添加监控目标
无论是业务应用还是k8s系统组件,只要提供了metrics api,并且该api返回的数据格式满足标准的Prometheus数据格式要求即可。
其实,很多组件已经为了适配Prometheus采集指标,添加了对应的/metrics api,比如
prometheus
[root@k8s-master ~/prometheus-all]#kubectl -n monitor exec -it prometheus-6c8768547-v7hqq -- sh
Defaulted container "prometheus" out of: prometheus, change-permission-of-directory (init)
/prometheus $ netstat -tunlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 :::9090 :::* LISTEN 1/prometheus
/prometheus $
# 程序主动暴露一些metrics API、以及端口,是程序开发者定义好的,我们直接可以去访问
CoreDNS
k8s本身资源也一样,因为暴露metricsAPI,交给prometheus已经是成熟且固定的方案。
[root@k8s-master ~/prometheus-all]#kubectl -n kube-system get po -owide|grep dns
coredns-74586cf9b6-k5mwm 1/1 Running 10 (<invalid> ago) 49d 10.244.0.120 k8s-master <none> <none>
coredns-74586cf9b6-xl4bc 1/1 Running 10 (<invalid> ago) 49d 10.244.0.121 k8s-master <none> <none>
# 查看coredns的暴露端口
[root@k8s-master ~/prometheus-all]#kubectl -n kube-system get svc kube-dns -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 49d k8s-app=kube-dns
# 可以访问指标API
[root@k8s-master ~/prometheus-all]#curl 10.96.0.10:9153/metrics |tail
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 20923 0 20923 0 0 10.9M 0 --:--:-- --:--:-- --:--:-- 19.9M
process_resident_memory_bytes 3.2251904e+07
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.68266490069e+09
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 7.6910592e+08
# HELP process_virtual_memory_max_bytes Maximum amount of virtual memory available in bytes.
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes 1.8446744073709552e+19
接下来是一系列以# HELP和# TYPE开头的注释,这些注释描述了下面列出的指标的含义和类型。下面列出的是一些指标及其对应的值,
- 其中process_cpu_seconds_total表示进程消耗的CPU时间总量
- process_max_fds表示进程可以打开的最大文件描述符数量
- process_open_fds表示当前进程打开的文件描述符数量
- process_resident_memory_bytes表示进程占用的常驻内存大小
- process_start_time_seconds表示进程启动时间
- process_virtual_memory_bytes表示进程占用的虚拟内存大小
- 而process_virtual_memory_max_bytes则表示进程可用的最大虚拟内存大小。
添加给普罗米修斯去监控
添加coredns的指标API即可
27 scrape_configs:
28 # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
29 - job_name: 'prometheus'
30
31 # metrics_path defaults to '/metrics'
32 # scheme defaults to 'http'.
33
34 static_configs:
35 - targets: ['localhost:9090']
36 - job_name: 'coredns'
37 static_configs:
38 - targets: ['10.96.0.10:9153']
configmap会自动刷新到pod里,看看pod自动刷新(有轮训时间等待30s)
[root@k8s-master ~/prometheus-all]#kubectl -n monitor exec prometheus-6c8768547-v7hqq -- cat /etc/prometheus/prometheus.yml |tail
Defaulted container "prometheus" out of: prometheus, change-permission-of-directory (init)
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'coredns'
static_configs:
- targets: ['10.96.0.10:9153']
热更新reload
并且普罗米修斯支持热加载,直接访问热加载的接口,并且查看普罗米修斯的更新
[root@k8s-master ~/prometheus-all]#kubectl -n monitor get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prometheus-6c8768547-v7hqq 1/1 Running 0 68m 10.244.1.96 k8s-slave2 <none> <none>
[root@k8s-master ~/prometheus-all]#curl -X POST 10.244.1.96:9090/-/reload
查看target
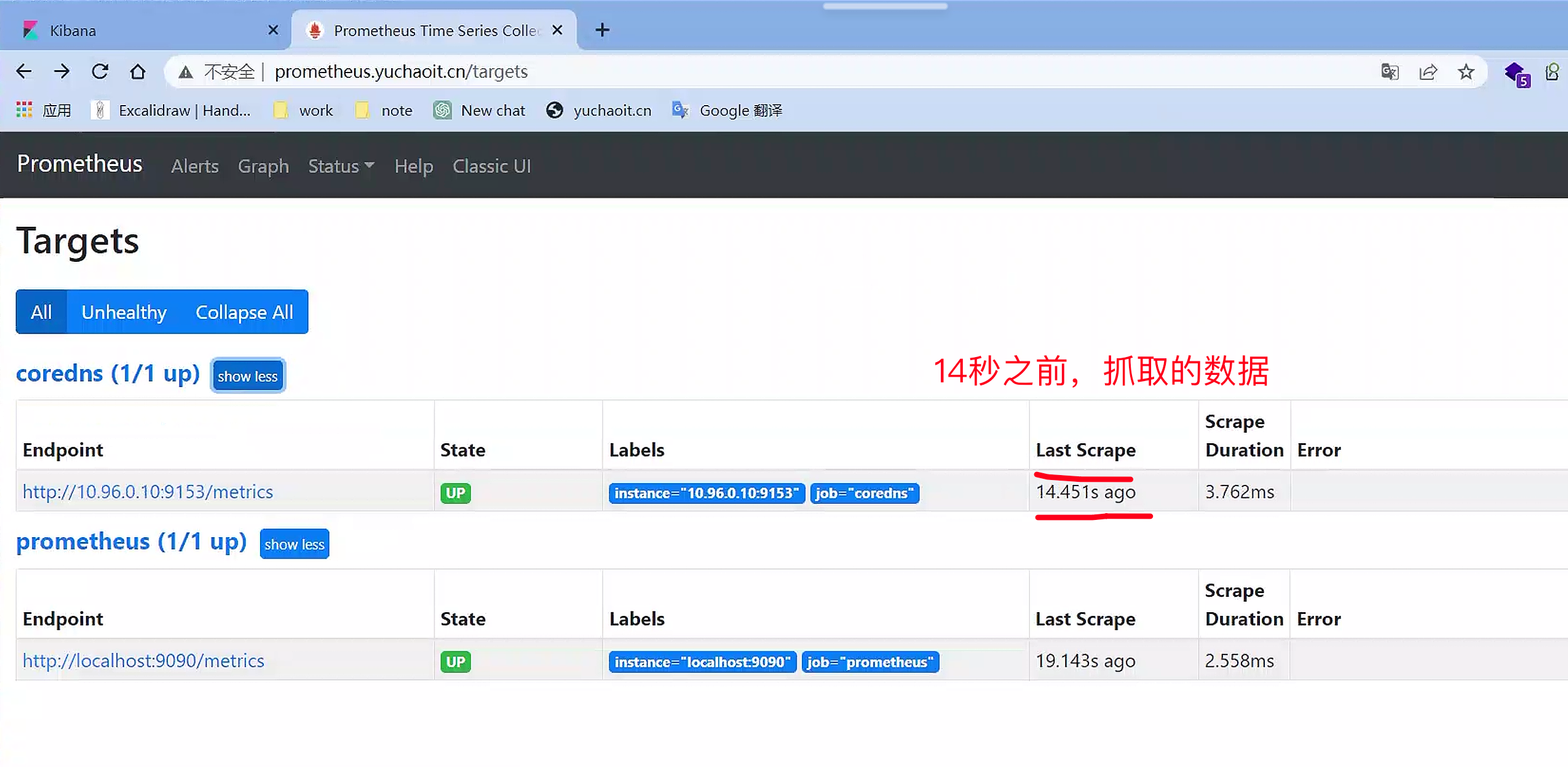
查看coredns样本
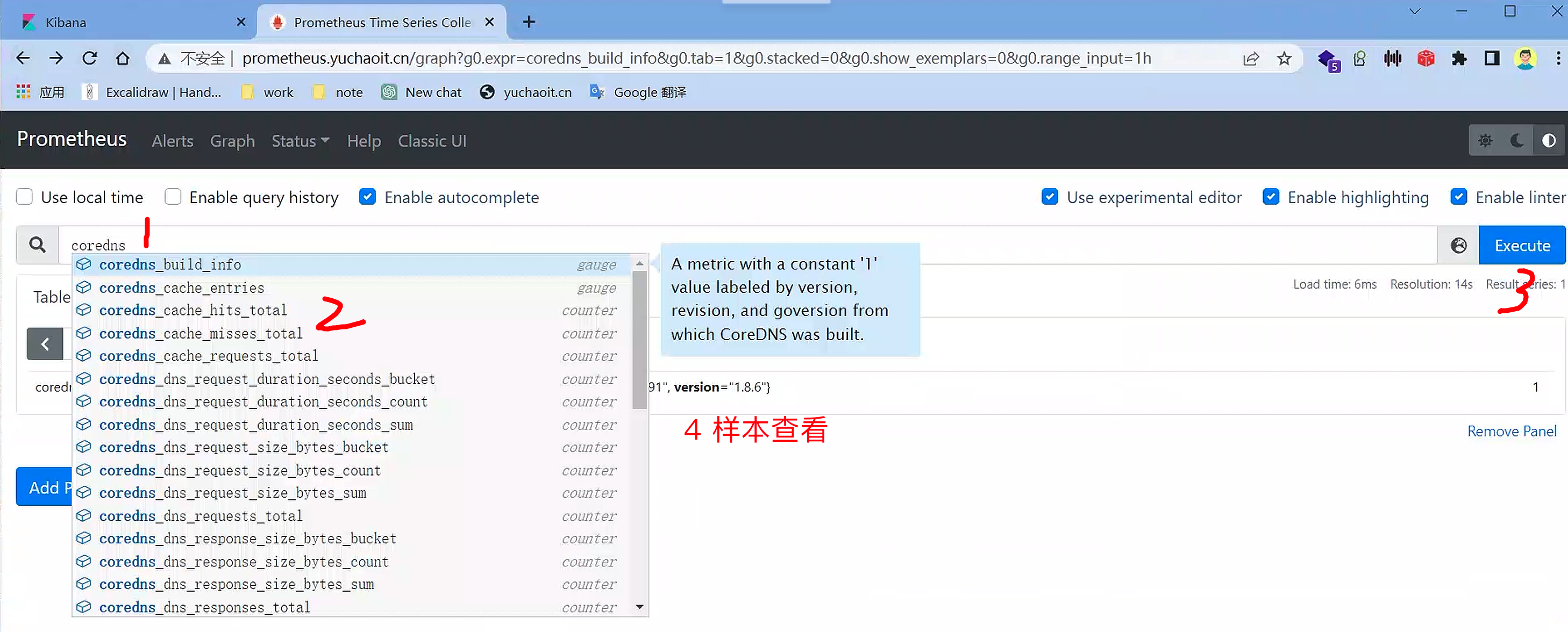
prometheus样本
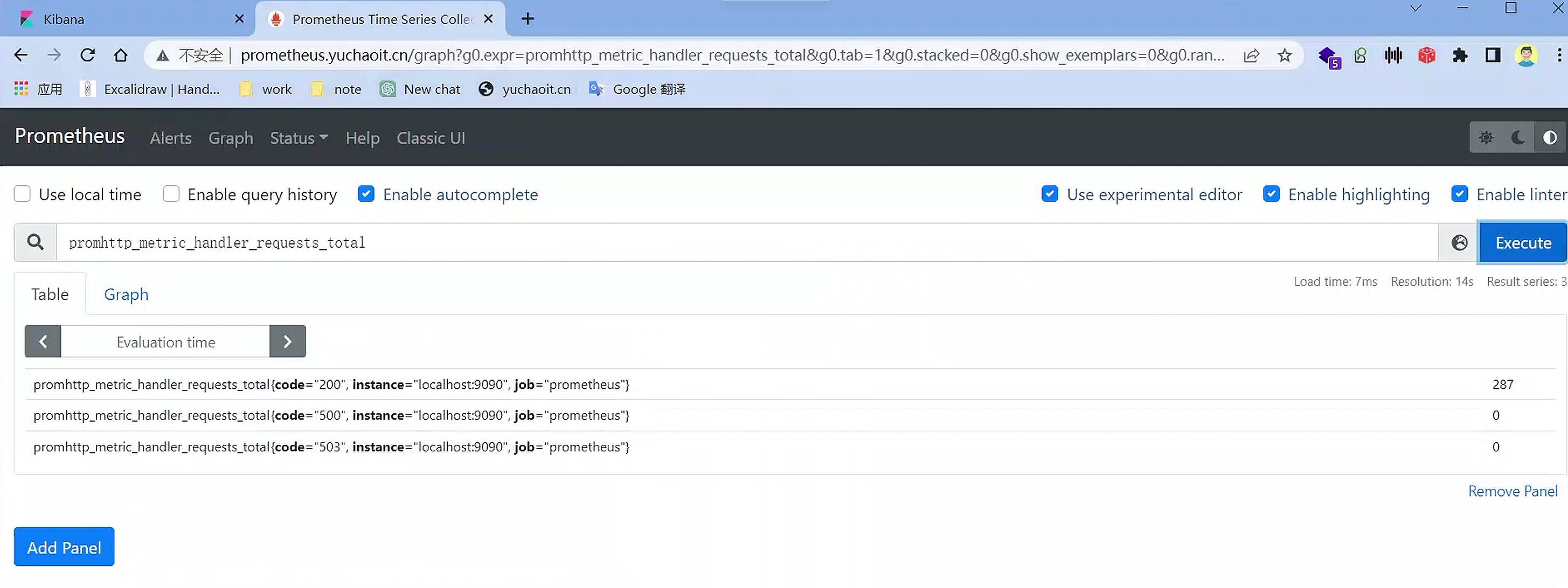
[root@k8s-master ~/prometheus-all]#curl 10.244.1.96:9090/metrics |grep handler_requests_total
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 65799 0 65799 0 0 12.4M 0 --:--:-- --:--:-- --:--:-- 15.6M
# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.
