了一种灵活、可扩展的方式来构建、测试和部署软件项目。
下面是一些关键概念来理解Jenkins的流水线:
- 基于脚本的流程描述:Jenkins的流水线是通过脚本来描述整个构建和部署流程的。这些脚本可以使用Jenkins提供的Declarative Pipeline语法或Scripted Pipeline语法编写。它们允许您定义构建、测试、部署和其他操作的顺序、条件和参数。
- 持续集成和交付:流水线使得持续集成和交付变得更加可控和可视化。您可以将代码提交到源代码管理库(如Git)后,Jenkins可以自动触发流水线,并根据定义的脚本来执行构建、测试和部署任务。这样可以更快地检测和解决问题,并实现持续集成和交付的目标。
- 构建阶段和步骤:流水线由一系列的阶段和步骤组成。每个阶段代表一个逻辑组,如构建、测试、部署等。每个阶段包含一组步骤,代表具体的操作,例如编译代码、运行测试、构建镜像、部署应用等。通过定义多个阶段和步骤,可以将整个流程划分为可管理的部分。
- 并行执行和条件控制:流水线支持并行执行,可以同时执行多个步骤或阶段,以提高构建和部署的效率。此外,您还可以使用条件控制来根据特定条件决定执行的路径,例如根据不同的分支或触发事件执行不同的操作。
- 可视化和日志:Jenkins提供了可视化的流水线界面,用于展示流水线的执行状态、阶段的进度和结果。您可以查看每个步骤的输出、日志和错误信息,以便追踪构建过程中的问题并进行故障排除。
通过使用Jenkins的流水线,您可以以可编程的方式定义和执行复杂的持续集成和交付流程,实现自动化的构建、测试和部署。流水线提供了灵活性、可扩展性和可视化的优势,使得软件开发团队能够更高效地交付高质量的软件。

原本我们用自由风格的job,是手工点击,配置构建的任务;
若是配置的构建任务多了,并且涉及环境迁移等,你可能要重新配置一遍;
在jenkins自动化构建基础之上,就还有更高级的pipeline玩法,连jenkins的任务都写成脚本。
为什么叫做流水线
为什么叫做流水线,和工厂产品的生产线类似,pipeline是从源码到发布到线上环境。关于流水线,需要知道的几个点:
重要的功能插件,帮助Jenkins定义了一套工作流框架;
Pipeline 的实现方式是一套 Groovy DSL( 领域专用语言 ),所有的发布流程都可以表述为一段 Groovy 脚本;
将WebUI上需要定义的任务,以脚本代码的方式表述出来;
帮助jenkins实现持续集成CI(Continue Integration)和持续部署CD(Continue Deliver)的重要手段;
pipeline语法
Jenkins Pipeline支持两种不同的语法类型:Scripted Pipeline和Declarative Pipeline。下面是对这两种语法类型的进一步说明:
- Scripted Pipeline(脚本式流水线):
- Scripted Pipeline是Jenkins最早支持的Pipeline语法类型。
- 它使用Groovy脚本来定义流水线的各个阶段和任务。
- 脚本式流水线提供了灵活性和编程能力,可以直接在脚本中编写自定义逻辑。
- 编写脚本式流水线时,需要熟悉Groovy语法和Jenkins Pipeline的相应API。
- Declarative Pipeline(声明式流水线):
- Declarative Pipeline是在Jenkins Pipeline插件的2.5版本之后引入的新型语法。
- 它采用声明式的语法结构,更加结构化和易读。
- 声明式流水线提供了一组预定义的指令和块,用于描述流水线的不同部分,如构建、测试、部署等。
- 声明式流水线鼓励一种"约定优于配置"的方式,可以更快地编写简单的流水线。
- 它还支持内嵌Scripted Pipeline代码块,以便在需要时使用Scripted Pipeline的灵活性。
虽然两种语法类型都可以用于编写Pipeline脚本,但建议在使用Open Blue Ocean脚本编辑器时,使用Declarative Pipeline方式进行编写,因为它更简洁且与Blue Ocean工具集更兼容。此外,根据Jenkins社区的动向,Declarative Pipeline语法结构也被认为是未来的趋势。
示例脚本
这是一个使用Declarative Pipeline语法编写的Jenkins流水线示例。以下是对该流水线的解释:
agent部分指定在哪个代理节点上执行流水线。在这个例子中,label '10.0.0.81'表示使用具有标签10.0.0.81的代理节点执行。environment部分定义了流水线中的环境变量。在这个例子中,PROJECT = 'myblog'表示设置了一个名为PROJECT的环境变量,其值为'myblog'。stages部分定义了流水线的各个阶段。这个例子中有四个阶段:'Checkout'、'Build'、'Test'和'Deploy'。每个阶段中都有一个steps块,包含要执行的具体步骤。- 在 'Checkout' 阶段中,通过
checkout scm语句从源代码管理系统中检出代码。 - 在 'Build' 阶段中,使用
sh 'make'执行命令make来进行构建。 - 在 'Test' 阶段中,使用
sh 'make check'执行命令make check进行测试,并使用junit 'reports/**/*.xml'指令收集测试报告。 - 在 'Deploy' 阶段中,使用
sh 'make publish'执行命令make publish来进行部署。 post部分定义了流水线的后续操作,其中包括success、failure和always块。这些块中的命令将根据流水线的执行结果执行。- 在
success块中,使用echo命令输出 'Congratulations!'。 - 在
failure块中,使用echo命令输出 'Oh no!'。 - 在
always块中,使用echo命令输出 'I will always say Hello again!'。
- 在
这是一个简单的示例,展示了一个具有基本阶段和后续操作的流水线。你可以根据自己的需求和项目要求进行修改和扩展。
pipeline {
agent {label '10.0.0.81'}
environment {
PROJECT = 'myblog'
}
stages {
stage('Checkout') {
steps {
checkout scm
}
}
stage('Build') {
steps {
sh 'make'
}
}
stage('Test'){
steps {
sh 'make check'
junit 'reports/**/*.xml'
}
}
stage('Deploy') {
steps {
sh 'make publish'
}
}
}
post {
success {
echo 'Congratulations!'
}
failure {
echo 'Oh no!'
}
always {
echo 'I will always say Hello again!'
}
}
}
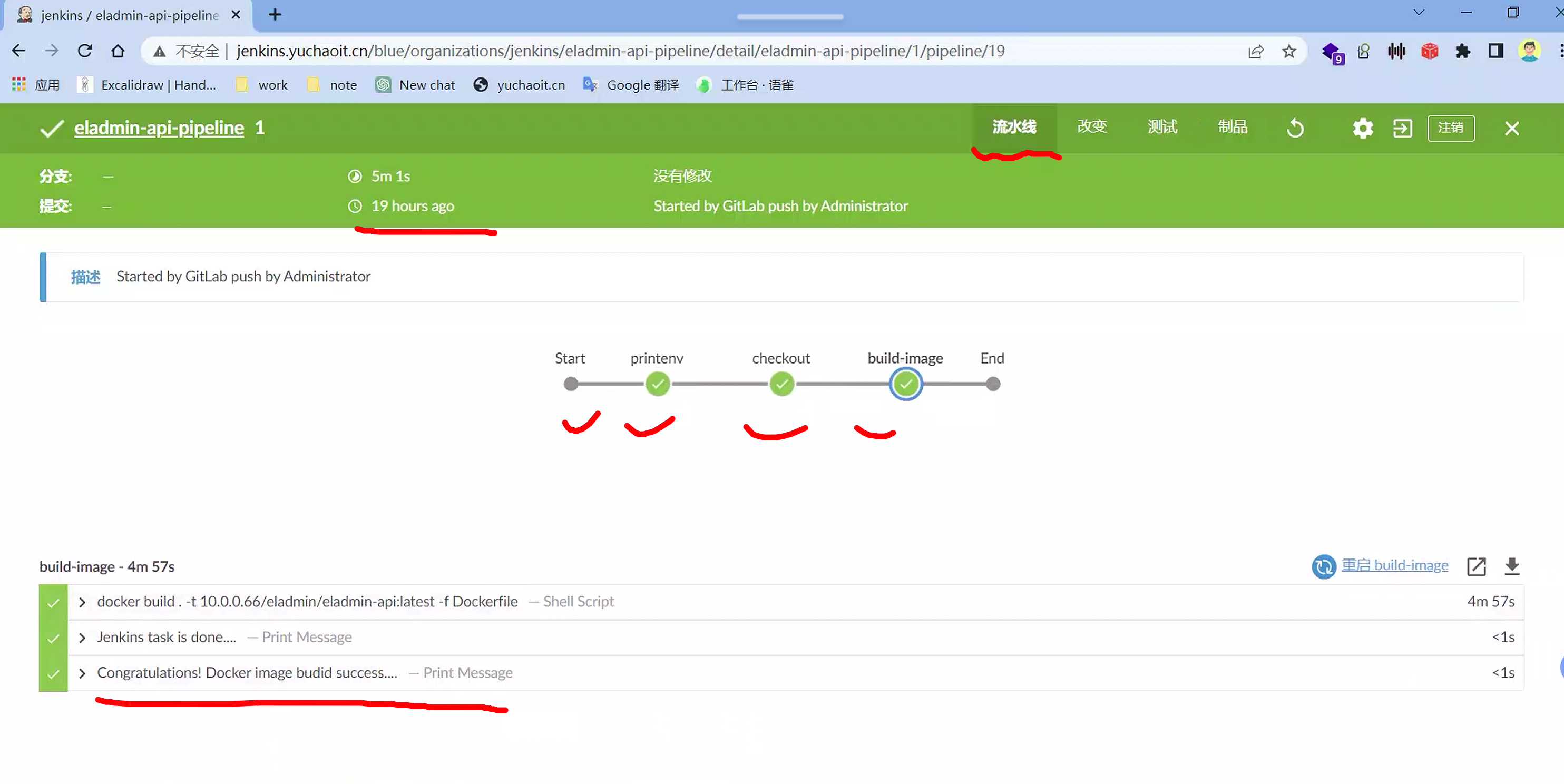
案例1
pipeline {
agent {label '10.0.0.81'}
environment {
PROJECT = 'eladmin-api'
}
stages {
stage('printenv') {
steps {
echo 'Hello World'
sh 'printenv'
}
}
stage('checkout') {
steps {
checkout scmGit(branches: [[name: '*/master']], extensions: [], userRemoteConfigs: [[credentialsId: 'gitlab-user', url: 'http://gitlab.yuchaoit.cn/elamin-ops/eladmin-api.git']])
}
}
stage('build-image') {
steps {
sh 'docker build . -t 10.0.0.66/eladmin/eladmin-api:latest -f Dockerfile'
}
}
}
post {
success {
echo 'Congratulations! Docker image budid success....'
}
failure {
echo 'Oh no! Error build....'
}
always {
echo 'Jenkins task is done....'
}
}
}
创建pipeline
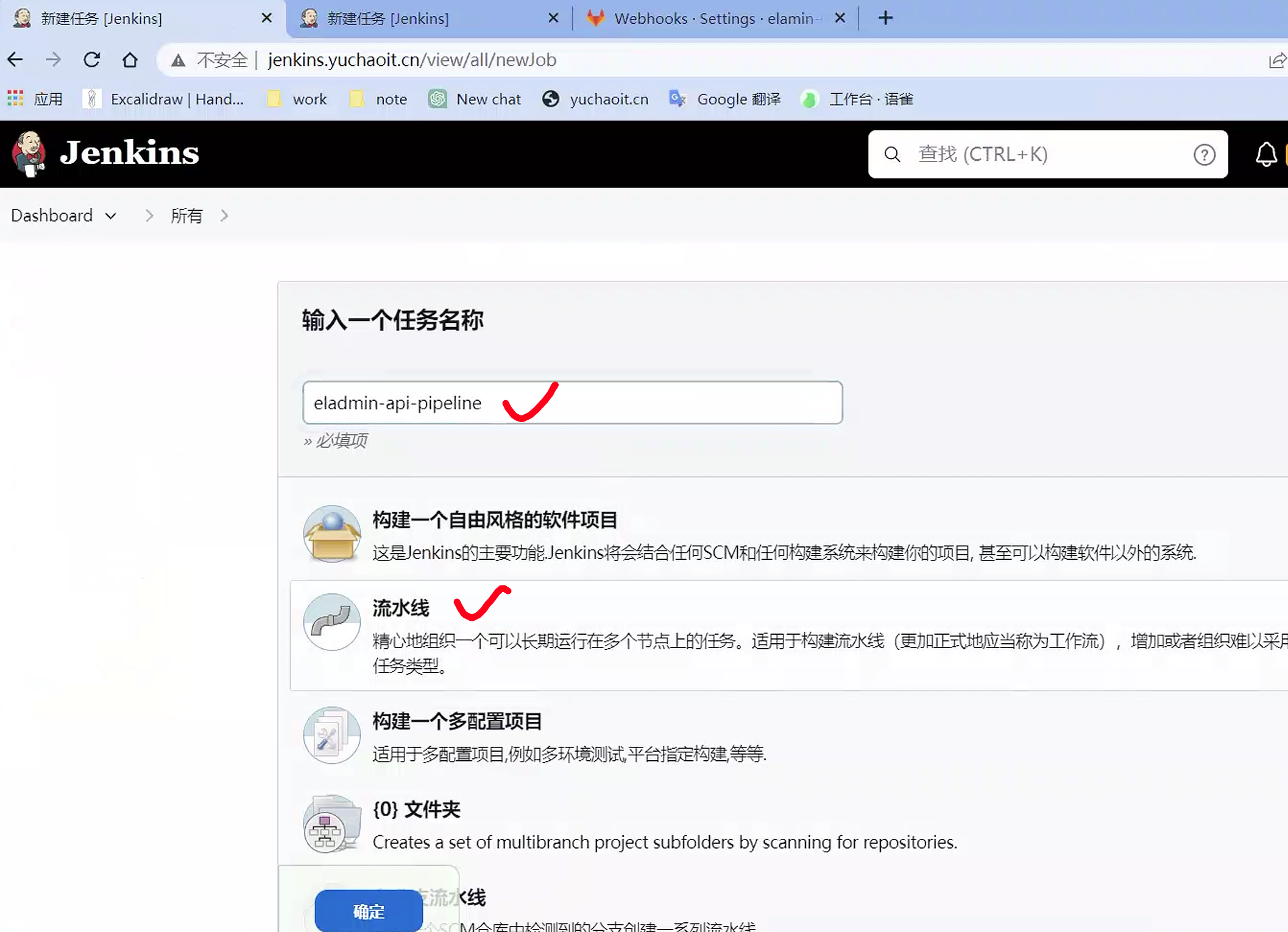
流水线语法参考
例如想获取,pipeline中如何拉取代码的语法
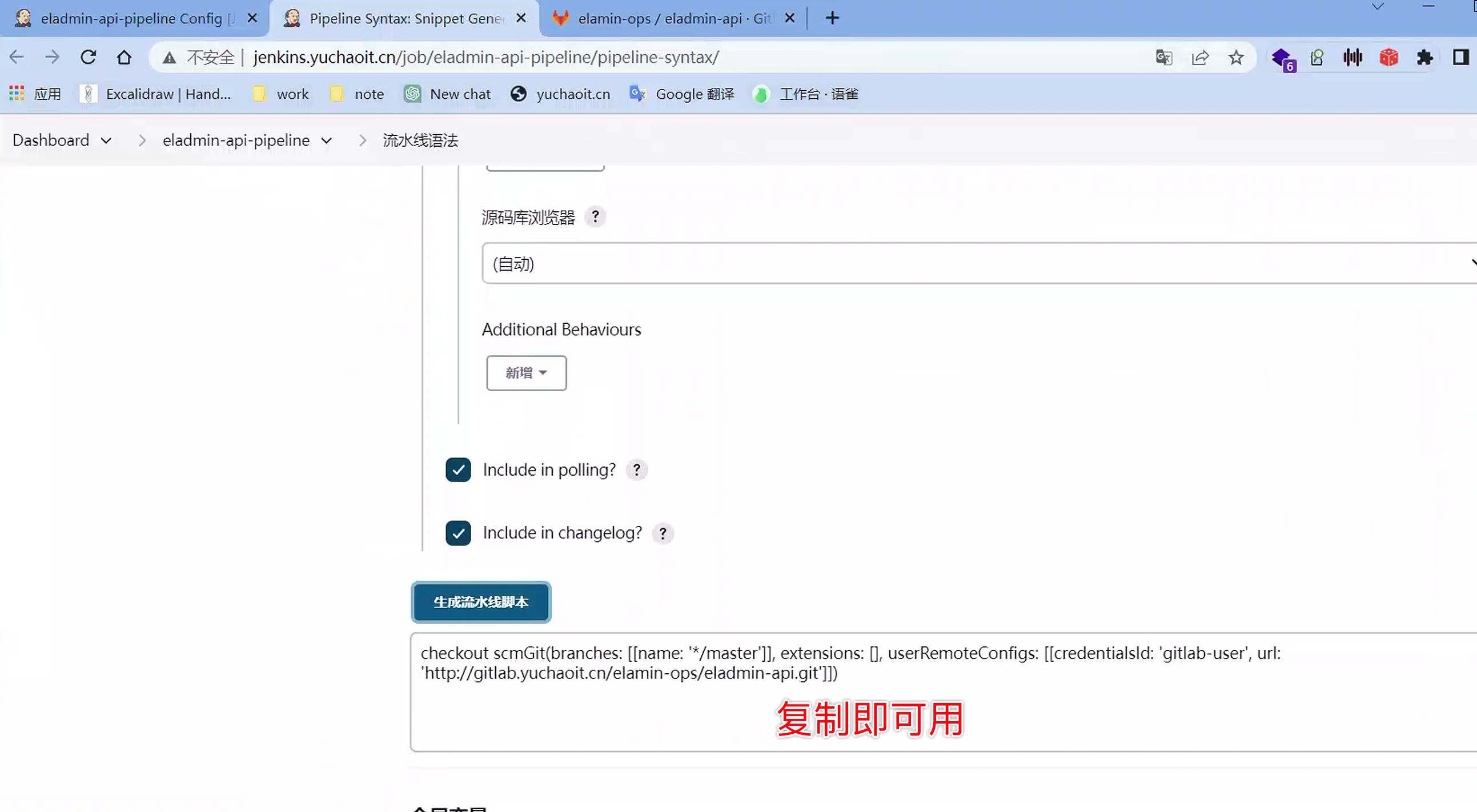
这个脚本就可以用于替换当时我们在页面上的git点击配置。
创建gitlab-webhook
为这个新的job,创建gitlab的webhook,且测试。
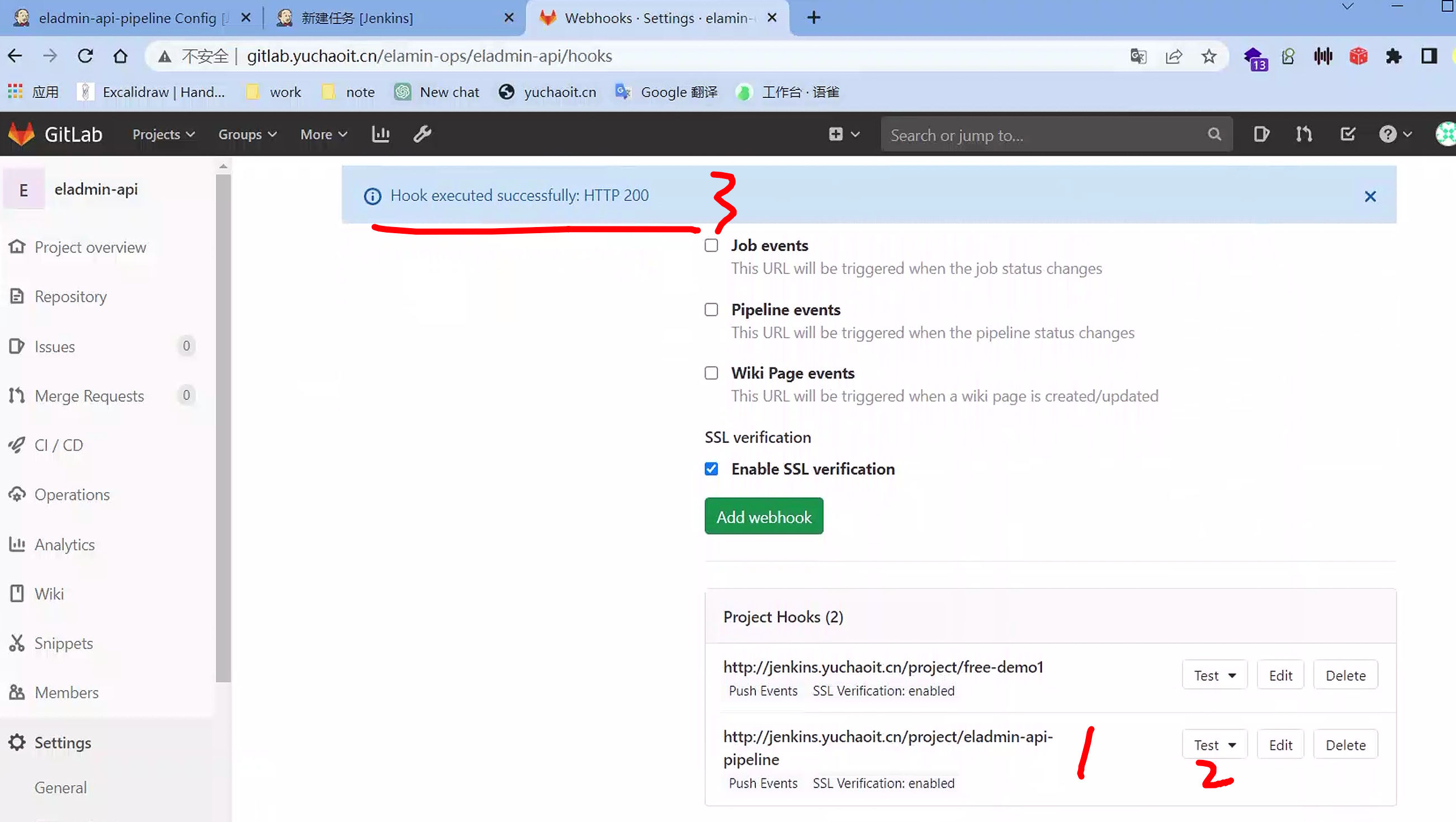
pipeline任务(实践)
# 把dockerfile提交到git仓库
FROM aerialist7/maven-git as builder
WORKDIR /opt/eladmin
COPY . .
RUN mvn clean package
FROM java:8u111
WORKDIR /opt/eladmin
COPY --from=builder /opt/eladmin/eladmin-system/target/eladmin-system-2.6.jar .