# TYPE promhttp_metric_handler_requests_total counter
promhttp_metric_handler_requests_total{code="200"} 293
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
常用监控对象(任务)
- 内部系统组件的状态: Kubernetes 集群中有多个内部系统组件,包括 kube-apiserver、kube-scheduler、kube-controller-manager、kubedns/coredns 等。这些组件的运行状态会直接影响整个集群的健康状况,因此监控其运行状态是非常重要的。可以监控它们的 CPU 和内存使用情况、运行日志、错误率等指标。
- Kubernetes 节点的监控: 节点的监控涵盖了节点的整体健康状况,包括 CPU、load、disk、memory 等指标。这些指标可以帮助管理员及时发现节点的异常状况,及时调整资源分配策略,以确保节点的高可用性和稳定性。
- 业务容器基础指标的监控: 业务容器是 Kubernetes 集群的核心组成部分,监控其基础指标如 CPU、内存、磁盘等是非常重要的。这些指标可以帮助管理员监测业务容器的资源使用情况,避免因为资源不足导致业务出现问题。另外,还需要监控 HPA(Horizontal Pod Autoscaler)、kubelet、adviser 等组件的状态,以确保它们的正常运行。
- 业务容器业务指标的监控: 业务容器不仅需要监控其基础指标,还需要监控业务指标。这些业务指标可能包括网络流量、请求响应时间、并发数等。可以通过暴露业务代码实现的 /metrics API 来获取这些指标。
- 编排级的 metrics: Kubernetes 集群中的编排级组件,如 Deployment、StatefulSet、DaemonSet 等,也需要进行监控。可以监控它们的状态、资源请求、调度和 API 延迟等数据指标,以确保它们的正常运行。
1.kube-apiserver
apiserver自身也提供了/metrics 的api来提供监控数据。
但是api-server是https的API,你得传入证书,进行认证、授权。
[root@k8s-master ~/prometheus-all]#kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 49d
[root@k8s-master ~/prometheus-all]#kubectl -n monitor create token prometheus
[root@k8s-master ~/prometheus-all]#curl -s -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6IllmUUhDWV9wUXEtcEZDRlhuQzlRZTMxQ0czdkhuUU9YRThNR1daVExvOVEifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjgyNjc0MjE4LCJpYXQiOjE2ODI2NzA2MTgsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJtb25pdG9yIiwic2VydmljZWFjY291bnQiOnsibmFtZSI6InByb21ldGhldXMiLCJ1aWQiOiIzYmI4OWZiNi1jN2Y0LTQ0YWYtOWE5ZS0wN2VkYzZlNDg4YzgifX0sIm5iZiI6MTY4MjY3MDYxOCwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Om1vbml0b3I6cHJvbWV0aGV1cyJ9.fsiUfrtidziDOBwAeYMUp1OOy3NfjNOckTekJmrh1WM8DREUEGk-xUta0H18w5n14n-vknFCHuLukZvZxpfcEr5z5s_8k-go2vhWggeJ_fJif_P-Z4ypAn3Bm9oCfwsPiXDxqTCDQ1uWaxas2QZ7a4q79DtW8mz641jfwRGefQOZs6UlEKwZ_vkoDfUbdfCtioIPve2jOKLQte2N9jqKJYUqoNhwV7YwG7-dRJKCOGuyOdUPsvU1h_tyVN8DTl63Yp21vKGaaBwg6gYfnnDNWQz7pzqAj4sG7Df8CPQtYb7tdToRQqXSdHvDBLelHW0fDjJ871_8xXtOKiEGlHc2Ow
" https://10.96.0.1:6443/metrics|tail
workqueue_work_duration_seconds_bucket{name="priority_and_fairness_config_queue",le="9.999999999999999e-06"} 0
workqueue_work_duration_seconds_bucket{name="priority_and_fairness_config_queue",le="9.999999999999999e-05"} 0
workqueue_work_duration_seconds_bucket{name="priority_and_fairness_config_queue",le="0.001"} 1
workqueue_work_duration_seconds_bucket{name="priority_and_fairness_config_queue",le="0.01"} 1
workqueue_work_duration_seconds_bucket{name="priority_and_fairness_config_queue",le="0.1"} 1
workqueue_work_duration_seconds_bucket{name="priority_and_fairness_config_queue",le="1"} 1
workqueue_work_duration_seconds_bucket{name="priority_and_fairness_config_queue",le="10"} 1
workqueue_work_duration_seconds_bucket{name="priority_and_fairness_config_queue",le="+Inf"} 1
workqueue_work_duration_seconds_sum{name="priority_and_fairness_config_queue"} 0.000274167
workqueue_work_duration_seconds_count{name="priority_and_fairness_config_queue"} 1
[root@k8s-master ~/prometheus-all]#
加入target
[root@k8s-master ~/prometheus-all]#kubectl -n monitor edit configmaps prometheus-config
# 有额外的操作,需要加入证书认证
27 scrape_configs:
28 # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
29 - job_name: 'prometheus'
30
31 # metrics_path defaults to '/metrics'
32 # scheme defaults to 'http'.
33
34 static_configs:
35 - targets: ['localhost:9090']
36 - job_name: 'coredns'
37 static_configs:
38 - targets: ['10.96.0.10:9153']
39
40 - job_name: 'kubernetes-apiserver'
41 static_configs:
42 - targets: ['10.96.0.1']
43 scheme: https
44 tls_config:
45 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
46 insecure_skip_verify: true
47 bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
48
刷新查看prometheus
[root@k8s-master ~/prometheus-all]#kubectl -n monitor edit configmaps prometheus-config
configmap/prometheus-config edited
[root@k8s-master ~/prometheus-all]#curl -X POST 10.244.1.96:9090/-/reload
[root@k8s-master ~/prometheus-all]#
搞定了,成功加入apiserver到监控
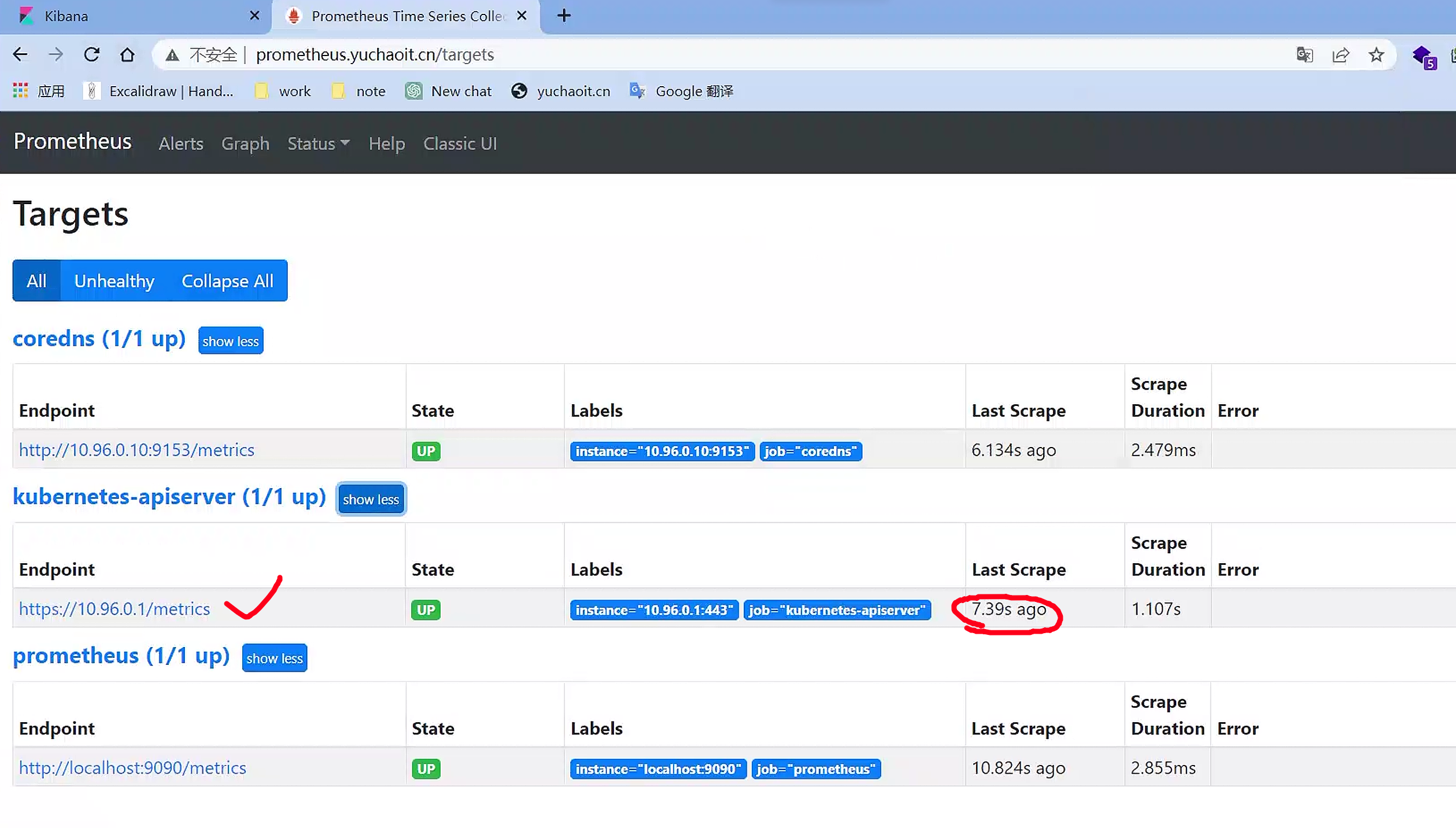
图形化样本

2.node集群节点
node_exporter https://github.com/prometheus/node_exporter
分析:
- 每个节点都需要监控,因此可以使用DaemonSet类型来管理node_exporter
- 添加节点的容忍配置
- 挂载宿主机中的系统文件信息
Prometheus使用Node Exporter来监控节点。Node Exporter是一个官方的Prometheus exporter,它可以从操作系统中提取各种指标,例如CPU使用率、内存使用率、磁盘使用率等等。Node Exporter本质上是一个二进制文件,需要在每个节点上安装并运行。
安装和配置Node Exporter非常简单,只需要按照官方文档中的说明进行即可。通常情况下,你需要下载并解压缩Node Exporter二进制文件,然后运行该二进制文件即可。默认情况下,Node Exporter会监听在本地的9100端口,并在该端口上暴露节点的各种指标。
一旦Node Exporter运行起来了,Prometheus就可以通过HTTP协议获取到节点的各种指标,并将这些指标存储到自己的时间序列数据库中。然后,你就可以使用Prometheus提供的查询语言PromQL对这些指标进行查询和分析了。
Node-exporter.ds.yml
这是一个Kubernetes的YAML配置文件,用于创建一个名为"node-exporter"的DaemonSet,以在每个节点上部署并运行Node Exporter。
在该文件中,DaemonSet定义了如何创建Pod,并保证每个节点上都会有一个运行着Node Exporter的Pod。其中,spec.template描述了Pod的定义,包括使用的容器、挂载的卷以及调度和安全等方面的设置。
在容器定义中,使用了Prometheus官方提供的node-exporter镜像,并指定了需要暴露的端口号和一些参数,例如路径和忽略的文件系统类型等等。容器使用了hostNetwork模式,以便在Pod中直接访问节点上的网络。此外,容器也挂载了节点上的一些目录,例如/proc、/sys和/root等等,以便从节点中获取指标。
最后,该文件还定义了一些资源请求和限制,以及容器的安全上下文和容器中的环境变量等。在Pod的spec.template中,还定义了一些调度和容错方面的设置,例如指定了只在Linux操作系统的节点上运行,以及设置了容忍性。
$ cat node-exporter.ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
image: prom/node-exporter:v1.0.1 #v1.4.0
args:
- --web.listen-address=$(HOSTIP):9100
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/docker/.+)($|/)
- --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$
ports:
- containerPort: 9100
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
resources:
requests:
cpu: 150m
memory: 180Mi
limits:
cpu: 150m
memory: 180Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true
tolerations:
- operator: "Exists"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
创建查看
[root@k8s-master ~/prometheus-all]#kubectl apply -f node_exporter.yml
daemonset.apps/node-exporter created
# node_export以hostnetwork启动
[root@k8s-master ~/prometheus-all]#kubectl -n monitor get po -owide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-68n2w 1/1 Running 0 12m 10.0.0.80 k8s-master <none> <none>
node-exporter-6z9sj 1/1 Running 0 12m 10.0.0.82 k8s-slave2 <none> <none>
node-exporter-rkrgh 1/1 Running 0 1s 10.0.0.81 k8s-slave1 <none> <none>
prometheus-6c8768547-v7hqq 1/1 Running 0 168m 10.244.1.96 k8s-slave2 <none> <none>
# 访问指标接口 9100端口,默认约定的端口
[root@k8s-master ~]#curl 10.0.0.82:9100/metrics |tail
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 118k 0 118k 0 0 6421k 0 --:--:-- --:--:-- --:--:-- 6572k
promhttp_metric_handler_errors_total{cause="encoding"} 0
promhttp_metric_handler_errors_total{cause="gathering"} 0
# HELP promhttp_metric_handler_requests_in_flight Current number of scrapes being served.
# TYPE promhttp_metric_handler_requests_in_flight gauge
promhttp_metric_handler_requests_in_flight 1
# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.