CMD [ "sh", "-c", "java -Dspring.profiles.active=prod -jar eladmin-system-2.6.jar" ]
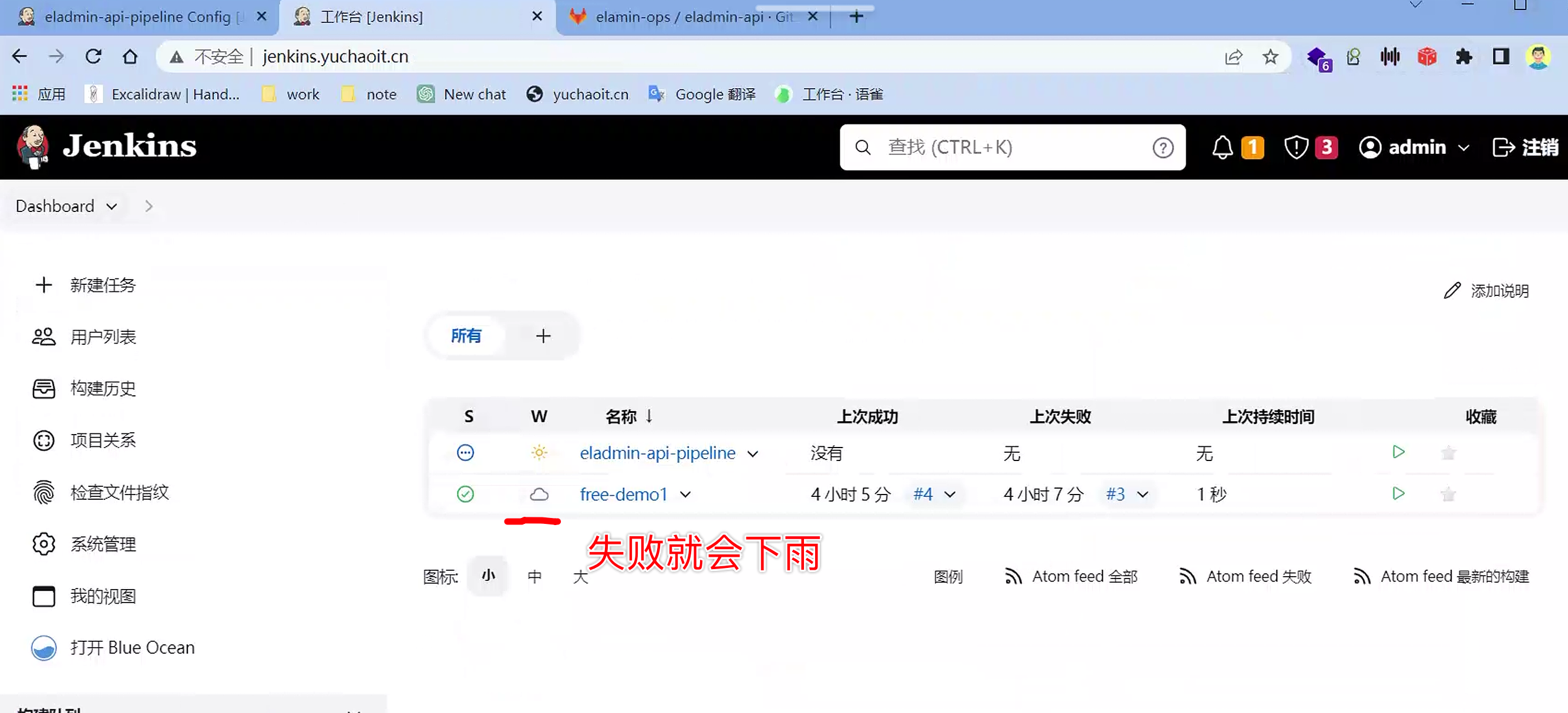
自动触发构建
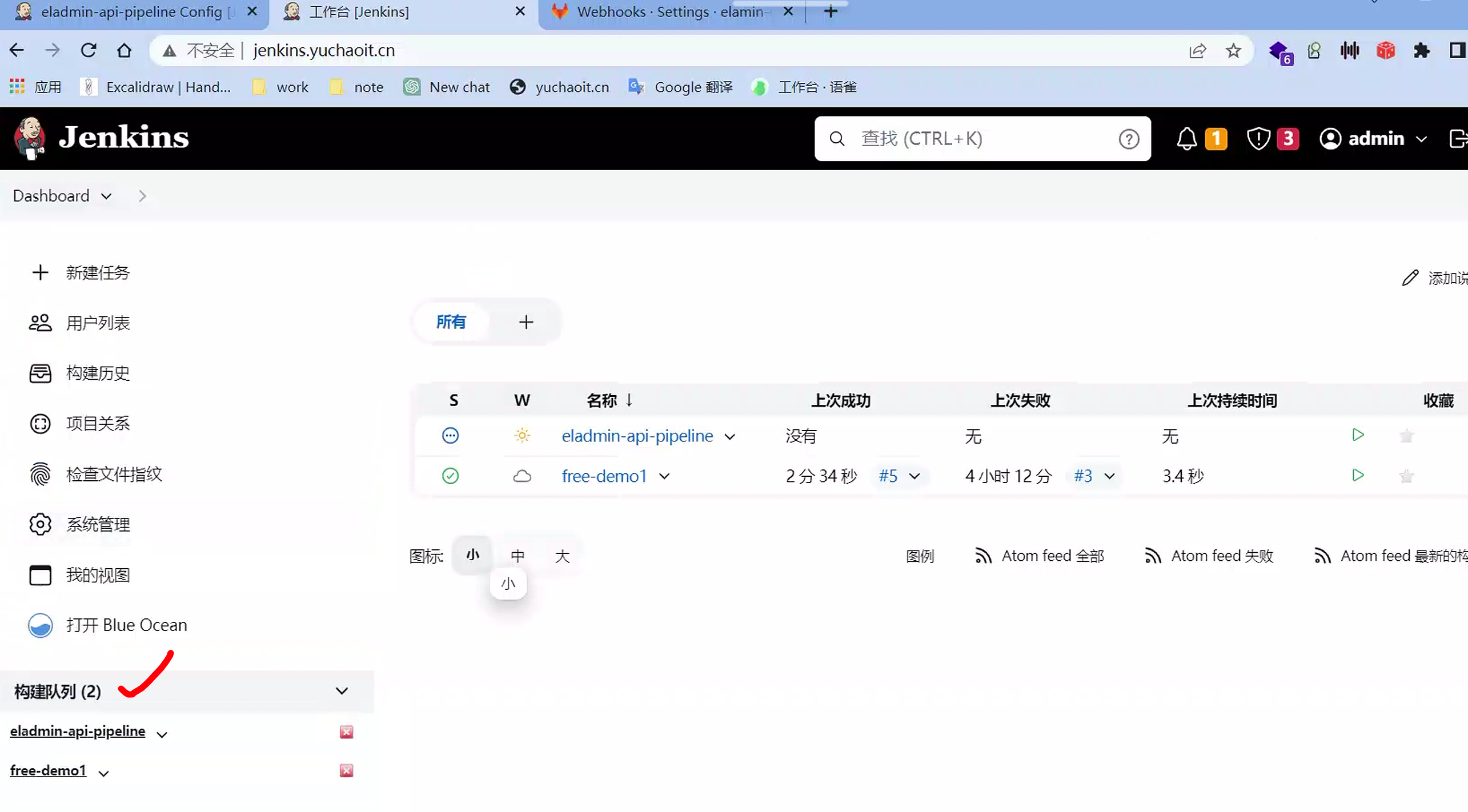
构建结果
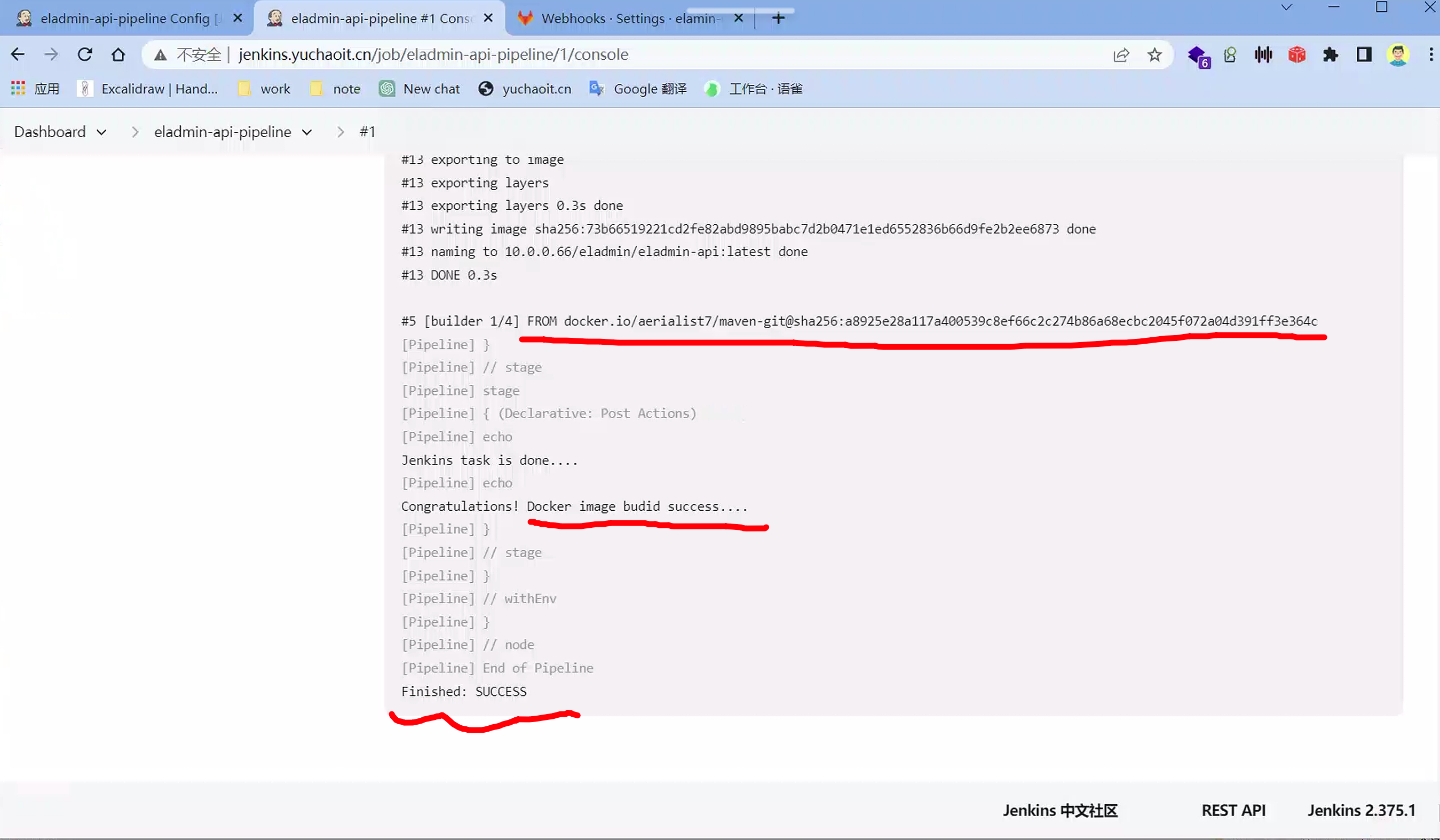
[root@k8s-slave1 /opt/jenkins_jobs]#docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
10.0.0.66/eladmin/eladmin-api latest 73b66519221c 2 minutes ago 774MB
控制台输出
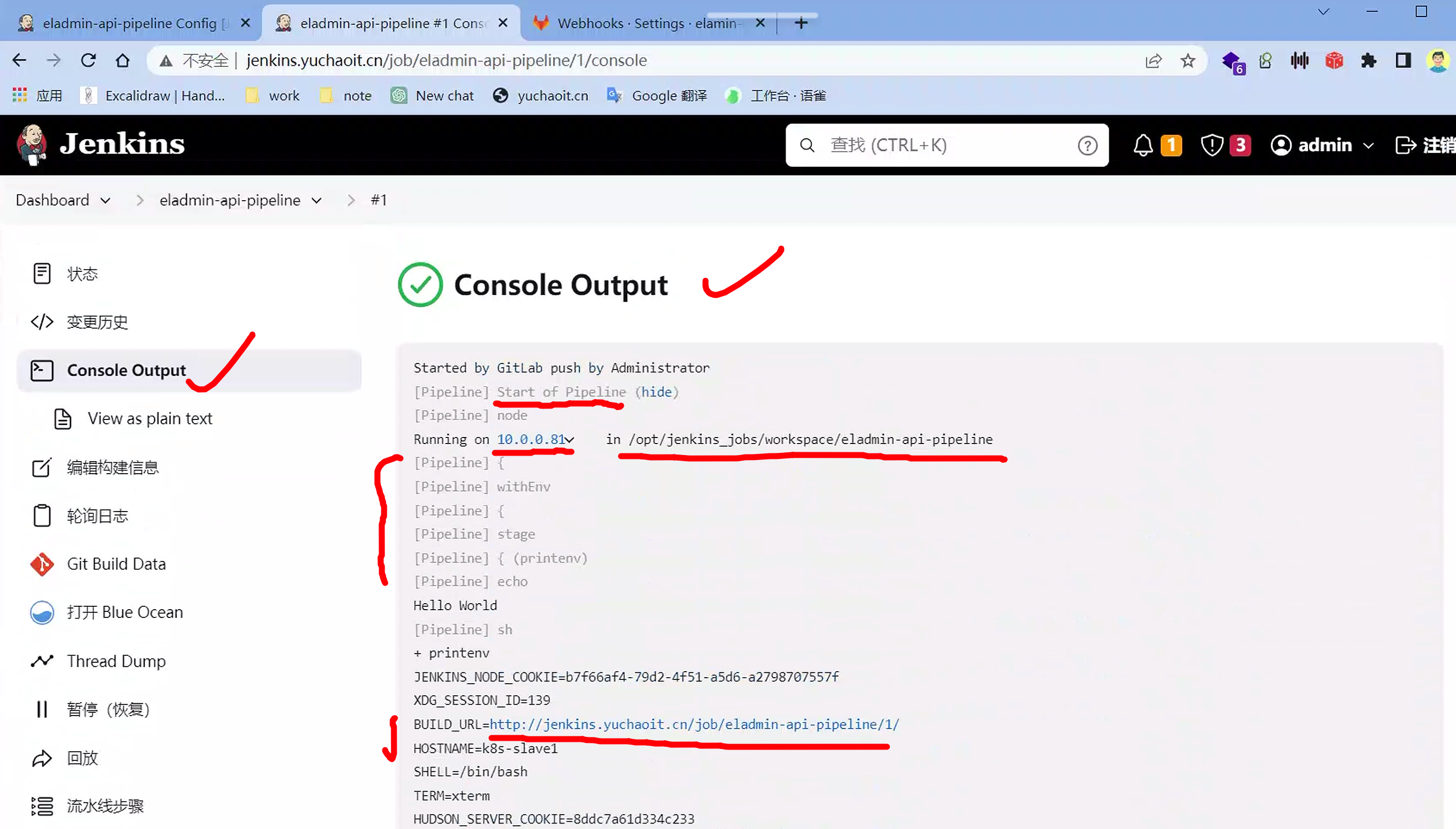
查看blue ocean
Jenkins的Blue Ocean是一个插件,它为Jenkins提供了一个现代化和直观的用户界面,用于构建、测试和部署软件项目。Blue Ocean的目标是改善Jenkins的可用性和用户体验,使得持续集成和持续交付(CI/CD)流水线更易于创建、管理和可视化。
Blue Ocean采用了一种全新的方式来展示Jenkins中的流水线,以图形化和直观的方式呈现。它提供了一个交互式的可视化界面,将整个CI/CD流程以流水线的形式展示出来,每个阶段和步骤都可以清晰地看到。用户可以轻松地浏览整个流水线,查看每个阶段的状态和结果,以及任何错误或警告信息。
Blue Ocean还提供了更强大的可视化和分析工具,帮助用户更好地理解和监控流水线的执行情况。它可以生成图表和报告,展示构建历史、执行时间、成功率等指标,以及构建产物的相关信息。这些工具可以帮助团队更好地识别问题、优化流程,并提高交付速度和质量。
除了可视化界面和分析工具,Blue Ocean还与其他工具和技术集成,以提供更全面的CI/CD解决方案。它支持与Git、GitHub、Bitbucket等代码托管平台的无缝集成,可以自动检测代码变更并触发流水线。同时,它还与Docker和Kubernetes等容器化技术集成,使得构建和部署容器化应用程序更加简单和高效。
总而言之,Jenkins的Blue Ocean是一个现代化的用户界面和工具集,旨在改善Jenkins的可用性和用户体验。它提供了直观的可视化界面、强大的分析工具和与其他技术的集成,帮助开发团队更好地管理和监控他们的CI/CD流水线,从而加速软件交付过程。
我们需要知道的几点:
- 是一个插件, 旨在为Pipeline提供丰富的体验 ;
- 连续交付(CD)Pipeline的复杂可视化,允许快速和直观地了解Pipeline的状态;
- 目前支持的类型仅针对于Pipeline,尚不能替代Jenkins 经典版UI
思考:
- 每个项目都把大量的pipeline脚本写在Jenkins端,对于谁去维护及维护成本是一个问题
- 没法做版本控制
简单理解就好比
你在jenkins里,写的那个pipeline script脚本,就好比一个个的shell脚本
想执行任务,就得把脚本放到机器上,执行,你有100个任务,就要维护100个脚本。
对于Jenkins Pipeline的问题,可以采取以下解决方案
- 将Pipeline脚本存储在代码仓库中:将Pipeline脚本作为代码存储在版本控制系统(如Git)中,使其成为项目代码的一部分。这样可以让开发团队负责维护和更新Pipeline脚本,减轻Jenkins管理员的负担。
- 使用共享库:Jenkins支持自定义共享库,可以将常用的Pipeline步骤和功能封装为可重用的库。通过使用共享库,可以将通用的Pipeline逻辑提取出来,减少重复代码的编写,并且可以由专门的团队或开发者维护。
- 使用Declarative Pipeline语法:Jenkins Pipeline提供了两种语法,即Scripted Pipeline和Declarative Pipeline。Declarative Pipeline是一种声明式的语法,更易于编写和阅读。使用Declarative Pipeline可以简化Pipeline脚本的编写,并且提供了一些内置的功能,如自动参数化和流程控制。
- 使用Jenkinsfile:Jenkinsfile是Pipeline的定义文件,它可以存储在代码仓库中,并与代码一起进行版本控制。将Pipeline的定义和配置统一管理,可以更好地进行版本控制和变更管理,确保Pipeline与代码的一致性。
- 使用Pipeline模板:可以创建Pipeline模板,定义通用的流程和步骤,并将其用作项目的基础。这样可以减少每个项目中重复的Pipeline脚本,并且可以通过参数化来自定义每个项目的特定配置。
- 自动化测试和部署Pipeline:建立完善的测试和部署流程,将测试和部署的步骤集成到Pipeline中,并自动化执行。通过自动化测试和部署,可以减少人工干预,提高效率和可靠性。
通过采取上述措施,可以降低Pipeline脚本维护的成本,实现版本控制,并提高Pipeline的可重用性和可维护性。
pipeline script from SCM
在Jenkins中,SCM代表软件配置管理(Software Configuration Management),也称为源代码管理(Source Code Management)。它是用于管理和控制软件开发过程中源代码和相关资源的工具或系统。
Jenkins通过集成不同的SCM工具,例如Git、Subversion、Mercurial等,使得开发团队能够从代码仓库中检出源代码,并在构建过程中进行版本控制和管理。
Jenkins与SCM之间的集成允许开发人员在构建和部署过程中自动获取最新的代码,并确保每个构建使用的是特定的代码版本。这样可以确保构建的可重复性和一致性,同时提供了更好的追踪能力和问题排查的可能性。
通过与SCM的集成,Jenkins能够实现以下功能:
- 从代码仓库中获取最新的源代码。
- 检测代码的变更,并自动触发构建过程。
- 进行版本控制,记录每个构建使用的代码版本和相关信息。
- 支持分支管理,可以构建和测试不同的代码分支。
- 提供与SCM工具的交互,如检查代码提交历史、创建和合并分支等。