# TYPE promhttp_metric_handler_requests_total counter
promhttp_metric_handler_requests_total{code="200"} 1
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
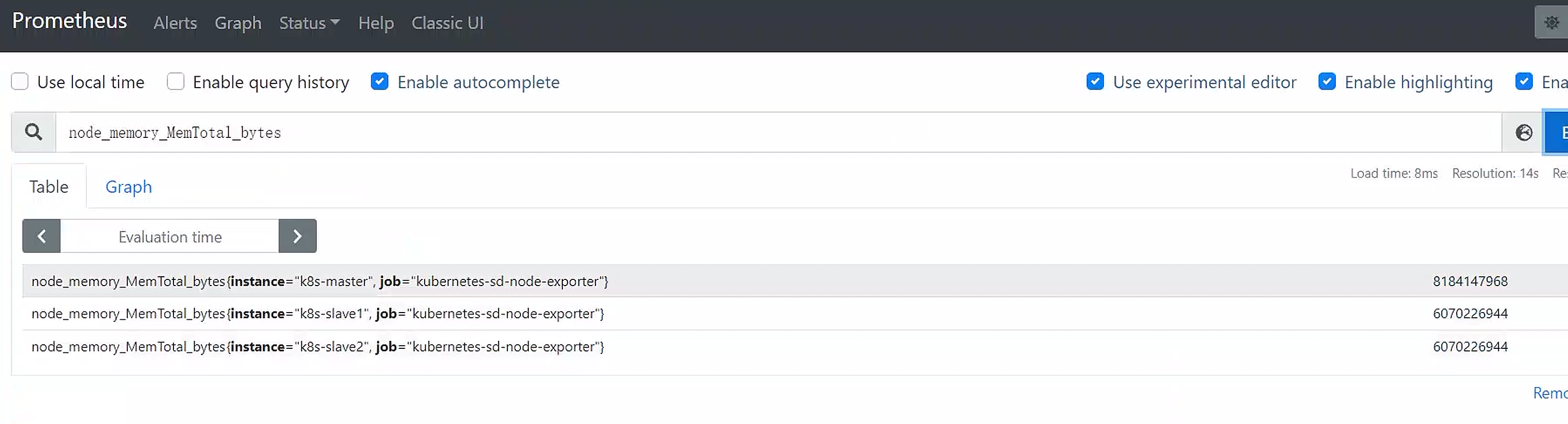
查看3个机器的内存指标
[root@k8s-master ~]#curl -s 10.0.0.82:9100/metrics |grep node_memory_MemTotal_bytes
# HELP node_memory_MemTotal_bytes Memory information field MemTotal_bytes.
# TYPE node_memory_MemTotal_bytes gauge
node_memory_MemTotal_bytes 6.070226944e+09
[root@k8s-master ~]#curl -s 10.0.0.80:9100/metrics |grep node_memory_MemTotal_bytes
# HELP node_memory_MemTotal_bytes Memory information field MemTotal_bytes.
# TYPE node_memory_MemTotal_bytes gauge
node_memory_MemTotal_bytes 8.184147968e+09
至此就可以拿到k8s节点宿主机的监控指标。
问题:如何添加到target
问题来了,如何添加到Prometheus的target中?
- 配置一个Service,后端挂载node-exporter的服务,把Service的地址配置到target中
- 带来新的问题,target中无法直观的看到各节点node-exporter的状态
- 把每个node-exporter的服务都添加到target列表中
- 带来新的问题,集群节点的增删,都需要手动维护列表
- target列表维护量随着集群规模增加
- 而且你有多少个node节点,都手工维护target的配置文件吗?
学习ServiceDiscovery

ServiceDiscovery和static_config都是Prometheus中用于配置target列表的机制,但它们之间有一些区别。
静态配置(static_config)是手动定义的target列表,您需要手动添加或删除每个目标。这意味着当集群中的节点增加或删除时,您需要手动更新静态配置文件以添加或删除节点。这对于较小的集群可能是可行的,但对于规模较大的集群而言,手动维护静态配置文件可能会变得非常困难。
相比之下,ServiceDiscovery是一种动态发现目标的机制,它允许Prometheus自动发现并监视与其连接的所有目标。ServiceDiscovery的工作方式是通过查询指定的服务注册表或API,来获取要监视的目标列表。当服务注册表或API发生更改时,Prometheus将自动检测到更改并更新其目标列表。这使得ServiceDiscovery非常适合用于动态环境,例如Kubernetes集群。
因此,ServiceDiscovery和静态配置之间的主要区别在于它们如何管理目标列表。静态配置需要手动添加和删除目标,而ServiceDiscovery会自动发现目标并自动更新列表。在许多情况下,使用ServiceDiscovery会更加方便和可扩展,特别是在动态环境中,而静态配置适用于静态环境或小型集群。
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'coredns'
static_configs:
- targets: ['10.96.0.10:9153']
- job_name: 'kubernetes-apiserver'
static_configs:
- targets: ['10.96.0.1']
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
[root@k8s-master ~/prometheus-all]#kubectl -n monitor exec prometheus-6c8768547-v7hqq -- cat /etc/prometheus/prometheus.yml
服务发现与Relabeling
Prometheus 是一种开源的监控系统,它提供了丰富的数据采集和查询功能。在 Prometheus 中,服务发现和 relabeling 是两个关键的概念,它们可以帮助用户自动地发现和管理监控目标。
服务发现是 Prometheus 中一个非常重要的功能,它允许用户在不需要手动配置的情况下自动发现新的监控目标。通过服务发现,Prometheus 可以自动地发现新的实例并将其添加到监控目标列表中。Prometheus 支持多种服务发现方式,例如 DNS 服务发现、Kubernetes 服务发现、Consul 服务发现等。通过这些服务发现方式,用户可以快速地发现新的实例,而无需手动添加和配置监控目标。
Relabeling 是 Prometheus 中另一个非常重要的概念,它允许用户对采集到的指标数据进行重命名、重组和过滤等操作。通过 relabeling,用户可以将采集到的指标数据进行规范化和整理,从而使其更易于管理和查询。例如,用户可以通过 relabeling 将采集到的指标数据进行重命名、重组和过滤等操作,从而使其更加清晰和易于理解。
在 Prometheus 中,服务发现和 relabeling 是紧密相关的。通过服务发现,Prometheus 可以自动地发现新的实例,并将其添加到监控目标列表中。而通过 relabeling,用户可以对采集到的指标数据进行规范化和整理,从而使其更易于管理和查询。因此,服务发现和 relabeling 是 Prometheus 中非常重要的两个概念,它们可以帮助用户自动地管理和查询监控目标。
ServiceDiscovery
Prometheus内置了对Kubernetes API的支持,可以通过与Kubernetes API的集成来发现和监视Kubernetes环境中的节点、服务、Pod、Endpoints和Ingress等资源。
为了实现与Kubernetes API的集成,您需要在Prometheus配置文件中指定一个ServiceDiscovery机制。在Kubernetes环境中,您可以使用Kubernetes SD机制来实现这一点。Kubernetes SD机制使用Kubernetes API来自动发现节点、服务、Pod、Endpoints和Ingress等资源,并将它们添加到Prometheus的target列表中。这使得Prometheus可以自动监视Kubernetes环境中的所有资源。
值得注意的是,为了使用Kubernetes SD机制,您需要为Prometheus配置一个ServiceAccount,并授予该ServiceAccount访问Kubernetes API的权限。您可以通过为ServiceAccount分配适当的ClusterRole和ClusterRoleBinding来实现这一点。一旦Prometheus具有访问Kubernetes API的权限,它就可以自动发现和监视Kubernetes环境中的所有资源,而无需手动配置target列表。
prometheus支持哪几种服务发现
之前已经给Prometheus配置了RBAC,有读取node的权限,因此Prometheus可以去调用Kubernetes API获取node信息。
所以Prometheus通过与 Kubernetes API 集成,提供了内置的服务发现分别是:Node、Service、Pod、Endpoints、Ingress
通过与 Kubernetes API 集成,Prometheus可以自动识别并监控 Kubernetes 中的不同服务发现方式。
具体来说,Prometheus支持以下几种服务发现方式:
- Node:监控Kubernetes集群中的节点(Node),并采集其指标数据。
- Service:监控Kubernetes集群中的Service服务,自动发现其关联的Pod,并采集其指标数据。
- Pod:监控Kubernetes集群中的Pod,直接采集其指标数据。
- Endpoints:监控Kubernetes集群中的Endpoints(即Pod的网络终点),并采集其指标数据。
- Ingress:监控Kubernetes集群中的Ingress资源(即负载均衡器),自动发现其关联的Service和Endpoints,并采集其指标数据。
通过这些服务发现方式,Prometheus可以帮助用户更方便地监控和管理Kubernetes集群中的不同组件。
修改prometheus.yml
[root@k8s-master ~/prometheus-all]#kubectl -n monitor edit configmaps prometheus-config
39
40 - job_name: 'kubernetes-apiserver'
41 static_configs:
42 - targets: ['10.96.0.1']
43 scheme: https
44 tls_config:
45 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
46 insecure_skip_verify: true
47 bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
48 - job_name: 'kubernetes-sd-node-exporter'
49 kubernetes_sd_configs:
50 - role: node
更新普罗米修斯配置
[root@k8s-master ~/prometheus-all]#!952
curl -X POST 10.244.1.96:9090/-/reload
[root@k8s-master ~/prometheus-all]#kubectl -n monitor exec prometheus-6c8768547-v7hqq -- cat /etc/prometheus/prometheus.yml|tail
Defaulted container "prometheus" out of: prometheus, change-permission-of-directory (init)
static_configs:
- targets: ['10.96.0.1']
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: 'kubernetes-sd-node-exporter'
kubernetes_sd_configs:
- role: node
查看targets
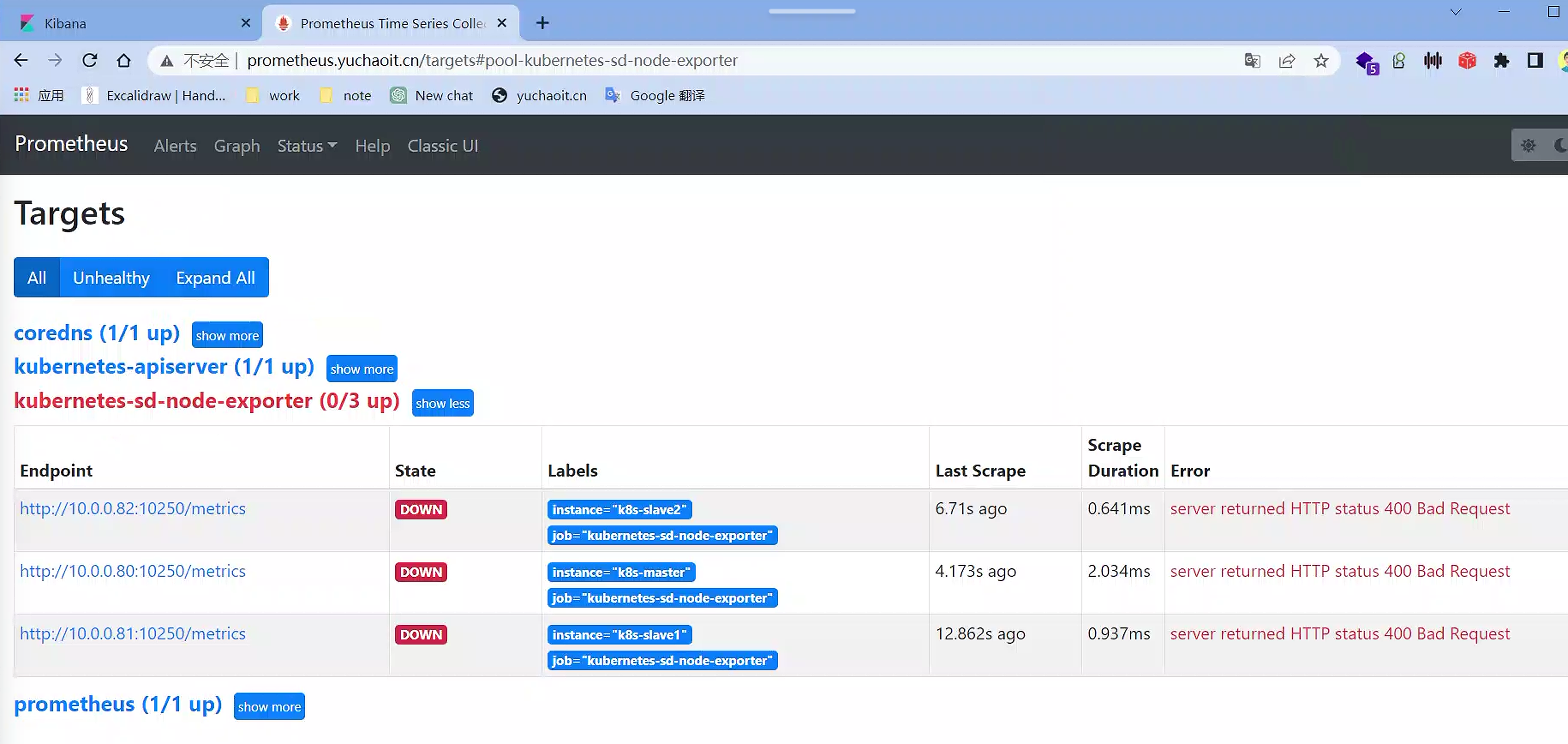
默认访问的地址是http://node-ip/10250/metrics,10250是kubelet API的服务端口,说明Prometheus的node类型的服务发现模式,默认是和kubelet的10250绑定的。
[root@k8s-master ~/prometheus-all]#netstat -tunlp|grep kubelet
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 1709/kubelet
tcp6 0 0 :::10250 :::* LISTEN 1709/kubelet
修改node_exporter配置

而我们是期望使用node-exporter作为采集的指标来源,因此需要把访问的endpoint替换成http://node-ip:9100/metrics。
在真正抓取数据前,Prometheus提供了relabeling的能力。怎么理解?
relabel_configs功能
relabeling使用relabel_configs部分定义,其中每个relabel_config定义包含一组规则,可以选择性地从目标中选择和修改标签。以下是一些常见的relabeling规则:
- source_labels:定义要选择的标签列表。如果定义了多个标签,则使用以“|”分隔的标签列表。
- target_label:定义要写入的新标签名称。
- regex:一个正则表达式,用于匹配要更改的标签的值。
- replacement:一个字符串,用于替换匹配的标签值。
- action:定义如何处理标签匹配。例如,可以删除匹配的标签或添加新的标签。
因此,利用relabeling的能力,只需要将__address__替换成node_exporter的服务地址即可。
- job_name: 'kubernetes-sd-node-exporter'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
更新普罗米修斯
[root@k8s-master ~/prometheus-all]#kubectl -n monitor edit configmaps prometheus-config
configmap/prometheus-config edited
[root@k8s-master ~/prometheus-all]#
[root@k8s-master ~/prometheus-all]#curl -X POST 10.244.1.96:9090/-/reload
[root@k8s-master ~/prometheus-all]#
relabeling功能非常强大,可以实现复杂的标签转换和重写,以适应各种不同的部署和监控需求。
查看labels更新
替换label之前
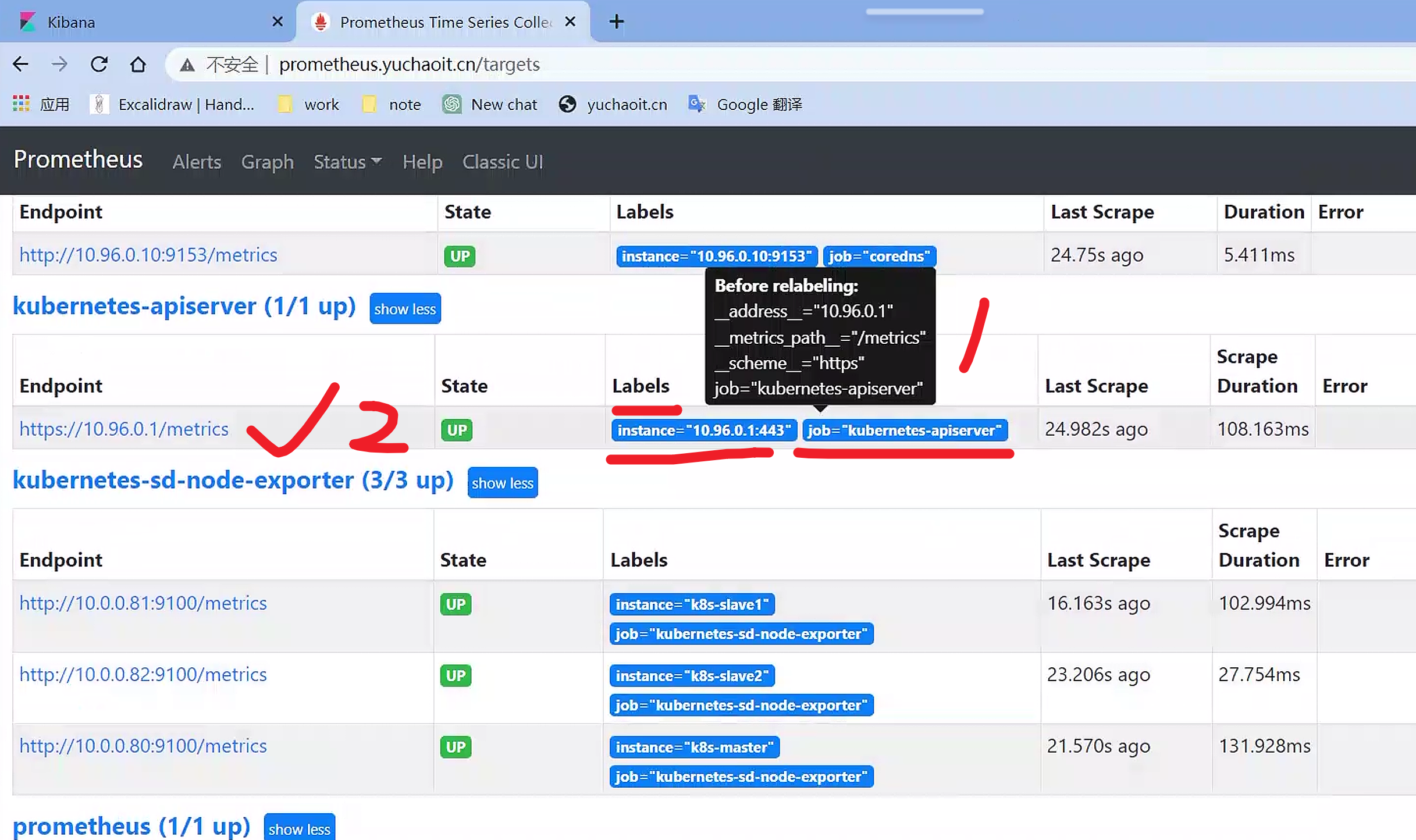
替换
__address__
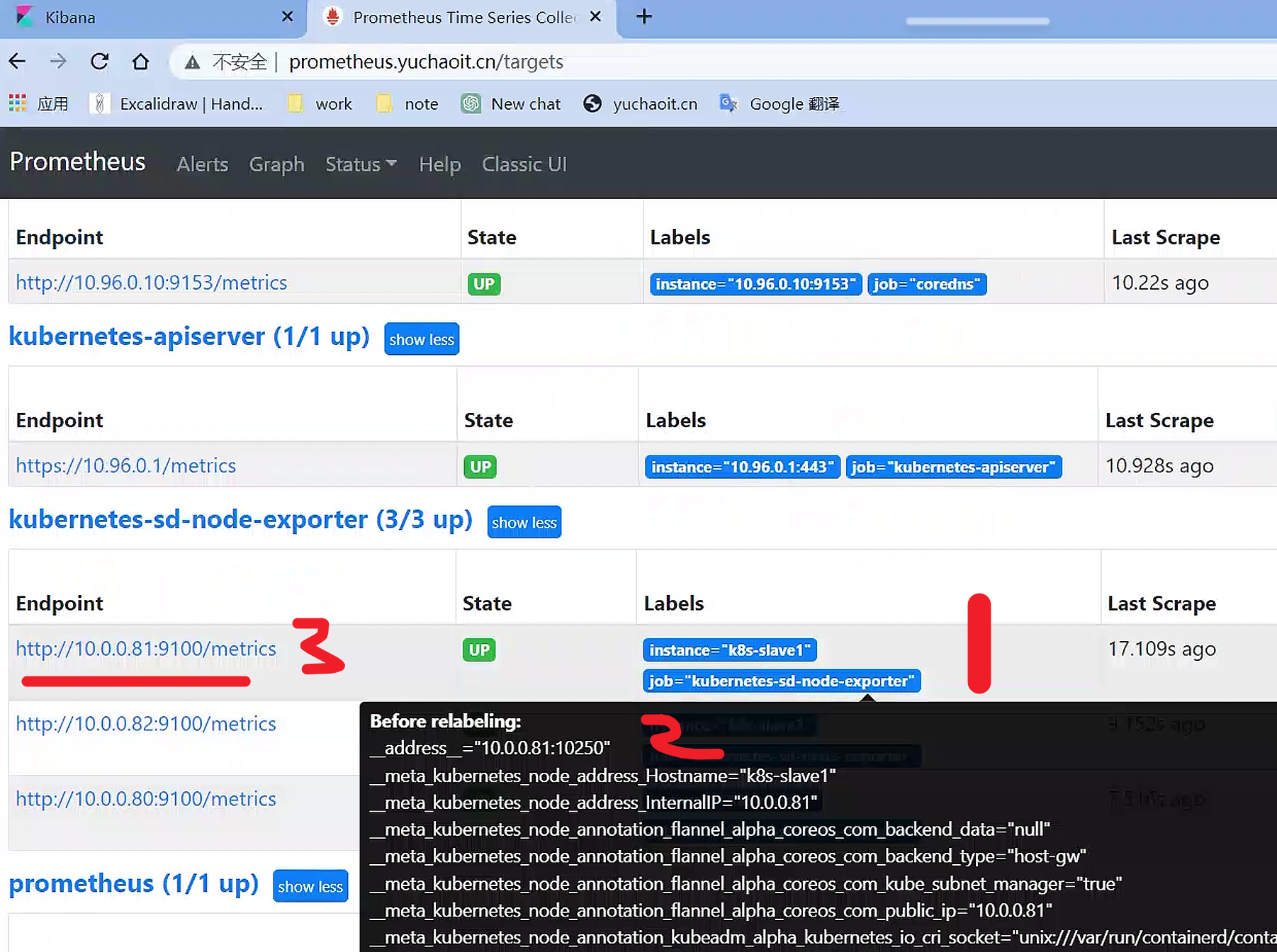
成功拿到node指标
[root@k8s-master ~/prometheus-all]#netstat -tunlp|grep 9100
tcp 0 0 10.0.0.80:9100 0.0.0.0:* LISTEN 121210/node_exporte
# 通过9100拿到节点内存信息
[root@k8s-master ~/prometheus-all]#curl -s 10.0.0.80:9100/metrics |grep node_memory_MemTotal_bytes
# HELP node_memory_MemTotal_bytes Memory information field MemTotal_bytes.
# TYPE node_memory_MemTotal_bytes gauge
node_memory_MemTotal_bytes 8.184147968e+09

可以基于promeQL看到node信息
3.容器指标采集(cAdvisor)
cAdvisor(Container Advisor)是一个由Google开源的容器监控代理程序,用于收集和分析容器的资源使用情况。它可以监控容器的CPU、内存、磁盘和网络等资源使用情况,并提供有关容器的性能指标、事件和警报等信息。
cAdvisor旨在为容器监控和管理提供基础设施,它可以与各种容器编排系统和容器运行时集成,例如Docker、Kubernetes、Mesos和CoreOS等。
cAdvisor可以通过REST API提供容器资源使用情况的指标数据,还可以将数据存储在多种后端存储系统中,例如InfluxDB、Elasticsearch、Prometheus和Google Cloud Monitoring等。
在Kubernetes中,cAdvisor是默认的容器监控代理程序,它被集成到kubelet组件中,并用于收集容器的资源使用情况。
这使得Kubernetes可以通过cAdvisor获取有关容器的指标数据,例如CPU使用率、内存使用率和网络流量等。
此外,Kubernetes还提供了一个Kubernetes API,即Metrics API,可以用于获取有关节点、Pod和容器的指标数据。
Metrics API是一个独立于kubelet和cAdvisor的组件,可以通过HTTP请求获取指标数据。要使用Metrics API,您需要启用Kubernetes中的Heapster或Metric Server组件。
https://<node-ip>:10250/metrics/cadvisor # node上的cadvisor采集到的容器指标
https://<node-ip>:10250/metrics # node上的kubelet的指标数据
# 可以通过curl -k -H "Authorization: Bearer xxxx" https://xxxx/xx查看
因此,针对容器指标来讲,我们期望的采集target是:
https://10.0.0.80:10250/metrics/cadvisor
https://10.0.0.81:10250/metrics/cadvisor
https://10.0.0.82:10250/metrics/cadvisor
测试
# 容器指标
curl -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6IllmUUhDWV9wUXEtcEZDRlhuQzlRZTMxQ0czdkhuUU9YRThNR1daVExvOVEifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjgzMTI0NDU5LCJpYXQiOjE2ODMxMjA4NTksImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJtb25pdG9yIiwic2VydmljZWFjY291bnQiOnsibmFtZSI6InByb21ldGhldXMiLCJ1aWQiOiIzYmI4OWZiNi1jN2Y0LTQ0YWYtOWE5ZS0wN2VkYzZlNDg4YzgifX0sIm5iZiI6MTY4MzEyMDg1OSwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Om1vbml0b3I6cHJvbWV0aGV1cyJ9.hukhthfuuJqQXPiGI0UNx7tIO0nZM-lZE1J_hQxxJXysEgbykigGd6BKTKLxLIYIynLXqhXRSyJi4gmx-sWmDA4br_WtALRPjRmj70yVj_PuCFlhcSazfy4ToKpJO6Gq7A6bwwHMxrKon2AKz5HQez_dVjtV43Cc26tL264Wk3yhRcNNkrAXwp3ji2Qv0zjQhhCIClloTF_klckHacFyoAnQvERP9J7rgxZNVGTukAiDWOsEfWkmlU-txrwFw6uFOe0qPS-2ParMwjgfl3Dk8TLQM3-vYuGfq_0H1CQsrU4b856EcPJfpB75j8nOAyzKwoATUgPwknreQv3bBPL_3g" https://10.0.0.80:10250/metrics/cadvisor
# kubelet指标
curl -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6IllmUUhDWV9wUXEtcEZDRlhuQzlRZTMxQ0czdkhuUU9YRThNR1daVExvOVEifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjgzMTI0NDU5LCJpYXQiOjE2ODMxMjA4NTksImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJtb25pdG9yIiwic2VydmljZWFjY291bnQiOnsibmFtZSI6InByb21ldGhldXMiLCJ1aWQiOiIzYmI4OWZiNi1jN2Y0LTQ0YWYtOWE5ZS0wN2VkYzZlNDg4YzgifX0sIm5iZiI6MTY4MzEyMDg1OSwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Om1vbml0b3I6cHJvbWV0aGV1cyJ9.hukhthfuuJqQXPiGI0UNx7tIO0nZM-lZE1J_hQxxJXysEgbykigGd6BKTKLxLIYIynLXqhXRSyJi4gmx-sWmDA4br_WtALRPjRmj70yVj_PuCFlhcSazfy4ToKpJO6Gq7A6bwwHMxrKon2AKz5HQez_dVjtV43Cc26tL264Wk3yhRcNNkrAXwp3ji2Qv0zjQhhCIClloTF_klckHacFyoAnQvERP9J7rgxZNVGTukAiDWOsEfWkmlU-txrwFw6uFOe0qPS-2ParMwjgfl3Dk8TLQM3-vYuGfq_0H1CQsrU4b856EcPJfpB75j8nOAyzKwoATUgPwknreQv3bBPL_3g" https://10.0.0.80:10250/metrics
修改普罗米修斯target
既然每个node节点都需要去采集数据,联想到prometheus的服务发现中的node类型,因此,配置服务发现