SCM在Jenkins中扮演着关键的角色,它为持续集成和持续交付流程提供了基础,确保代码的可靠性、可追溯性和可控性。
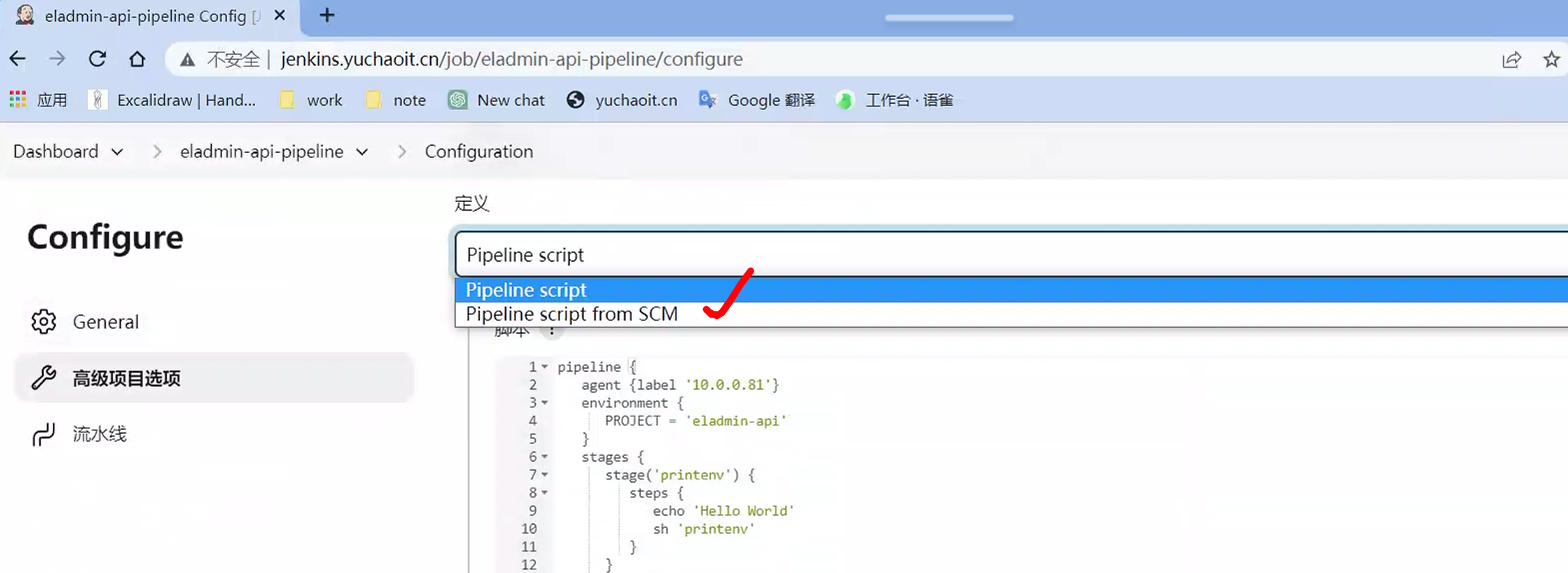
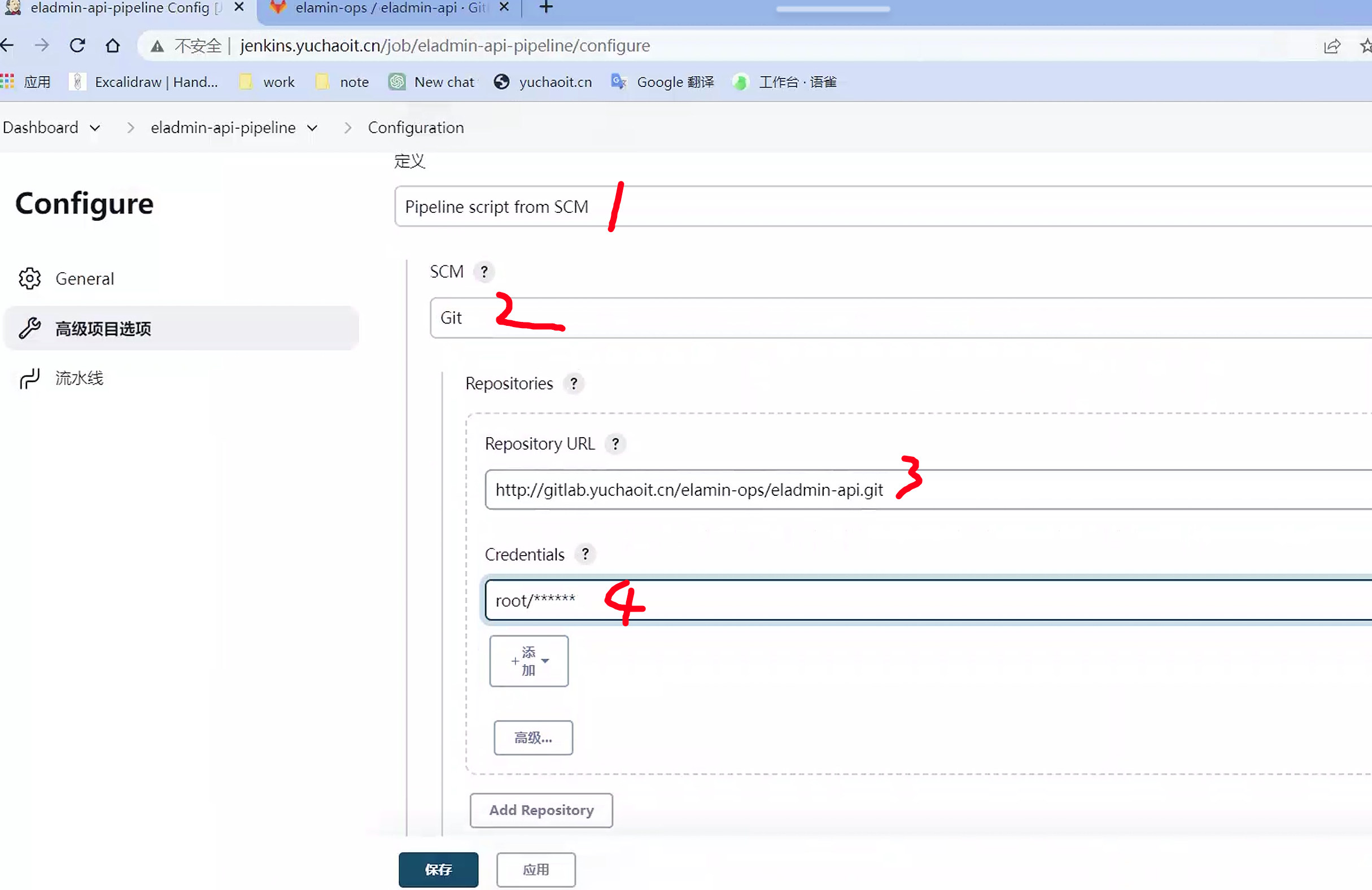
写一个Jenkinsfile
SCM(软件配置管理)和Jenkinsfile在Jenkins中具有密切的关系,彼此相互配合,共同支持持续集成和持续交付流程。
SCM负责管理和控制软件开发过程中的源代码和相关资源。它可以是版本控制系统(如Git、Subversion)或源代码托管平台(如GitHub、Bitbucket)。SCM提供了代码仓库和版本控制的功能,允许开发人员在不同的分支中管理、追踪和协作开发代码。
而Jenkinsfile是Jenkins Pipeline的定义文件,它描述了CI/CD流水线的整个过程,包括构建、测试、部署等阶段以及各个阶段的具体步骤。Jenkinsfile以文本文件的形式存储在代码仓库中,并与源代码一起进行版本控制。
Jenkinsfile与SCM的关系如下:
- 从SCM获取Jenkinsfile:Jenkins可以从代码仓库中获取Jenkinsfile,并根据其中定义的Pipeline配置执行构建过程。这样可以确保Jenkins使用最新的Jenkinsfile,以及与代码仓库中的代码保持一致。
- SCM操作在Jenkinsfile中:Jenkinsfile可以使用SCM相关的步骤或指令来与代码仓库进行交互。例如,可以使用SCM步骤从代码仓库中检出源代码、切换分支、拉取更新等操作。
- Jenkinsfile中定义SCM触发器:Jenkinsfile可以配置SCM触发器,使得当代码仓库中的代码发生变更时,触发Jenkins自动执行相应的流水线。这样可以实现自动化的持续集成。
通过将Jenkinsfile与SCM结合使用,开发团队可以将CI/CD流程的定义与代码存储在同一位置,实现流水线的版本控制和追踪,确保构建过程与源代码的一致性。同时,SCM的变更触发器和操作步骤可以与Jenkinsfile紧密集成,实现代码变更的自动触发和持续集成的实现。
把刚才的pipeline脚本,写到这个Jenkinsfile里,放到git仓库
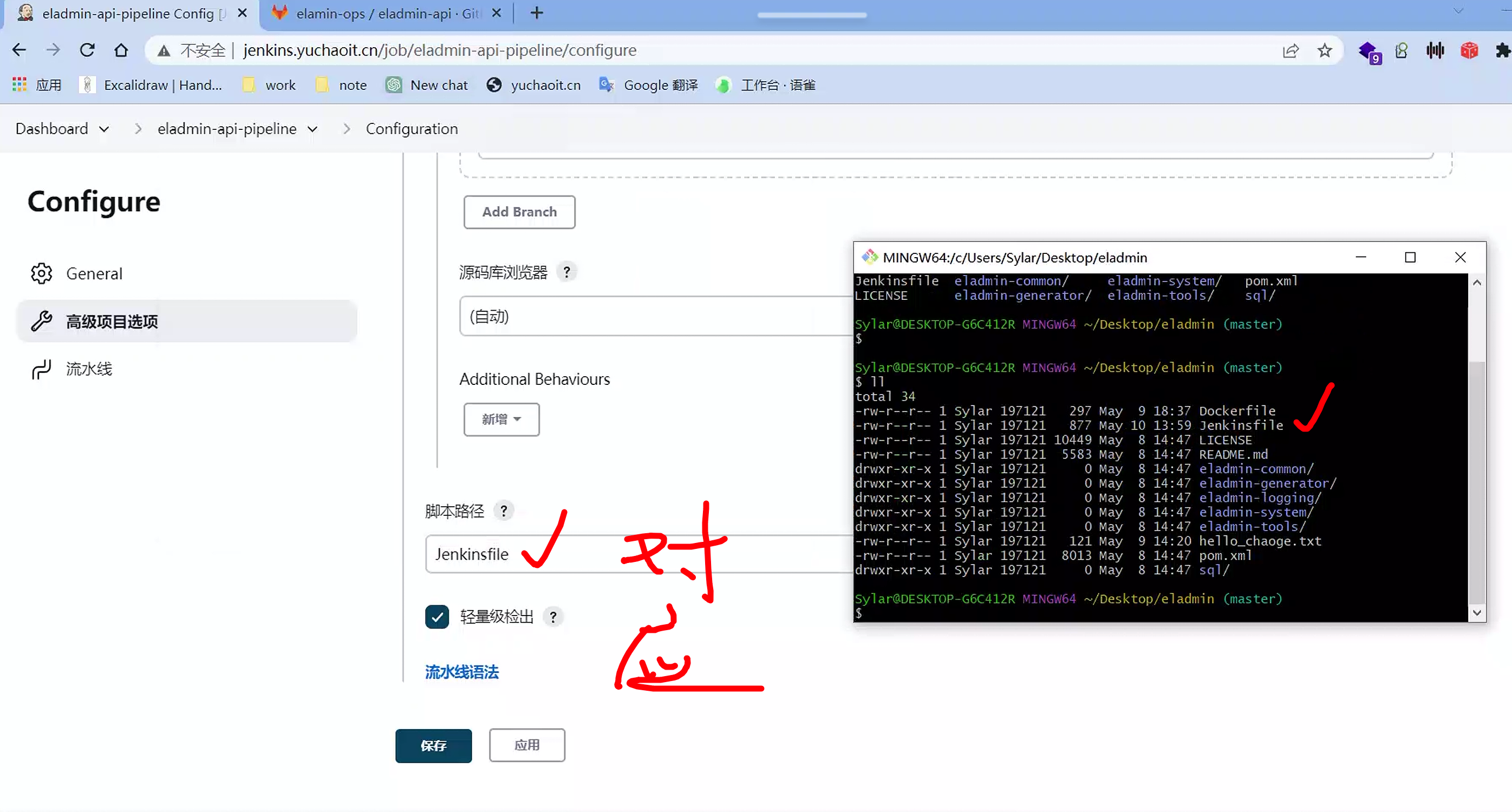
注意整理的脚本路径,名字保持一致,或者写成你项目里的脚本一致
此时,git同时管理了代码、以及Jenkinsfile,完成同时对源代码,以及构建流程的高度自动化。
解决脚本可移植性、版本管理最大的问题。
再次演示CI
git push ,gitlab,webook,自动触发jenkins构建
注意agent节点是否正常
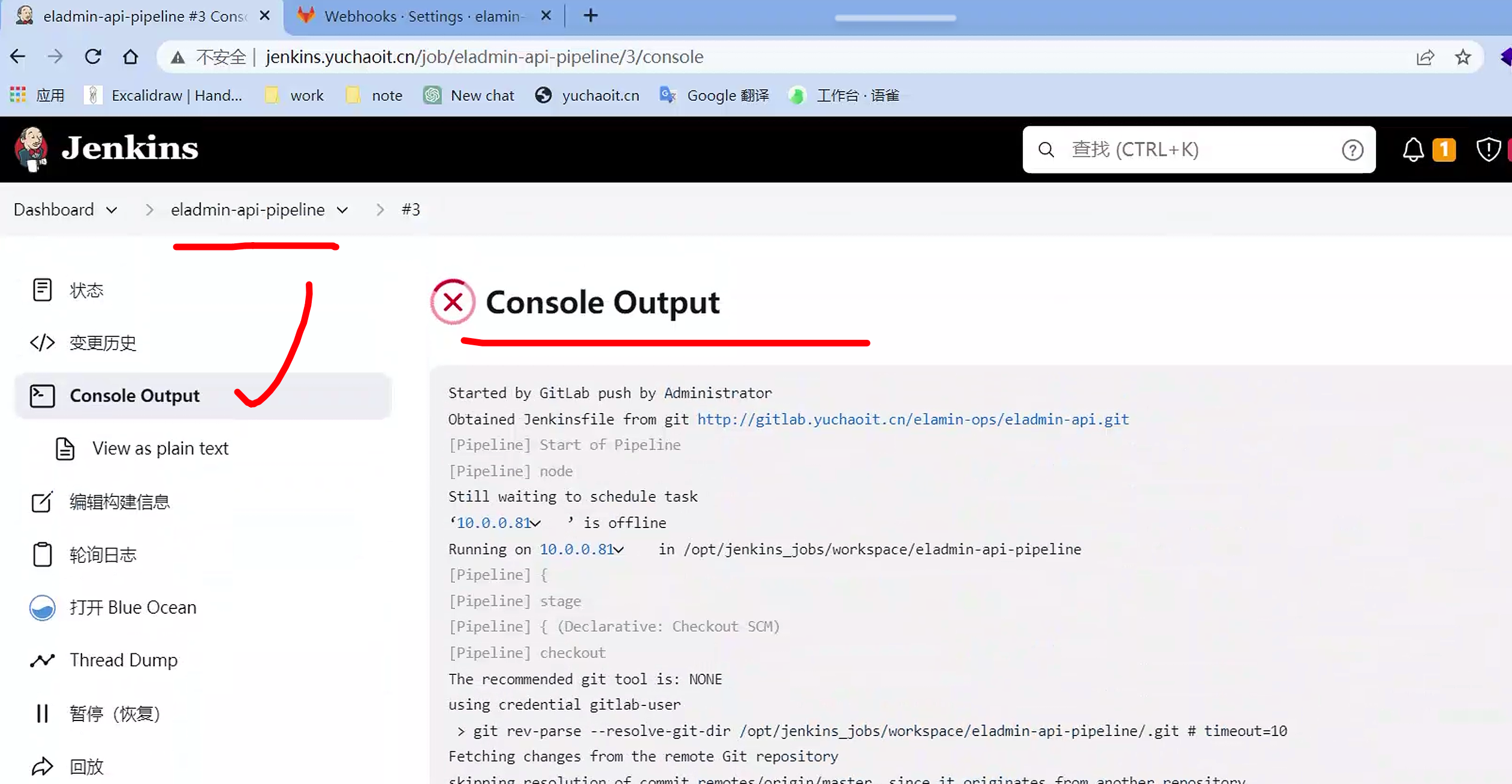
也可以在blue ocean里看结果
是否jenkinsfile工作正常,看看,是否读取到脚本里的几个阶段就行
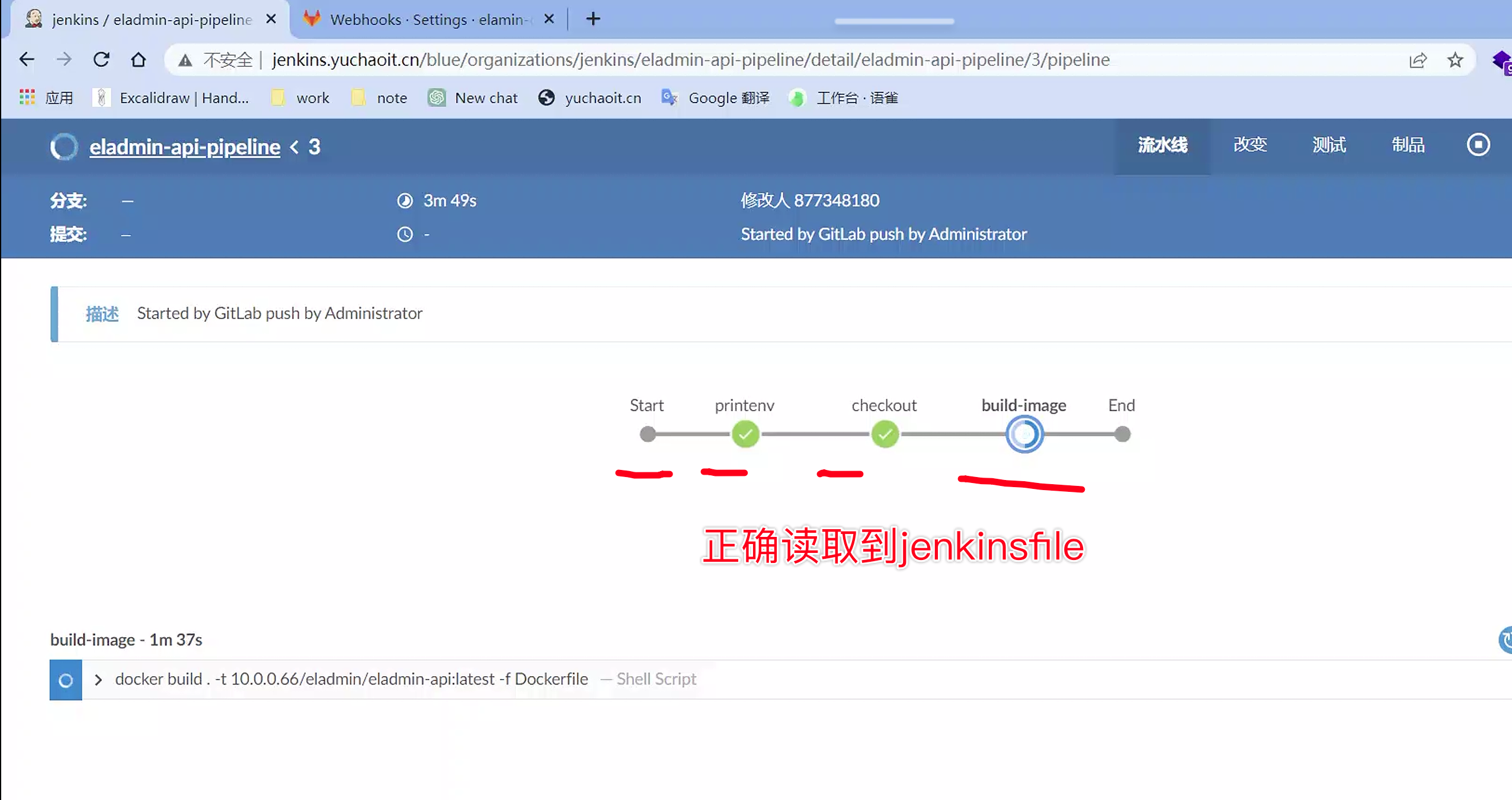
构建结果
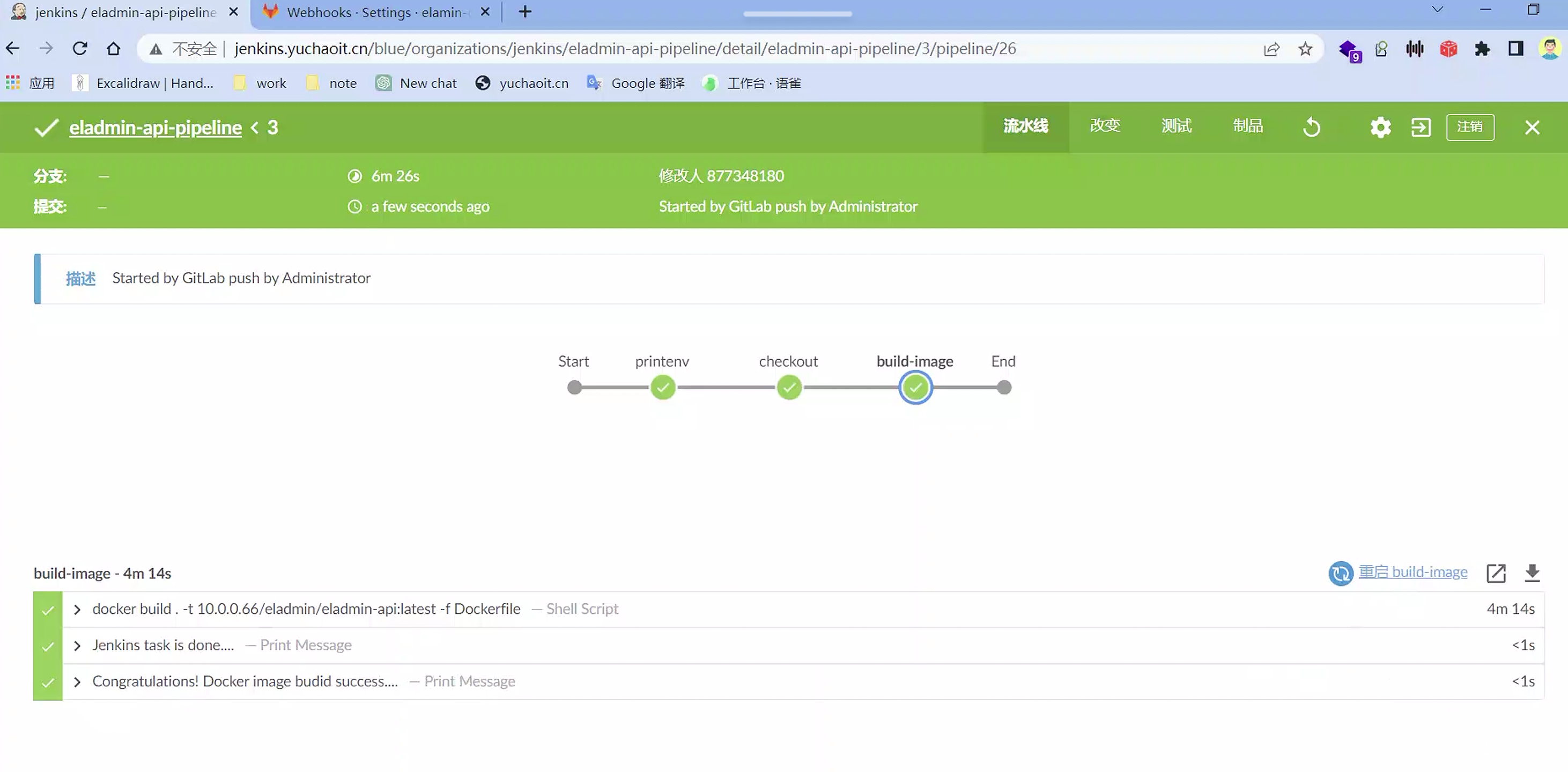
Jenkinsfile实战java
很明显,jenkins进阶的玩法,就是写Jenkinsfile定义复杂CICD任务了。
Jenkins Pipeline提供了一种将持续交付流程定义为代码的方式,通过编写Jenkinsfile来描述整个流水线的配置和步骤。Jenkinsfile是一个文本文件,可以将其放置在项目的源代码控制库中,使其与代码的版本控制一起管理。
Jenkinsfile采用声明性或脚本式语法编写,用于定义各个阶段和步骤,包括构建、测试、部署等。它可以被视为一个脚本或程序,可以利用Jenkins Pipeline提供的丰富的库和插件来构建复杂的交付流程。
将Jenkinsfile纳入源代码控制的好处是:
- 可追溯性和可重复性:Jenkinsfile与代码一起进行版本控制,确保每个构建使用的是特定版本的流水线配置。这样可以实现构建的可追溯性和可重复性,确保不同环境中使用相同的构建流程。
- 可扩展性和维护性:将Jenkinsfile放入源代码控制库中,使得整个交付流程的配置和变更与代码一起管理。开发团队可以根据项目需求进行扩展和定制,并通过代码审查和合并请求来维护和更新Jenkinsfile。
- 集中化管理:将Jenkinsfile存储在源代码控制库中,可以实现对所有项目的交付流程的集中化管理。团队成员可以轻松访问和修改Jenkinsfile,确保流水线的一致性和标准化。
- 可复用性:Jenkinsfile可以在不同的项目中进行共享和复用。通过定义通用的构建和部署步骤,可以在多个项目中重复使用Jenkinsfile,并减少重复劳动。
总之,将Jenkins Pipeline的定义写入Jenkinsfile并将其纳入源代码控制库,可以将交付流程变为可维护和可追溯的代码,并为团队提供更好的可扩展性、集中化管理和代码复用的机会。
优化脚本思路
- 优化代码检出阶段:如果你已经通过SCM配置了Jenkins的代码检出步骤,那么确实没有必要在Pipeline中再次指定代码检出。可以简单地移除Pipeline中的代码检出步骤,让Jenkins使用SCM配置中的设置来进行代码检出。
- 构建镜像的tag使用git的commit id:你可以通过在Pipeline中获取Git的commit id来作为构建镜像的tag。使用Git插件或执行Git命令获取commit id,并将其传递给构建镜像的步骤中。
- 丰富通知内容:Jenkins Pipeline提供了多种通知方式,如邮件、Slack等。你可以根据需求,自定义通知内容,包括构建状态、测试结果、部署状态等。通过使用Jenkins提供的通知插件或编写自定义的通知脚本,可以定制通知内容以满足团队的需求。
- 编译和构建拆分不同的stage,增加构建速度:如果你的构建过程包含多个耗时的步骤,可以将其拆分为不同的stage,使得可以并行执行。通过并行执行可以提高构建速度,尤其是在拥有多个构建代理节点的情况下。可以在Pipeline中使用
parallel指令将不同的构建步骤定义为并行执行。
优化后的脚本
- 新增了一个名为
mvn package的阶段:在这个阶段中,使用sh命令运行mvn clean package来执行Maven的清理和打包操作。 - 在