- job_name: 'kubernetes-sd-cadvisor'
kubernetes_sd_configs:
- role: node

但是,默认添加的target列表为:__schema__://__address__ __metrics_path__
我们期望采集的是如下API
- kubelet-10250都得走https协议
- 并且采集的路径有区别
https://10.0.0.80:10250/metrics/cadvisor
https://10.0.0.81:10250/metrics/cadvisor
https://10.0.0.82:10250/metrics/cadvisor
和期望值不同的是__schema__和__metrics_path__,针对__metrics_path__可以使用relabel修改:
relabel_configs:
- target_label: __metrics_path__
replacement: /metrics/cadvisor
完整配置
48 - job_name: 'kubernetes-sd-node-exporter'
49 kubernetes_sd_configs:
50 - role: node
51 relabel_configs:
52 - source_labels: [__address__]
53 regex: '(.*):10250'
54 replacement: '${1}:9100'
55 target_label: __address__
56 action: replace
57 - job_name: 'kubernetes-sd-cadvisor'
58 kubernetes_sd_configs:
59 - role: node
60 scheme: https # 这里直接修改https
61 tls_config: # 配置RBAC
62 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
63 insecure_skip_verify: true
64 bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
65 relabel_configs: # 这里修改要采集的metrics_path
66 - target_label: __metrics_path__
67 replacement: /metrics/cadvisor
68 kind: ConfigMap
reload普罗米修斯
重启前,你是拿不到容器指标的
重载程序
curl -X POST 10.244.1.96:9090/-/reload
# 查看普罗米修斯配置是否更新
[root@k8s-master ~/prometheus-all]#kubectl -n monitor exec prometheus-6c8768547-v7hqq -- cat /etc/prometheus/prometheus.yml |tail -15
Defaulted container "prometheus" out of: prometheus, change-permission-of-directory (init)
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- job_name: 'kubernetes-sd-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https # 这里直接修改https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs: # 这里修改要采集的metrics_path
- target_label: __metrics_path__
replacement: /metrics/cadvisor
成功拿到容器指标
查看target
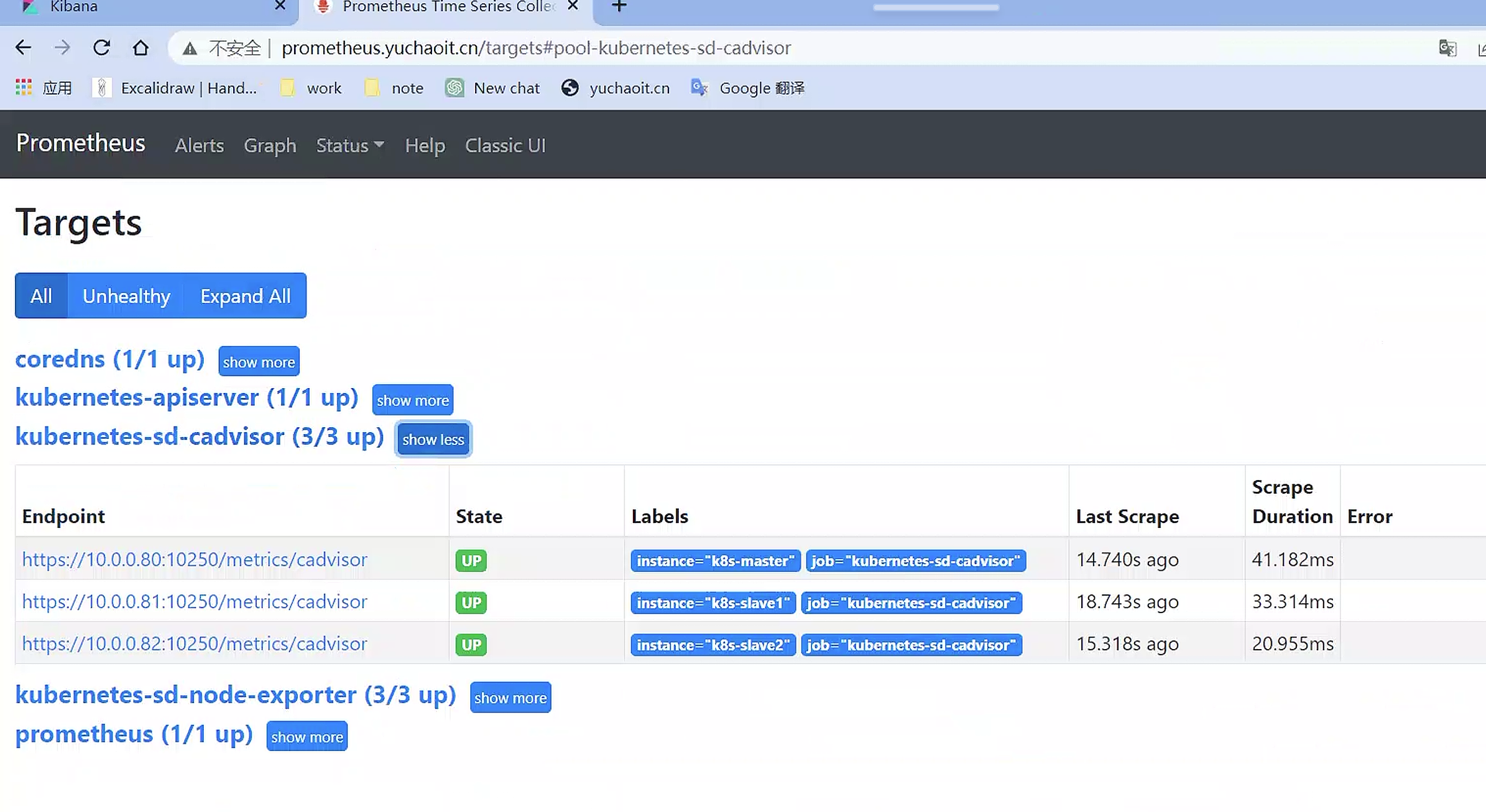
4.添加kubelet指标
[root@k8s-master ~/prometheus-all]#kubectl -n monitor exec prometheus-6c8768547-v7hqq -- cat /etc/prometheus/prometheus.yml |tail -20
Defaulted container "prometheus" out of: prometheus, change-permission-of-directory (init)
action: replace
- job_name: 'kubernetes-sd-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https # 这里直接修改https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs: # 这里修改要采集的metrics_path
- target_label: __metrics_path__
replacement: /metrics/cadvisor
- job_name: 'kubernetes-sd-kubelet'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
重载配置
kubectl -n monitor edit configmaps prometheus-config
curl -X POST 10.244.1.96:9090/-/reload
查看kubelet指标
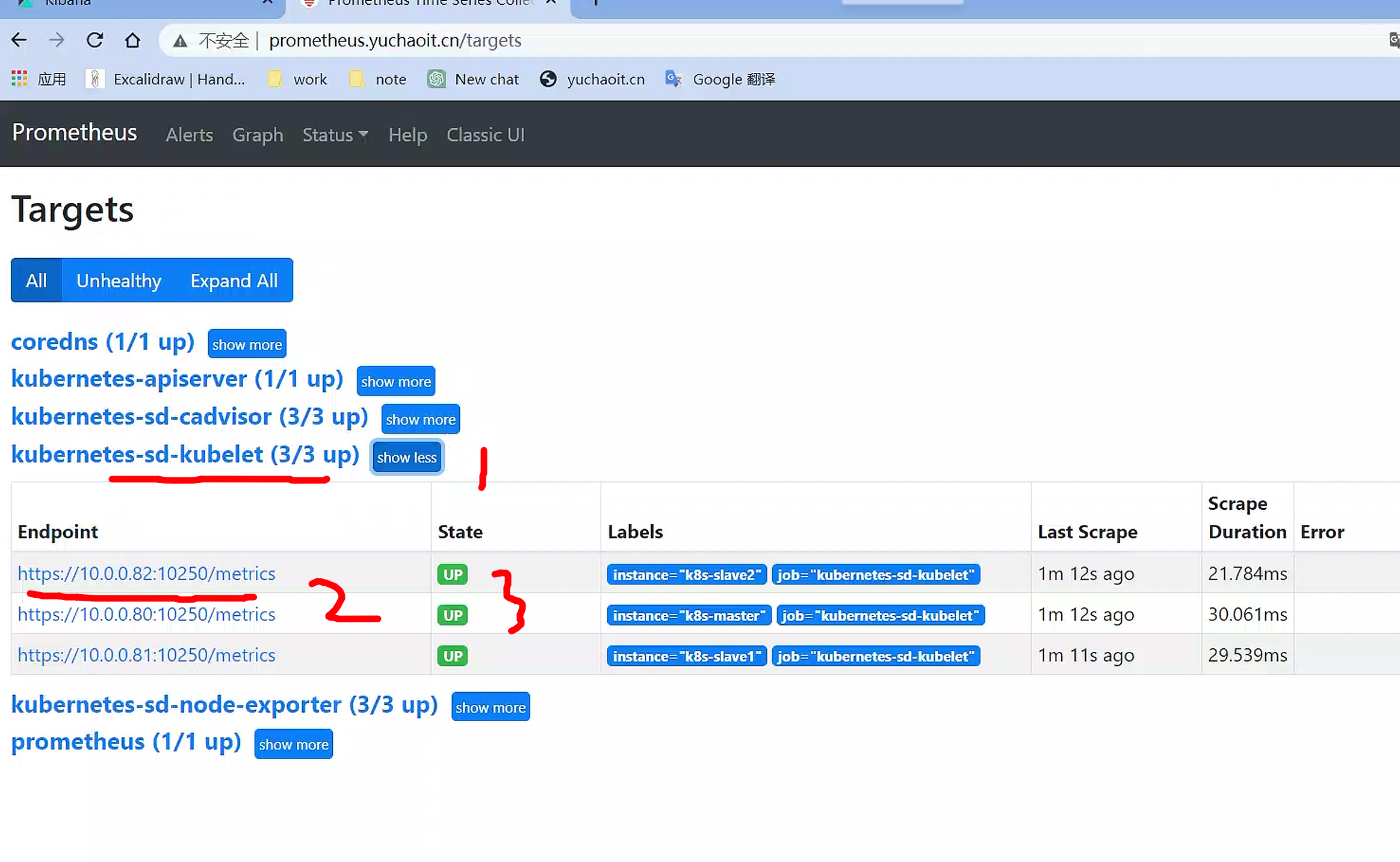
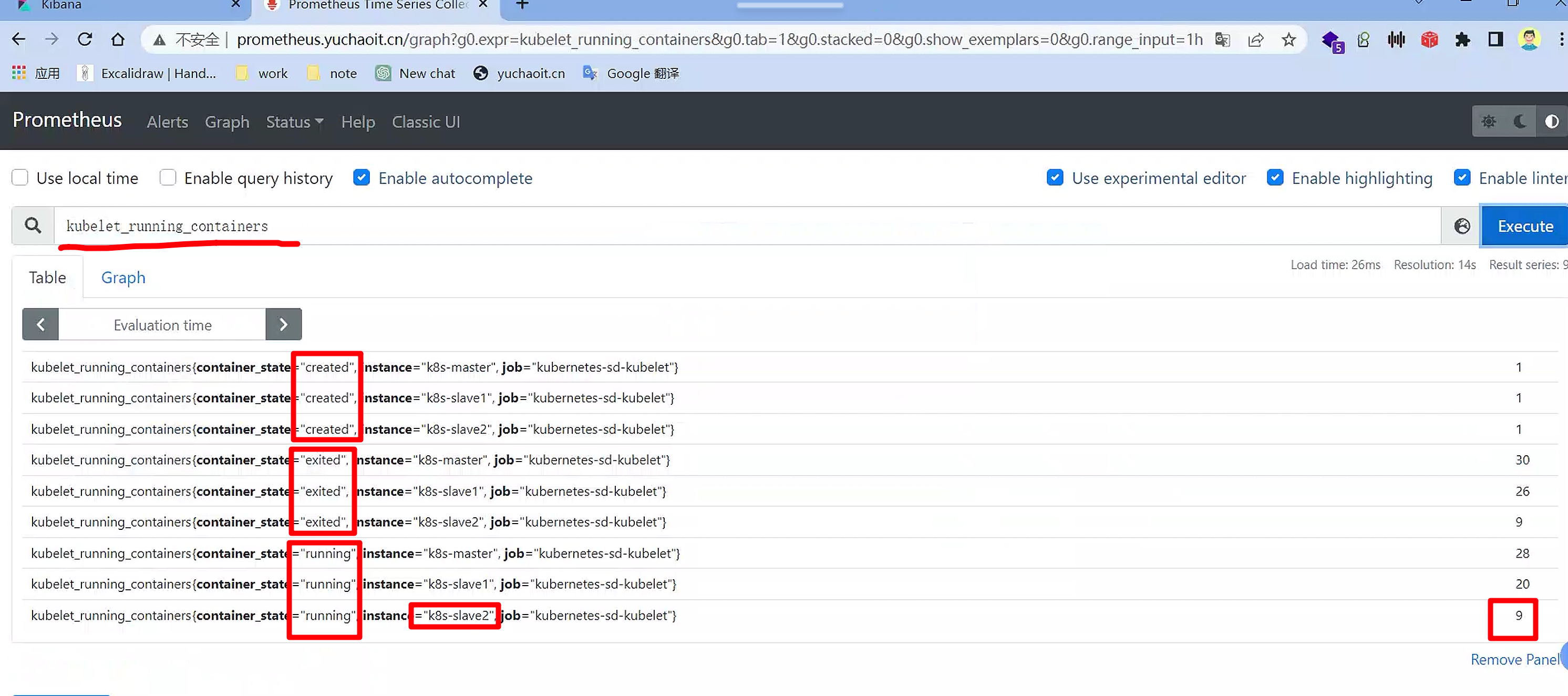
查看每个节点运行的容器数量
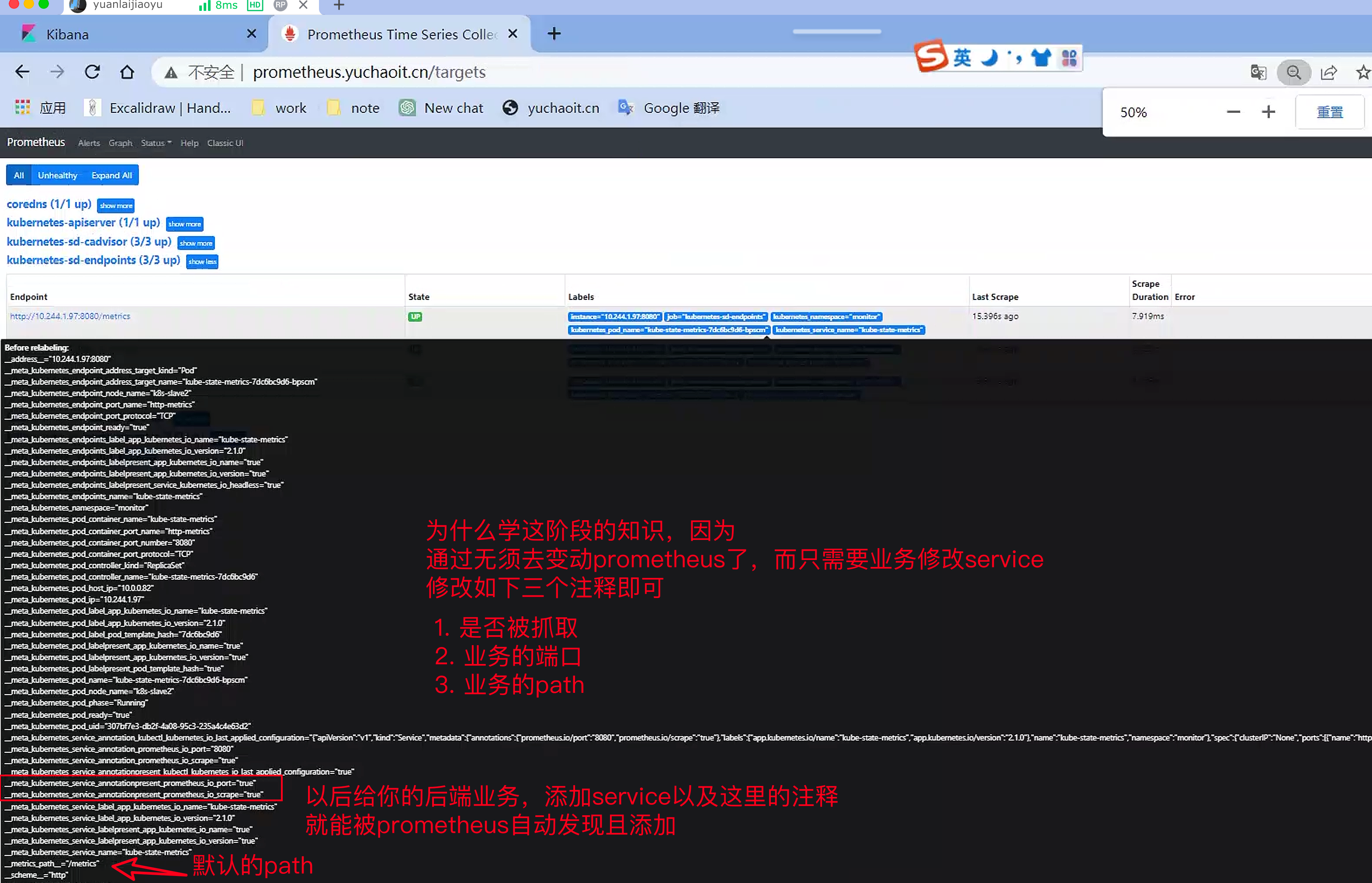
5.kube-state-metrics
kube-state-metrics 的确是监听 Kubernetes API server 并生成与对象状态相关的指标数据,例如节点、Pod、服务等。kube-state-metrics 的重点不是关注 Kubernetes 组件的健康状况,而是关注 Kubernetes 内部各种对象的健康状况。
同时,kube-state-metrics 会生成未经修改的 Kubernetes API 对象的指标数据,以确保这些数据的稳定性和准确性与 Kubernetes API 对象本身一致。因此,在某些情况下,kube-state-metrics 显示的指标数据可能与 kubectl 显示的数据略有不同,因为 kubectl 在显示可理解的消息时应用了某些启发式方法。kube-state-metrics 显示的指标数据是未经修改的原始数据,用户可以根据需要自行执行启发式方法。
这些指标数据以纯文本格式在 HTTP 端口(默认为 8080)的 /metrics 端点上进行导出,并且旨在由 Prometheus 或兼容 Prometheus 客户端端点的爬取器消耗。用户还可以在浏览器中打开 /metrics 端点以查看原始指标数据。请注意,/metrics 端点公开的指标数据反映了 Kubernetes 集群的当前状态。当 Kubernetes 对象被删除后,它们将不再在 /metrics 端点上显示。
项目下载地址
https://github.com/kubernetes/kube-state-metrics#kubernetes-deployment
为什么学这个组件
cadvisor 可以提供有关容器运行时的指标数据,但是它并不能提供关于 Kubernetes API 对象的状态的指标数据。
相比之下,kube-state-metrics 的作用是轮询 Kubernetes API 并将 Kubernetes API 对象的结构化信息转换为指标数据,包括有关节点、Pod、服务等对象的信息。
因此,如果需要获取诸如您所述的 Kubernetes API 对象的状态信息,就需要使用 kube-state-metrics 来收集和暴露这些指标数据。
虽然已经有了cadvisor,容器运行的指标已经可以获取到,但是下面这种情况却无能为力:
- 我调度了多少个replicas?现在可用的有几个?
- 多少个Pod是running/stopped/terminated状态?
- Pod重启了多少次?
而这些则是kube-state-metrics提供的内容,它基于client-go开发,轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics。因此,需要借助于kube-state-metrics来实现。
简单说,前面都是为了采集到k8s集群本身的信息,如容器,如kubelet,如node节点。
下一步肯定是要针对应用级别的指标采集,你nginx跑在deployment里,
指标类别
指标类别包括:
- CronJob Metrics
- DaemonSet Metrics
- Deployment Metrics
- Job Metrics
- LimitRange Metrics
- Node Metrics
- PersistentVolume Metrics
- PersistentVolumeClaim Metrics
- Pod Metrics
- kube_pod_info