build-image阶段中添加了retry块:使用retry块可以在命令执行失败时进行重试。在这个示例中,通过retry(2)将构建镜像的命令docker build设置为最多重试两次。
除此之外,其他部分保持不变,包括代理节点、环境变量、阶段和后置操作的定义。
这个更新后的Pipeline将在代理节点上执行mvn package阶段,对项目进行Maven的清理和打包操作,然后继续执行构建镜像的步骤。同时,在构建镜像的步骤中添加了重试机制,以增加命令的可靠性。
后置操作部分仍然包括构建成功和失败时发送通知的逻辑,以及无论构建结果如何都会执行的部分。
pipeline {
agent { label '10.0.0.81'}
environment {
PROJECT = 'eladmin-api'
}
stages {
stage('printenv') {
steps {
echo 'Hello World'
sh 'printenv'
}
}
stage('checkout') {
steps {
checkout scm
}
}
stage('mvn package') {
steps {
sh 'mvn clean package' # 增加打包阶段,在agent机器上
}
}
stage('build-image') {
steps {
retry(2) { sh 'docker build . -t 10.0.0.66/eladmin/eladmin-api:${GIT_COMMIT} -f Dockerfile'}
}
}
}
post {
success {
echo 'Congratulations!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=46e6650e93393194e435d74372eeb4ffe8a0143ed9a38598244655ca8c4c4b14' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "😄👍构建成功👍😄\n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
failure {
echo 'Oh no!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=46e6650e93393194e435d74372eeb4ffe8a0143ed9a38598244655ca8c4c4b14' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "😖❌构建失败❌😖\n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
always {
echo 'I will always say Hello again!'
}
}
}
优化dockerfile
构建java的CICD,mvn的优化是必须的,防止反复构建,下载依赖。
将mvn的构建过程,放到agent机器上去,只需要拿最后的所有的mvn依赖即可。
FROM java:8u111
WORKDIR /opt/eladmin
COPY eladmin-system/target/ .
CMD [ "sh", "-c", "java -Dspring.profiles.active=prod -jar eladmin-system-2.6.jar" ]
agent修改
既然mvn放在了agent机器上编译,就得需要mvn的环境。
安装apache-maven-3.6.3-bin.tar.gz
# 解压,配置maven
[root@k8s-slave1 ~]#ls
agent.jar agent.sh anaconda-ks.cfg apache-maven-3.6.3-bin.tar.gz init2.sh init.sh nohup.out secret-file test.log t.log
[root@k8s-slave1 ~]#
# 修改mvn源
[root@k8s-slave1 ~/apache-maven-3.6.3]#vim conf/settings.xml
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
# 以及注意加上一个本地依赖的设置
# 如果本地没有,才会去阿里源拉取,且到本地找,就不会反复下载了
通过配置 localRepository 元素,你可以指定 Maven 下载和缓存依赖项的位置。当 Maven 构建项目时,它会检查本地仓库中是否存在所需的依赖项。如果不存在,它会从远程仓库下载依赖项,并将其存储在本地仓库中供以后使用。
46 <settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
47 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
48 xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
49
50 <localRepository>/opt/maven-repo</localRepository>
# 配置mvn软连接
[root@k8s-slave1 ~]#ln -s /root/apache-maven-3.6.3/bin/mvn /usr/bin/
[root@k8s-slave1 ~]#
[root@k8s-slave1 ~]#mvn -version
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /root/apache-maven-3.6.3
Java version: 11.0.19, vendor: Red Hat, Inc., runtime: /usr/lib/jvm/java-11-openjdk-11.0.19.0.7-1.el7_9.x86_64
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-862.el7.x86_64", arch: "amd64", family: "unix"
[root@k8s-slave1 ~]#
构建结果