- kube_pod_owner
- kube_pod_status_phase
- kube_pod_status_ready
- kube_pod_status_scheduled
- kube_pod_container_status_waiting
- kube_pod_container_status_terminated_reason
- ...
- Pod Disruption Budget Metrics
- ReplicaSet Metrics
- ReplicationController Metrics
- ResourceQuota Metrics
- Service Metrics
- StatefulSet Metrics
- Namespace Metrics
- Horizontal Pod Autoscaler Metrics
- Endpoint Metrics
- Secret Metrics
- ConfigMap Metrics
安装
[root@k8s-master ~/prometheus-all]#wget https://github.com/kubernetes/kube-state-metrics/archive/v2.1.0.tar.gz
# 部署需要的yaml
[root@k8s-master ~/prometheus-all/kube-state-metrics-2.1.0]#cd examples/standard/
[root@k8s-master ~/prometheus-all/kube-state-metrics-2.1.0/examples/standard]#ls
cluster-role-binding.yaml cluster-role.yaml deployment.yaml service-account.yaml service.yaml
# 修改配置信息
sed -i 's/namespace: kube-system/namespace: monitor/g' ./*
sed -i 's#k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.1.0#bitnami/kube-state-metrics:2.1.0#g' ./deployment.yaml
# 创建应用
[root@k8s-master ~/prometheus-all/kube-state-metrics-2.1.0/examples/standard]#kubectl apply -f .
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
serviceaccount/kube-state-metrics created
service/kube-state-metrics created
# 启动成功
[root@k8s-master ~]#kubectl -n monitor get po
NAME READY STATUS RESTARTS AGE
kube-state-metrics-7dc6bc9d6-bpscm 1/1 Running 0 58s
node-exporter-68n2w 1/1 Running 0 5d17h
node-exporter-6z9sj 1/1 Running 0 5d17h
node-exporter-rkrgh 1/1 Running 0 5d17h
prometheus-6c8768547-v7hqq 1/1 Running 0 5d20h
如何添加到target
# 该组件默认指标接口8080
[root@k8s-master ~]#curl 10.244.1.97:8080/metrics
方案1,和前面一样,添加job_name,修改configmap,但是如果有100个应用要添加,是否有更高效的方案。
基于endpoints的服务发现
如果你添加如下配置,prometheus会自动采集所有集群内的enpoints地址的ip。也就是pod地址了
- job_name: 'kubernetes-sd-endpoints'
kubernetes_sd_configs:
- role: endpoints
例如如下的命令
[root@k8s-master ~]#kubectl get endpoints -A
在 Kubernetes 中,Service 和 Endpoint 是紧密相关的两种对象类型。Service 对象是一个抽象的逻辑概念,用于表示一组 Pod 实例或者虚拟机实例的集合,并通过 Cluster IP 或者 LoadBalancer IP 对外提供服务。而 Endpoint 则是 Service 的一部分,用于表示可提供服务的实际网络地址和端口。
Service 与 Endpoint 的关系可以通过如下方式来理解:
- Service 对象包含一个或多个 Endpoint 对象。
- 每个 Endpoint 对象表示一个可提供服务的实例或者副本集。
- Endpoint 对象包含一个或多个 IP 地址和端口组合,用于表示该实例或者副本集的网络地址和端口。
当 Service 对象创建或更新时,Kubernetes 会自动更新与之相关的 Endpoint 对象,以确保它们的 IP 地址和端口信息与实际的 Pod 或者虚拟机实例一致。这样,通过 Service 对象可以轻松地发现集群中所有可提供服务的实例,而无需手动管理和更新 Endpoint 对象。
在 Prometheus 的配置文件中,通过指定 role 为 endpoints,可以发现 Kubernetes 集群中所有使用了特定 label 的 Endpoint,并采集指定端口相关的指标数据。这样,可以对每个实例或者副本集进行单独的监控和告警。而通过指定 role 为 service,则可以发现 Kubernetes 集群中所有使用了特定 label 的 Service,并采集与 Service 相关的指标数据,如请求数、响应时间等等。这样,可以对整个服务的运行状态进行监控和告警。
试试
68 - job_name: 'kubernetes-sd-kubelet'
69 kubernetes_sd_configs:
70 - role: node
71 scheme: https
72 tls_config:
73 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
74 insecure_skip_verify: true
75 bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
76 - job_name: 'kubernetes-sd-endpoints'
77 kubernetes_sd_configs:
78 - role: endpoints
[root@k8s-master ~]#kubectl -n monitor edit configmaps prometheus-config
configmap/prometheus-config edited
[root@k8s-master ~]#
[root@k8s-master ~]#curl -X POST 10.244.1.96:9090/-/reload
reload prometheush,此使的Target列表中,kubernetes-sd-endpoints下出现了N多条数据,
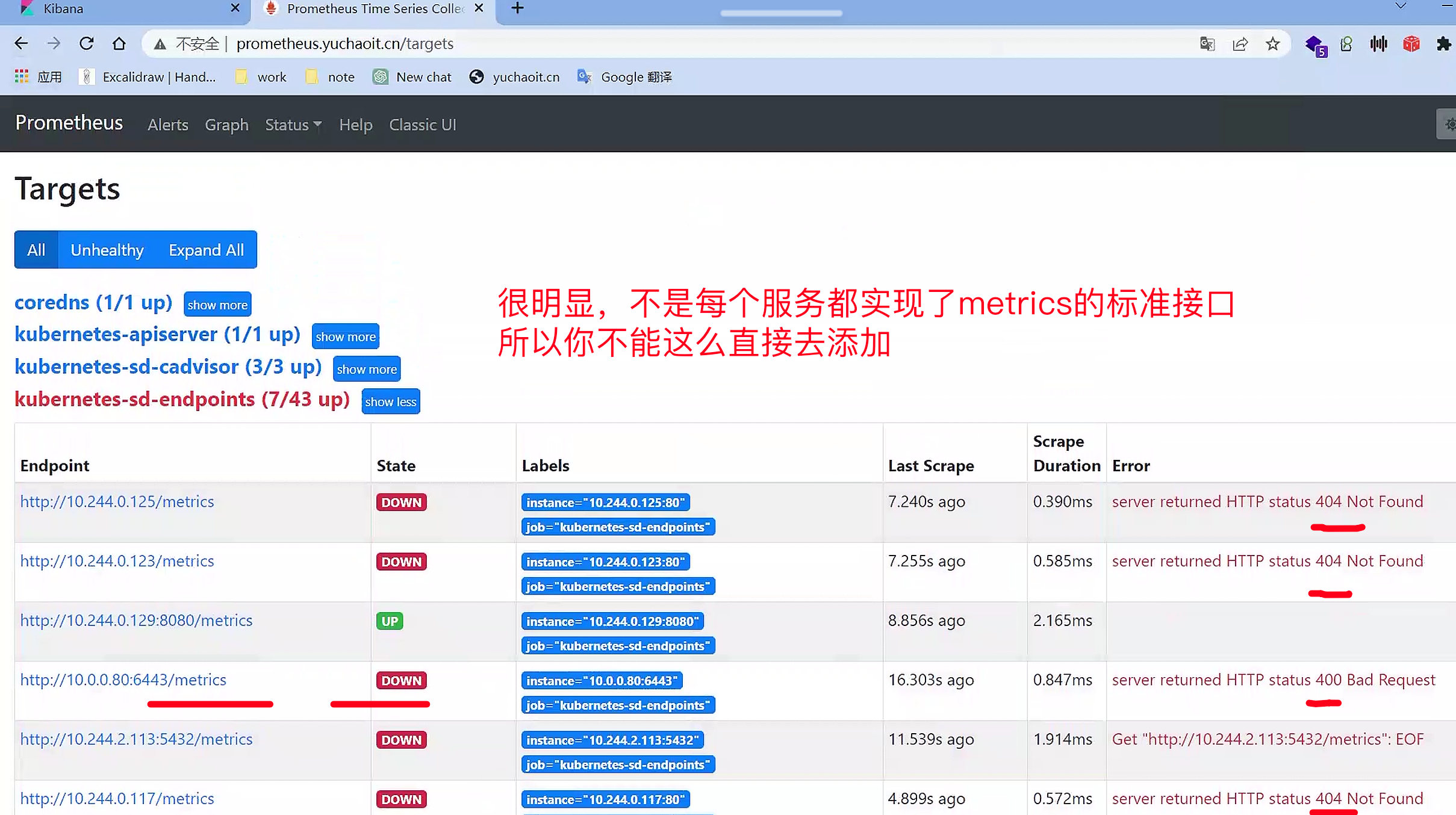
可以发现,实际上endpoint这个类型,目标是去抓取整个集群中所有的命名空间的Endpoint列表,然后使用默认的/metrics进行数据抓取,我们可以通过查看集群中的所有ep列表来做对比:
$ kubectl get endpoints --all-namespaces
但是实际上并不是每个服务都已经实现了/metrics监控的,也不是每个实现了/metrics接口的服务都需要注册到Prometheus中。
因此,我们需要一种方式对需要采集的服务实现自主可控,选择我们需要的业务接口。
这就需要利用relabeling中的keep功能。

基于service完成业务指标监控
公司业务以k8s形式部署运行,想采集业务运行指标,那就是基于service的监控。
继续看刚才说的relabel功能
我们知道,relabel的作用对象是target的Before Relabling标签,比如说,假如通过如下定义:
- job_name: 'kubernetes-sd-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
这是一个用YAML格式编写的Kubernetes对象配置片段,它为Prometheus提供了Kubernetes服务发现机制。
该配置指定了一个名为"kubernetes-sd-endpoints"的任务,通过"endpoints"的Kubernetes角色进行服务发现。
它还包含一个"relabel_configs"字段,其中的规则会筛选出被标记为"__meta_kubernetes_service_annotation_prometheus_io_scrape"的Kubernetes服务,并将其保留下来,否则就会被删除。
这个标记是为了让Prometheus知道哪些服务需要被监控。
其中"regex: true"表示匹配规则是一个正则表达式。
因此可以为我们期望被采集的服务,加上对应的Prometheus的label即可。
问题来了,怎么加?