# git push -u origin
# 查看jenkins 构建任务

检查maven本地依赖
首次构建,mvn会下载依赖,并且放入本地定义好的目录,下一次构建就不会重复下载,提示效率。
[root@k8s-slave1 /opt/maven-repo]#ls
antlr backport-util-concurrent cn commons-configuration commons-logging jakarta mysql org
aopalliance ch com commons-io dom4j javax net xerces
asm classworlds commons-codec commons-lang io junit nl xml-apis
[root@k8s-slave1 /opt/maven-repo]#
检查agent构建的jar包
[root@k8s-slave1 /opt/jenkins_jobs/workspace/eladmin-api-pipeline]#ls eladmin-system/target/
classes eladmin-system-2.6.jar.original generated-test-sources maven-status
eladmin-system-2.6.jar generated-sources maven-archiver test-classes
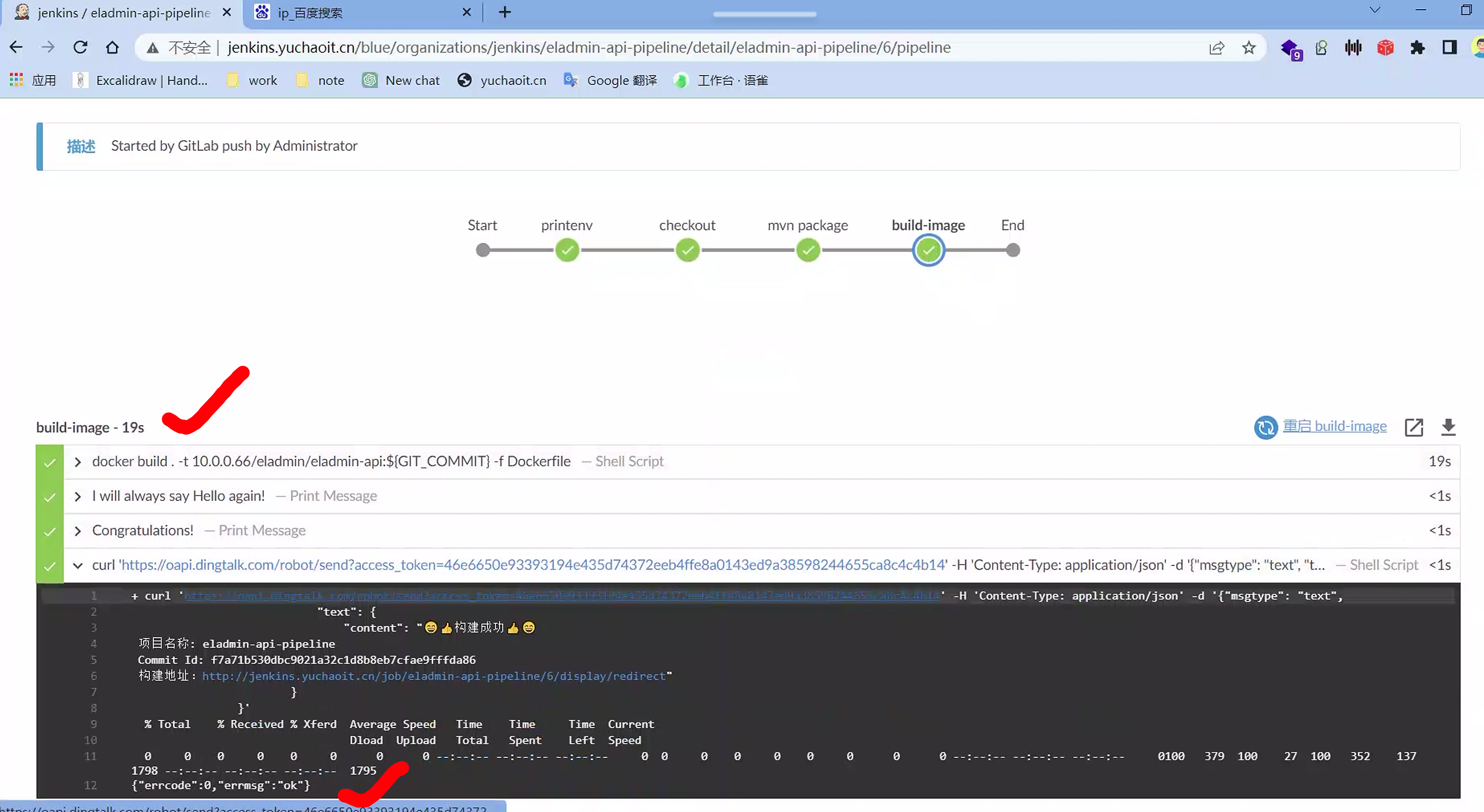
钉钉看到结果
重复构建此java项目后,由于maven依赖本地已经有了,不会重复构建,可以立即看到结果
使用k8s做部署
如何通过jenkins去部署系统到k8s,其实就是解决2个问题
- yaml,deployment,配置文件,放到gitlab仓库里,和代码一起版本发布
- 证书
# 拿到yaml
# [root@k8s-master ~]#kubectl -n yuchao get deployments.apps eladmin-api -oyaml > eladmin-api-deploy.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: eladmin-api
namespace: yuchao
spec:
replicas: 5
selector:
matchLabels:
app: eladmin-api
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: eladmin-api
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- eladmin-web
topologyKey: kubernetes.io/hostname
weight: 100
containers:
- env:
- name: DB_HOST
valueFrom:
configMapKeyRef:
key: DB_HOST
name: eladmin
- name: REDIS_HOST
valueFrom:
configMapKeyRef:
key: REDIS_HOST
name: eladmin
- name: REDIS_PORT
valueFrom:
configMapKeyRef:
key: REDIS_PORT
name: eladmin
- name: DB_USER
valueFrom:
secretKeyRef:
key: DB_USER
name: eladmin-secret
- name: DB_PWD
valueFrom:
secretKeyRef:
key: DB_PWD
name: eladmin-secret
image: 10.0.0.66:5000/eladmin:v2
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 20
periodSeconds: 15
successThreshold: 1
tcpSocket:
port: 8000
timeoutSeconds: 3
name: eladmin-api
ports:
- containerPort: 8000
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /auth/code
port: 8000
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 15
successThreshold: 1
timeoutSeconds: 3
resources:
limits:
cpu: "2"
memory: 4Gi
requests:
cpu: 50m
memory: 200Mi
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: registry-10.0.0.66
restartPolicy: Always
git本地仓库修改
参考写法,创建manifests目录,放入yaml
"manifests" 是一个常用的术语,特别是在容器编排和部署工具(例如 Kubernetes)的上下文中。它通常指代一组配置文件或描述文件,用于定义应用程序、服务或基础设施的状态和规范。
在 Kubernetes 中,"manifests" 是一组 YAML 或 JSON 格式的文件,用于描述部署、服务、配置和其他资源的规范。这些文件包含了关于容器镜像、副本数、网络设置、卷挂载等方面的信息,以指导 Kubernetes 如何创建和管理相应的资源。
"manifests" 目录通常是一个包含了所有与应用程序或服务相关的 Kubernetes 配置文件的目录。这些配置文件包括部署(Deployment)、服务(Service)、配置映射(ConfigMap)、持久卷声明(PersistentVolumeClaim)等。
总之,"manifests" 是指描述应用程序、服务或基础设施的规范文件集合,用于在容器编排和部署工具中定义和管理这些资源。

优化jenkinsfile凭据
Jenkins 的 "Manage Credentials" 是指 Jenkins 管理凭据(Credentials)的功能。凭据是用于身份验证、访问控制和其他安全操作的敏感信息,例如用户名、密码、密钥、证书等。