技巧,查看集群coredns的metrics实现
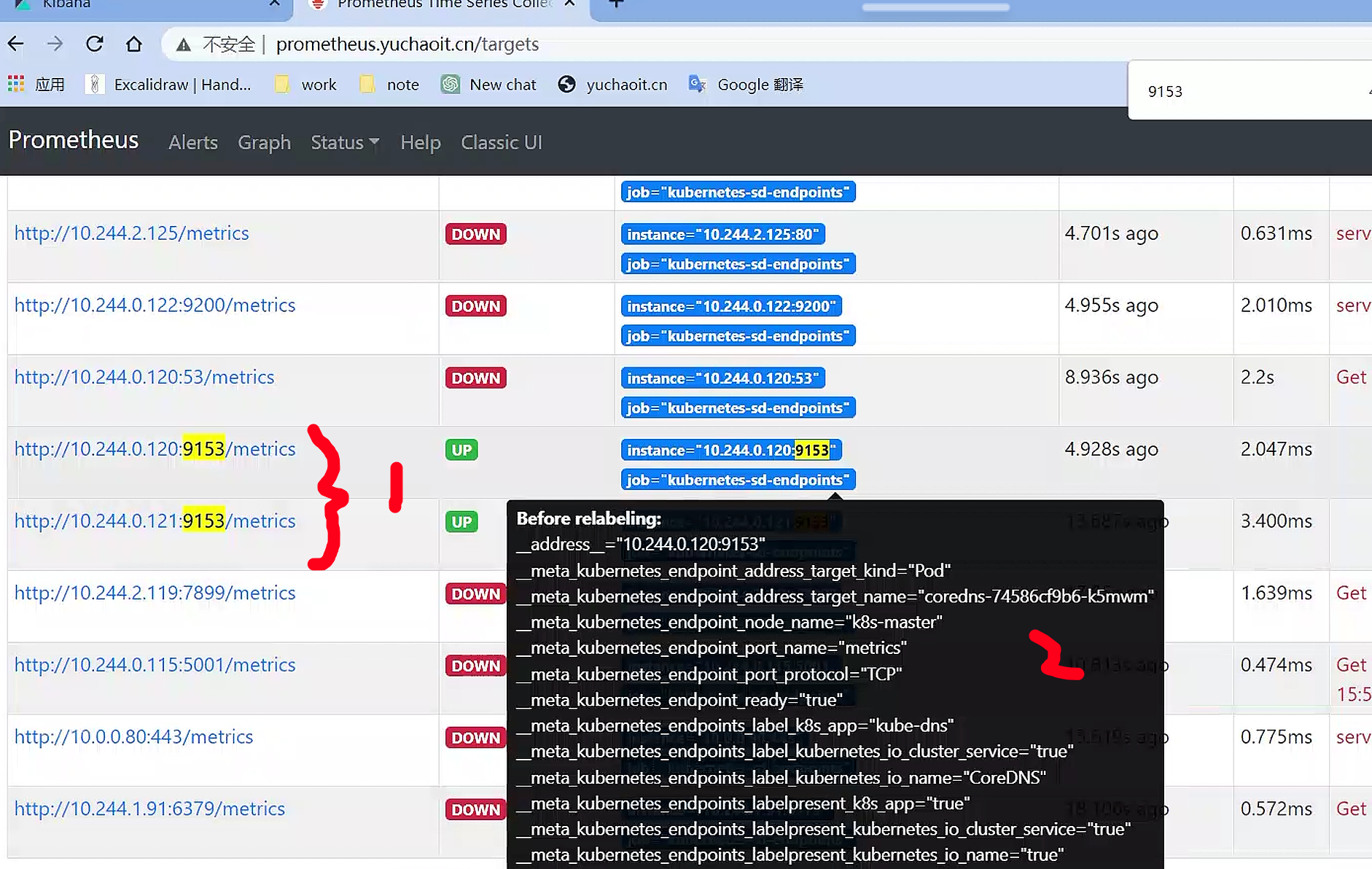
关于普罗米修斯的label
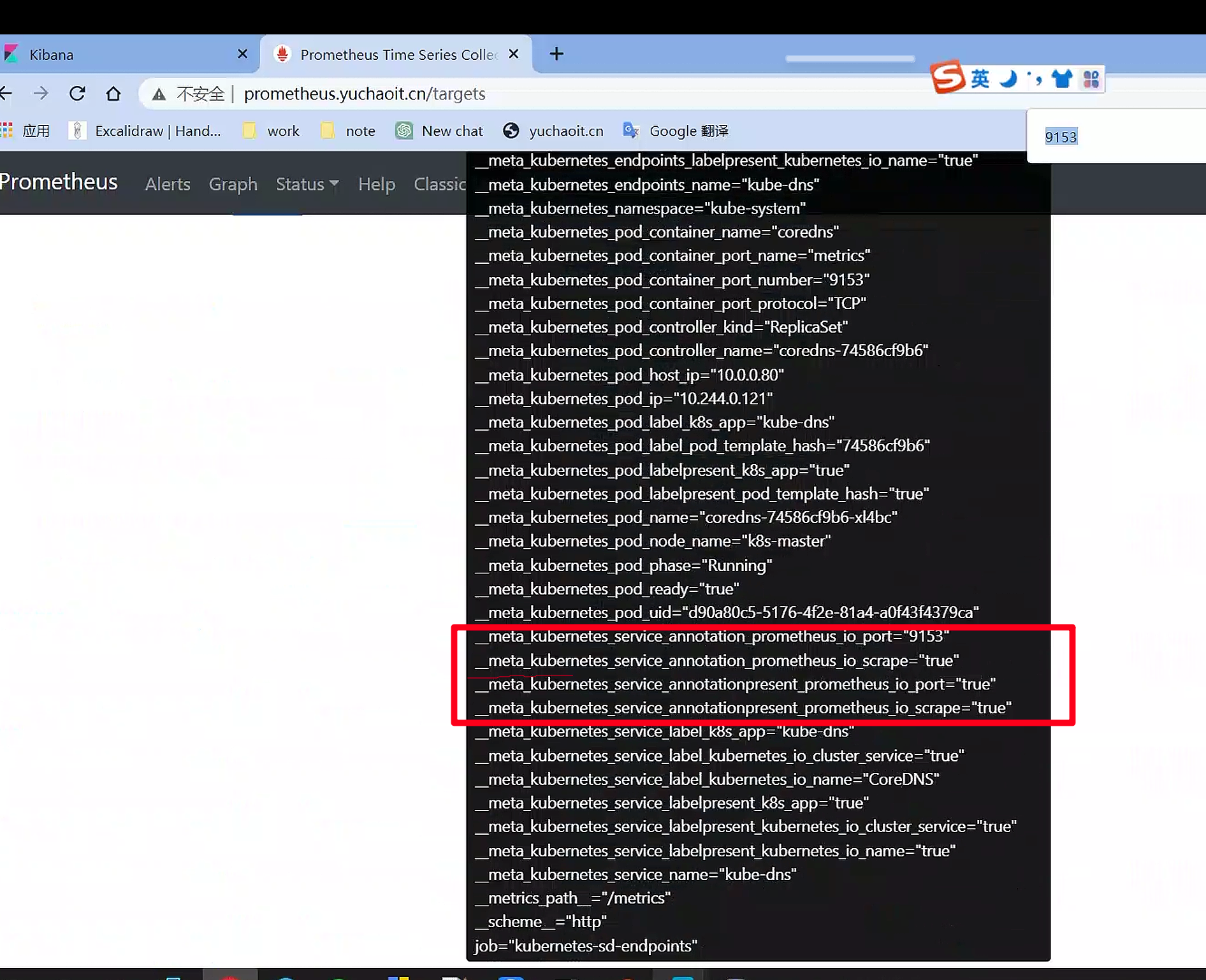
__meta_kubernetes_service_annotation_prometheus_io_scrape="true"
__meta_kubernetes_service_annotation_prometheus_io_port="9153"
这是两个Kubernetes服务的元标签(metadata)注释,用于配置Prometheus进行服务发现和监控。具体解释如下:
- "__meta_kubernetes_service_annotation_prometheus_io_scrape": 一个布尔值类型的标记,用于指示该服务是否应该被Prometheus监控。如果该标记被设置为"true",则Prometheus将监控该服务。
- "__meta_kubernetes_service_annotation_prometheus_io_port": 一个字符串类型的标记,用于指示该服务的端口号。如果该标记被设置,则Prometheus将使用指定的端口号监控该服务。
这些元标签注释通常是在Kubernetes服务对象的声明中设置的,以便Prometheus可以轻松地发现和监控Kubernetes集群中的服务。
查看coredns的service
[root@k8s-master ~]#kubectl -n kube-system get svc kube-dns -oyaml
apiVersion: v1
kind: Service
metadata:
annotations: # 找到了
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
creationTimestamp: "2023-03-09T15:55:09Z"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: CoreDNS
name: kube-dns
namespace: kube-system
resourceVersion: "234"
uid: 541cc4ae-6820-4509-abef-51c83586e8d4
spec:
clusterIP: 10.96.0.10
clusterIPs:
- 10.96.0.10
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
- name: metrics
port: 9153
protocol: TCP
targetPort: 9153
selector:
k8s-app: kube-dns
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
发现存在annotations声明,因此,可以联想到二者存在对应关系,Service的定义中的annotations里的特殊字符会被转换成Prometheus中的label中的下划线。
在Kubernetes中,可以使用Service的annotations声明来配置Prometheus的服务发现和监控。具体来说,Service对象的annotations中的键值对将转换为Prometheus中的标签(labels)。
例如,在Service的annotations中设置"prometheus.io/scrape: 'true'",相当于为Prometheus定义了一个标签"__meta_kubernetes_service_annotation_prometheus_io_scrape",并将其值设置为"true"。
因此,Prometheus可以通过查询这些标签来确定哪些服务需要被监控。
我们即可以使用如下配置,来定义服务是否要被抓取监控数据。
第一步,修改普罗米修斯的服务发现规则
- job_name: 'kubernetes-sd-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
实践
[root@k8s-master ~]#
[root@k8s-master ~]#kubectl -n monitor edit configmaps prometheus-config
configmap/prometheus-config edited
[root@k8s-master ~]#
[root@k8s-master ~]#curl -X POST 10.244.1.96:9090/-/reload
[root@k8s-master ~]#

如上四个endpoints是存在条件过滤的__meta_kubernetes_service_annotation_prometheus_io_scrape
但是这里还是不对的,这俩53不是我们需要的,还得对端口做设置
第二步,修改你的应用service配置
我们只需要为服务定义上如下的声明,即可实现Prometheus自动采集数据
annotations:
prometheus.io/scrape: "true"
这里上面基于kube-dns也检验过了,查看service的yaml。
第三步,有些时候,我们业务应用提供监控数据的path地址并不一定是/metrics,如何实现兼容?

同样的思路,我们知道,Prometheus会默认使用Before Relabling中的__metrics_path作为采集路径。
3.1 自定义采集path
Prometheus默认使用Before Relabling中的__metrics_path__作为采集路径,但是在一些特殊的情况下,我们可能需要指定自定义的采集路径。
在这种情况下,可以使用Service对象的annotations来指定采集路径。具体来说,可以在Service对象的annotations中添加一个"prometheus.io/path"标记来指定自定义的采集路径
具体来说,可以在Service对象的annotations中添加一个"prometheus.io/path"标记来指定自定义的采集路径,例如:
apiVersion: v1
kind: Service
metadata:
name: my-service
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: "/metrics/custom"
spec:
...