Jenkins 的 "Manage Credentials" 功能允许管理员集中管理这些敏感信息,并将其应用于 Jenkins 系统中的不同部分和作业。
通过 "Manage Credentials",管理员可以执行以下操作:
- 添加凭据:管理员可以添加新的凭据到 Jenkins 中。这些凭据可以是用户名/密码对、SSH 密钥、证书等。管理员可以指定凭据的类型和相关属性,并为其提供敏感信息。
- 编辑和更新凭据:管理员可以编辑和更新已存在的凭据。这可以包括修改用户名、密码、密钥等信息,或者更新证书和其他敏感数据。
- 删除凭据:如果不再需要某个凭据,管理员可以从 Jenkins 中删除它。这可以帮助确保不再使用或泄露不需要的敏感信息。
- 凭据域(Credentials Domains)管理:Jenkins 允许管理员为不同的凭据定义域,以便更好地组织和管理凭据。域可以根据需要进行创建、编辑和删除,并且可以用于对特定的作业或系统组件进行访问控制。
- 凭据的用途:管理员可以将凭据分配给不同的 Jenkins 作业、插件或系统组件。这可以确保只有具有正确凭据的用户或作业可以访问受保护的资源,提高系统的安全性。
通过 "Manage Credentials" 功能,管理员可以轻松地管理和维护 Jenkins 中的敏感凭据,提供更好的安全性和访问控制,同时简化对敏感信息的集中管理。
优化思路
上述Jenkinsfile中存在的问题是敏感信息使用明文,暴漏在代码中,如何管理流水线中的敏感信息(包含账号密码),之前我们在对接gitlab的时候,需要账号密码,已经使用过凭据来管理这类敏感信息,同样的,我们可以使用凭据来存储钉钉的token信息,那么,创建好凭据后,如何在Jenkinsfile中获取已有凭据的内容?
Jenkins 的声明式流水线语法有一个 credentials() 辅助方法(在environment 指令中使用),它支持 secret 文本,带密码的用户名,以及 secret 文件凭据。
下面的流水线代码片段展示了如何创建一个使用带密码的用户名凭据的环境变量的流水线。
在该示例中,带密码的用户名凭据被分配了环境变量,用来使你的组织或团队以一个公用账户访问 Bitbucket 仓库;这些凭据已在 Jenkins 中配置了凭据 ID jenkins-bitbucket-common-creds。
当在 environment 指令中设置凭据环境变量时:
environment {
BITBUCKET_COMMON_CREDS = credentials('jenkins-bitbucket-common-creds')
}
上面这段配置,实际设置了下面的三个环境变量:
BITBUCKET_COMMON_CREDS- 包含一个以冒号分隔的用户名和密码,格式为username:password。BITBUCKET_COMMON_CREDS_USR- 附加的一个仅包含用户名部分的变量。BITBUCKET_COMMON_CREDS_PSW- 附加的一个仅包含密码部分的变量。
有了环境变量,就可以取值使用。
pipeline {
agent {
// 此处定义 agent 的细节
}
environment {
//顶层流水线块中使用的 environment 指令将适用于流水线中的所有步骤。
BITBUCKET_COMMON_CREDS = credentials('jenkins-bitbucket-common-creds')
}
stages {
stage('Example stage 1') {
//在一个 stage 中定义的 environment 指令只会将给定的环境变量应用于 stage 中的步骤。
environment {
BITBUCKET_COMMON_CREDS = credentials('another-credential-id')
}
steps {
//
}
}
stage('Example stage 2') {
steps {
//
}
}
}
}
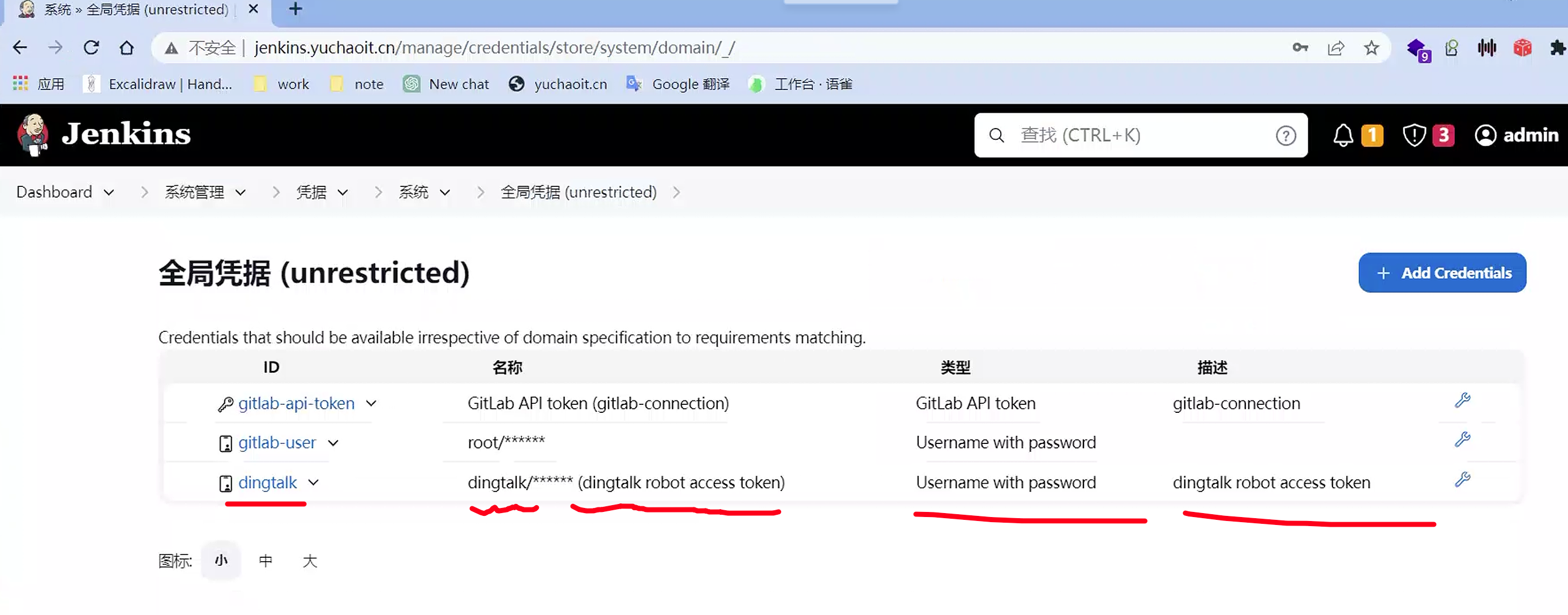
创建凭据

查看全局凭证
yaml文件优化
除了密码、还有镜像名字,都更换为变量
- name: DB_PWD
valueFrom:
secretKeyRef:
key: DB_PWD
name: eladmin-secret
image:
imagePullPolicy: IfNotPresent
livenessProbe:
然后去Jenkinsfile里替换就行
Jenkinsfile做改造
这是一个 Jenkins Pipeline 的示例代码,它描述了一个包含多个阶段的部署流水线。下面是对这段代码的解释:
agent { label '10.0.0.81'}:指定 Jenkins 流水线运行的代理节点为 IP 地址为 '10.0.0.81' 的节点。environment部分:定义了流水线中使用的环境变量。IMAGE_REPO设置为镜像仓库的地址,DINGTALK_CREDS设置为凭据中名为 'dingtalk' 的凭据。stages部分:定义了流水线中的阶段。a.
printenv阶段:打印环境变量并执行printenv命令。b.
check阶段:检出代码,checkout scm从源代码管理工具中检出代码。c.
build-image阶段:构建 Docker 镜像。使用docker build命令构建镜像,并将镜像标签设置为${IMAGE_REPO}:${GIT_COMMIT}。d.
push-image阶段:推送 Docker 镜像到镜像仓库。使用docker push命令将镜像推送到${IMAGE_REPO}:${GIT_COMMIT}。e.
deploy阶段:部署应用程序。使用sed命令替换 manifests 目录中的模板文件中的` 占位符为${IMAGE_REPO}:${GIT_COMMIT}。然后使用kubectl apply` 命令应用更新后的 manifests 文件。post部分:定义了流水线执行完成后的后置操作。a.
success部分:当流水线成功执行时,发送通知到钉钉群组,内容包括项目信息和构建状态。b.
failure部分:当流水线执行失败时,发送通知到钉钉群组,内容包括项目信息和构建状态。c.
always部分:无论流水线执行成功还是失败,始终输出 'I will always say Hello again!'。
这个流水线示例展示了一个基本的部署流程,包括构建镜像、推送镜像和应用程序部署,并在流水线执行的不同阶段执行不同的操作和通知。您可以根据实际需求进行修改和定制。
pipeline {
agent { label '10.0.0.81'}
environment {
PROJECT = "eladmin-api"
IMAGE_REPO = "10.0.0.66:5000/eladmin/eladmin-api"
DINGTALK_CREDS = credentials('dingtalk')
}
stages {
stage('printenv') {
steps {
echo 'Hello World'
sh 'printenv'
}
}
stage('check') {
steps {
checkout scm
}
}
stage('build-image') {
steps {
retry(2) { sh 'docker build . -t ${IMAGE_REPO}:${GIT_COMMIT}'}
}
}
stage('push-image') {
steps {
retry(2) { sh 'docker push ${IMAGE_REPO}:${GIT_COMMIT}'}
}
}
stage('deploy') {
steps {
sh "sed -i 's##${IMAGE_REPO}:${GIT_COMMIT}#g' manifests/*"
timeout(time: 1, unit: 'MINUTES') {
sh "kubectl apply -f manifests/"
}
}
}
}
post {
success {
echo 'Congratulations!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=${DINGTALK_CREDS_PSW}' \
-H 'Content-Type: application/json' \
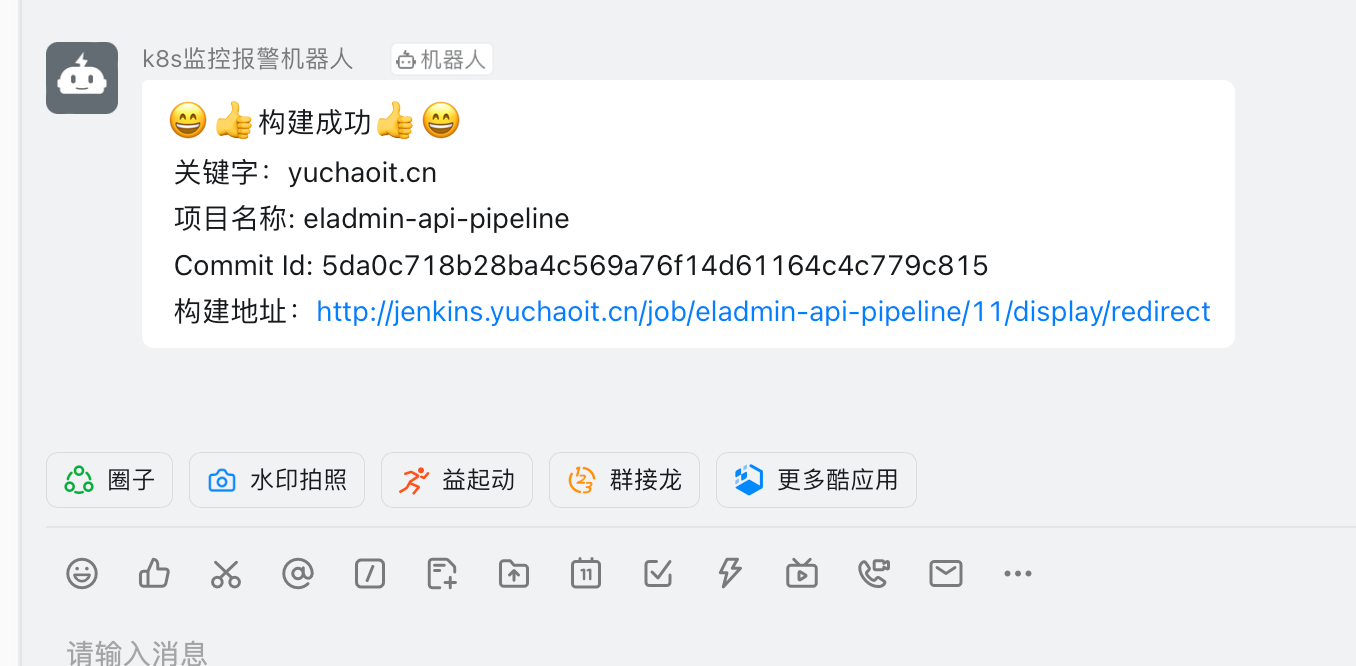
-d '{"msgtype": "text",
"text": {
"content": "😄👍构建成功👍😄\n 关键字:yuchaoit.cn \n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
failure {
echo 'Oh no!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=${DINGTALK_CREDS_PSW}' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "😖❌构建失败❌😖\n 关键字:yuchaoit.cn \n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
always {
echo 'I will always say Hello again!'
}
}
}
修改agent机器的kubectl权限
[root@k8s-slave1 ~]#scp -r k8s-master:/root/.kube/ /root/
# 确认可以用了
[root@k8s-slave1 ~]#kubectl top no
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 91m 2% 1102Mi 11%
k8s-slave1 40m 1% 2058Mi 21%
k8s-slave2 61m 1% 11958Mi 75%
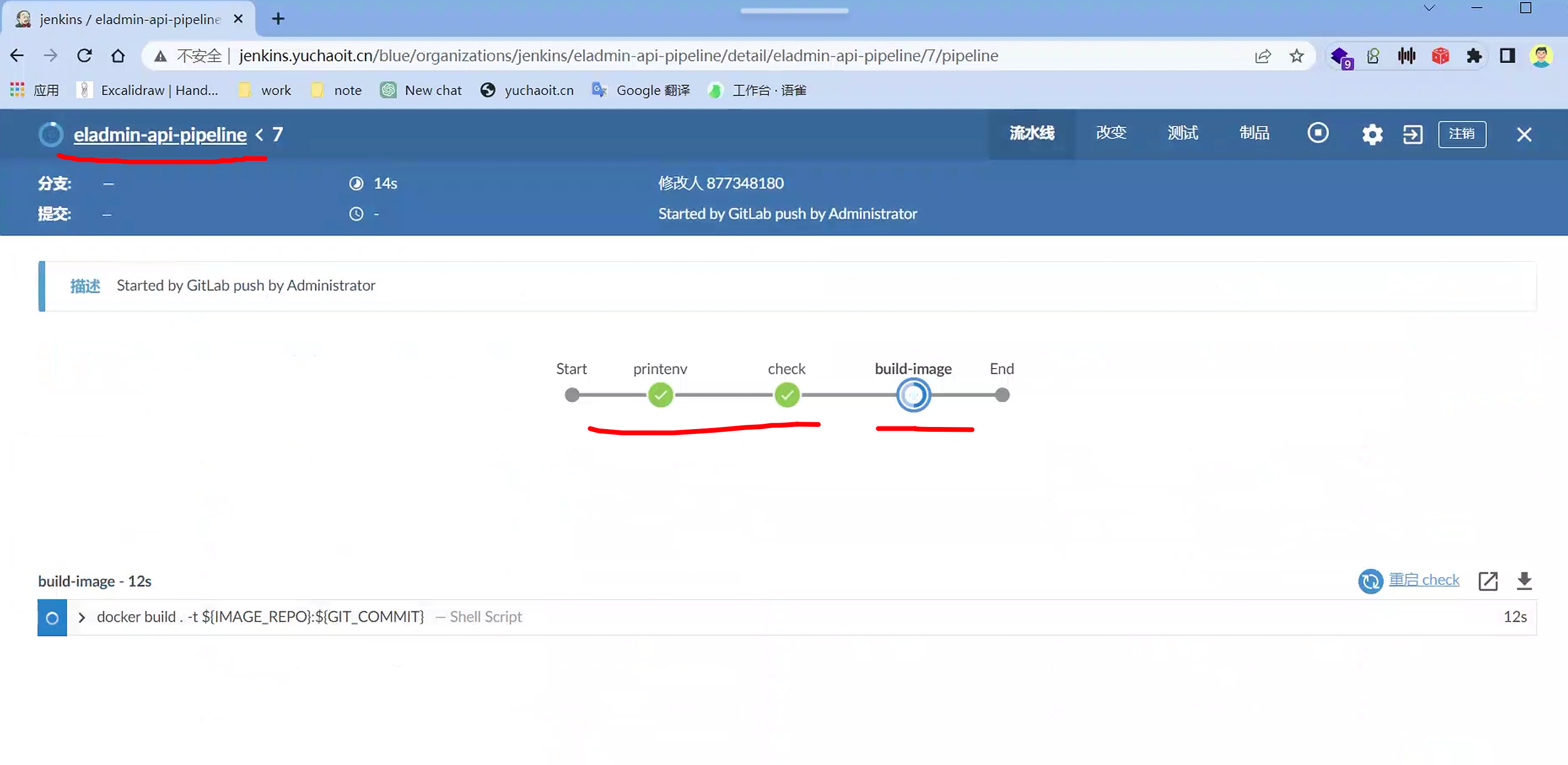
试试k8s构建
# git add
# git commit
# git push
踩坑记录
# docker客户端,是否被允许往registry里推送数据
[root@k8s-slave1 ~]#cat /etc/docker/daemon.json
{
"insecure-registries": ["10.0.0.66:5000"],
"registry-mirrors" : [
"https://ms9glx6x.mirror.aliyuncs.com"
]
}
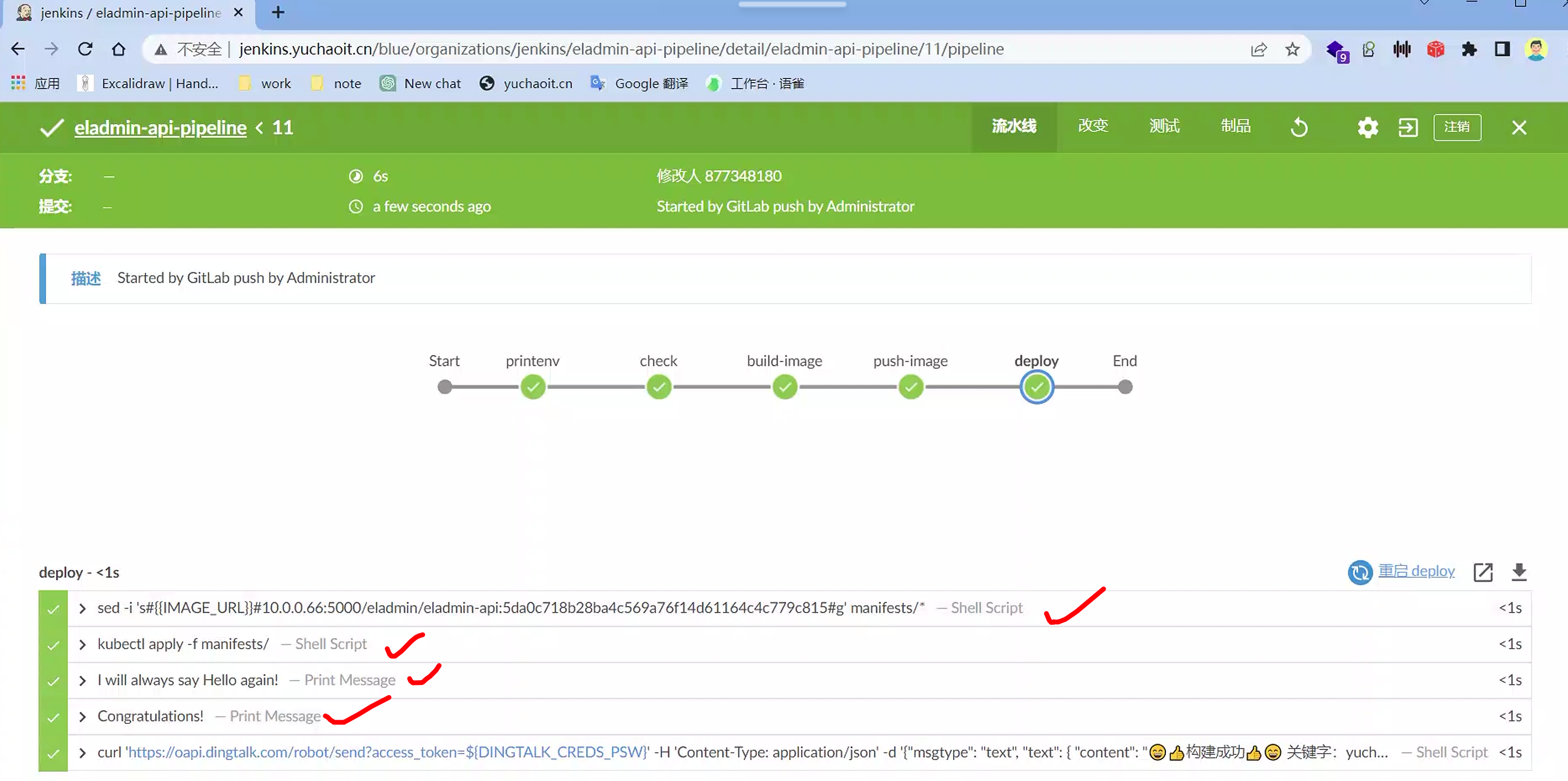
最终结果
进阶优化思考
上面我们已经通过Jenkinsfile完成了最简单的项目的构建和部署,那么我们来思考目前的方式:
- 目前都是在项目的单一分支下进行操作,企业内一般会使用feature、develop、release、master等多个分支来管理整个代码提交流程,如何根据不同的分支来做构建?
- 构建视图中如何区分不同的分支?
- 如何不配置webhook的方式实现构建?
- 如何根据不同的分支选择发布到不同的环境(开发、测试、生产)?