这样,Prometheus端会自动转换为如下标签:
__meta_kubernetes_service_annotation_prometheus_io_path="/path/to/metrics"
这个例子中,我们为名为"my-service"的Service对象添加了两个annotations标记。"prometheus.io/scrape: 'true'"标记用于启用Prometheus的服务发现和监控,而"prometheus.io/path: '/metrics/custom'"标记则指定了自定义的采集路径。
这意味着Prometheus会使用"/metrics/custom"作为采集路径来获取名为"my-service"的Service对象的指标数据。
然后,我们可以使用与之前类似的relabelconfigs来根据"prometheus.io/path"标记重写Prometheus的采集路径。例如,可以使用以下标签重写规则来将"prometheus.io/path"标记中的值替换为Prometheus的_metrics_path标签的值:
我们只需要在relabelconfigs中用该标签的值,去重写`_metrics_path`的值即可。因此:
68 - job_name: 'kubernetes-sd-kubelet'
69 kubernetes_sd_configs:
70 - role: node
71 scheme: https
72 tls_config:
73 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
74 insecure_skip_verify: true
75 bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
76
77 - job_name: 'kubernetes-sd-endpoints'
78 kubernetes_sd_configs:
79 - role: endpoints
80 relabel_configs:
81 - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
82 action: keep
83 regex: true
84 - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
85 action: replace
86 target_label: __metrics_path__
87 regex: (.+)
这样,Prometheus就可以使用自定义的采集路径来获取指标数据,并将它们存储到时序数据库中供后续的分析和可视化使用。
更新普罗米修斯,重载,并且再看看target更新
[root@k8s-master ~]#kubectl -n monitor edit configmaps prometheus-config
configmap/prometheus-config edited
[root@k8s-master ~]#curl -X POST 10.244.1.96:9090/-/reload
[root@k8s-master ~]#
# 检查configmap
[root@k8s-master ~]#kubectl -n monitor exec prometheus-6c8768547-v7hqq -- cat /etc/prometheus/prometheus.yml
注意,修改你的kube-dns的service,修改annotations
#
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/path: "/metrics/custom"
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
[root@k8s-master ~]#kubectl -n kube-system edit service kube-dns
service/kube-dns edited
[root@k8s-master ~]#
完成自定义指标接口的修改,就看你们公司
到这里,流程的学习就结束了,可以清理环境。
小结
至此,你发现了如何自定义监控应用的指标?
- 应用本身是否提供了metrics的HTTP指标数据
- 需要修改service的
annotations- 会动态更新prometheus的target
- 需要修改prometheus的configmap服务发现规则配置
如何自定义prometheus的指标API
在Prometheus中,用户可以通过自定义指标API来暴露自定义的监控指标。指标API是一种Web服务,它允许Prometheus从其他服务中获取指标数据。要自定义指标API,您可以使用以下步骤:
- 在您的应用程序中添加指标数据。Prometheus支持多种指标格式,包括Counter、Gauge、Histogram、Summary等。您可以使用Prometheus客户端库将指标数据暴露给Prometheus。在您的应用程序中添加指标数据后,就可以使用指标API将这些指标数据暴露给Prometheus。
- 创建一个指标API的HTTP处理程序。您可以使用任何Web框架来创建HTTP处理程序,只要它能够处理HTTP请求并返回指标数据即可。在处理程序中,您需要实现一个HTTP接口,以便Prometheus可以通过该接口获取指标数据。指标数据应该以Prometheus格式返回。
- 将指标API注册到Prometheus中。在Prometheus配置文件中,您需要添加一个新的job来定义您的指标API。在job中,您需要指定指标API的URL和其他配置信息。
- 重新启动Prometheus。一旦您的指标API已经注册到Prometheus中,您需要重新启动Prometheus以使其能够获取新的指标数据。
- 在Prometheus中查询指标数据。现在,您可以在Prometheus中使用查询语言PromQL来查询您的指标数据。您可以使用查询语言PromQL来创建自定义的监控指标,并将其与Prometheus内置的指标进行聚合和比较。
总的来说,自定义指标API是一种非常灵活和强大的功能,它使得Prometheus可以轻松地与各种不同类型的应用程序和服务集成,并监控它们的指标数据。
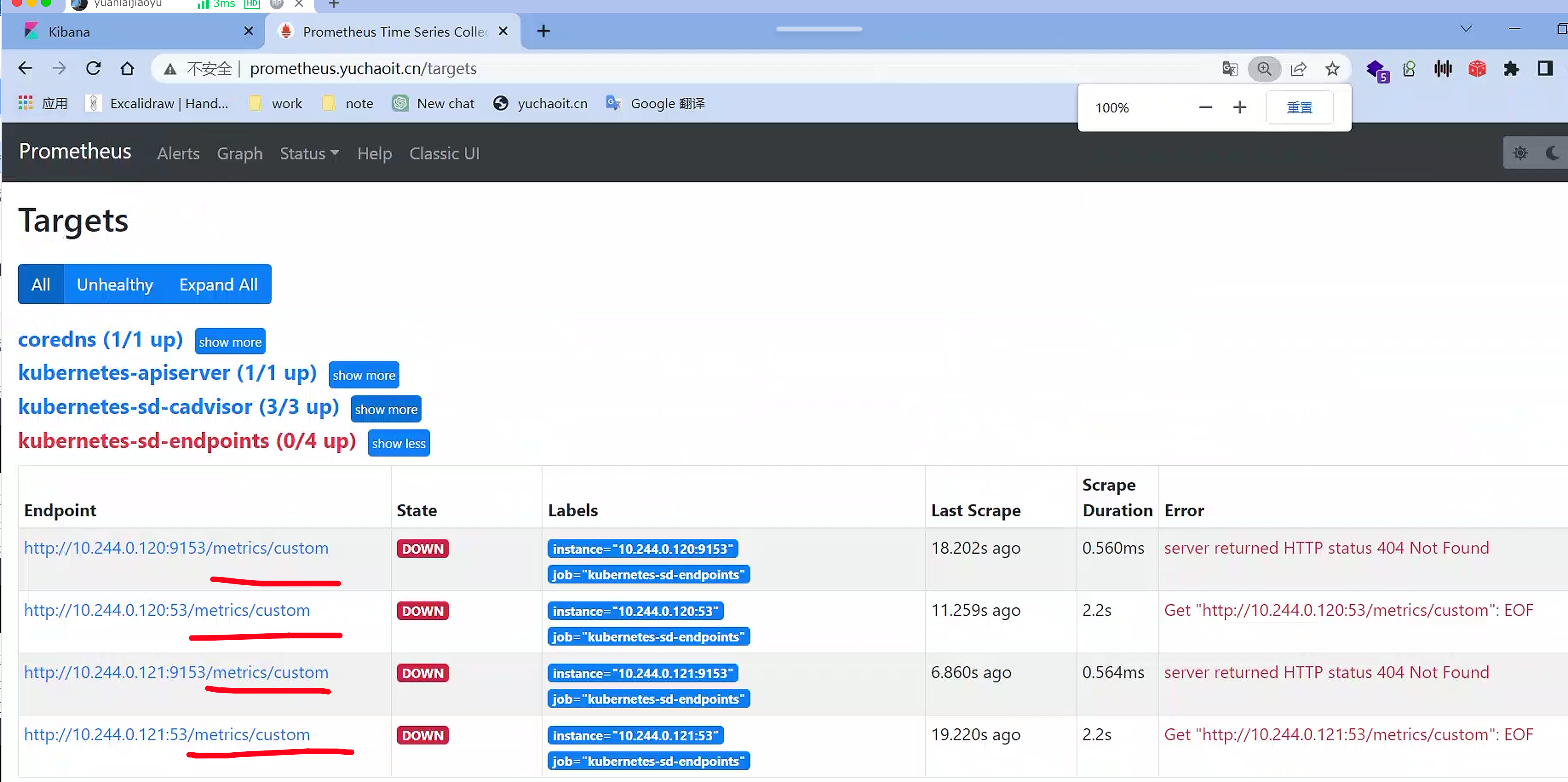
第四步,自定义端口

我们知道Prometheus默认使用Before Relabeling中的__address__进行作为服务指标采集的地址,但是该地址的格式通常是这样的
__address__="10.244.0.121:53"
__address__="10.244.0.121"
例如你的应用端口是9154如何改?
[root@k8s-master ~]#kubectl -n kube-system edit service kube-dns
service/kube-dns edited
# 如果修改你的service
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "9154"
prometheus.io/scrape: "true"
也可以看到,只要你修改了service的注释,prometheus里label自动更新
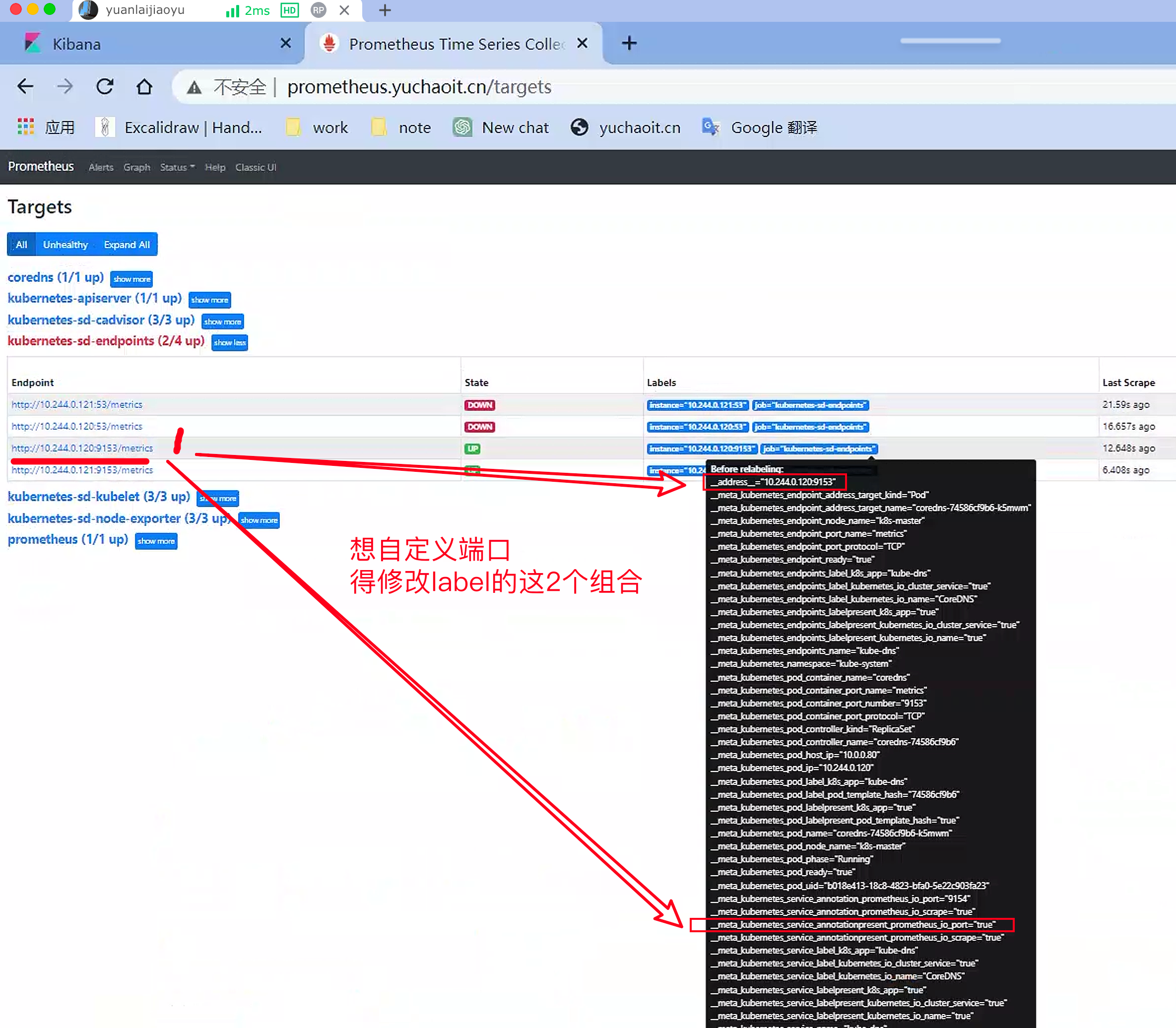
直接看官网给的例子
- job_name: 'kubernetes-sd-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_service_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
这段代码是Prometheus的一个job配置,它定义了一个使用Kubernetes的service discovery进行服务发现的job,并对这些服务进行监控。
具体来说,这个job将获取使用Kubernetes服务发现机制发现的所有endpoints,并在relabel_configs中进行处理,以适配Prometheus的数据采集方式。
具体的处理逻辑包括:
- 检查服务的annotations,如果有
prometheus.io/scrape注释,且值为true,则保留该服务进行监控。 - 检查服务的annotations,如果有
prometheus.io/path注释,则将其替换为Prometheus的__metrics_path__标签。 - 检查服务的地址和端口,如果服务地址中包含端口,则使用正则表达式将其拆分并将地址和端口分别存储在
__address__和__meta_kubernetes_service_annotation_prometheus_io_port标签中。 - 将服务的Kubernetes命名空间、服务名和Pod名称分别存储在
kubernetes_namespace、kubernetes_service_name和kubernetes_pod_name标签中,以便在Prometheus中进行查询和聚合。
这个job的目的是将Kubernetes集群中的所有服务和Pod的监控指标数据收集到Prometheus中,以便进行可视化和分析。
固定用法,就这么写记住也就可以了
可以检查target的结果
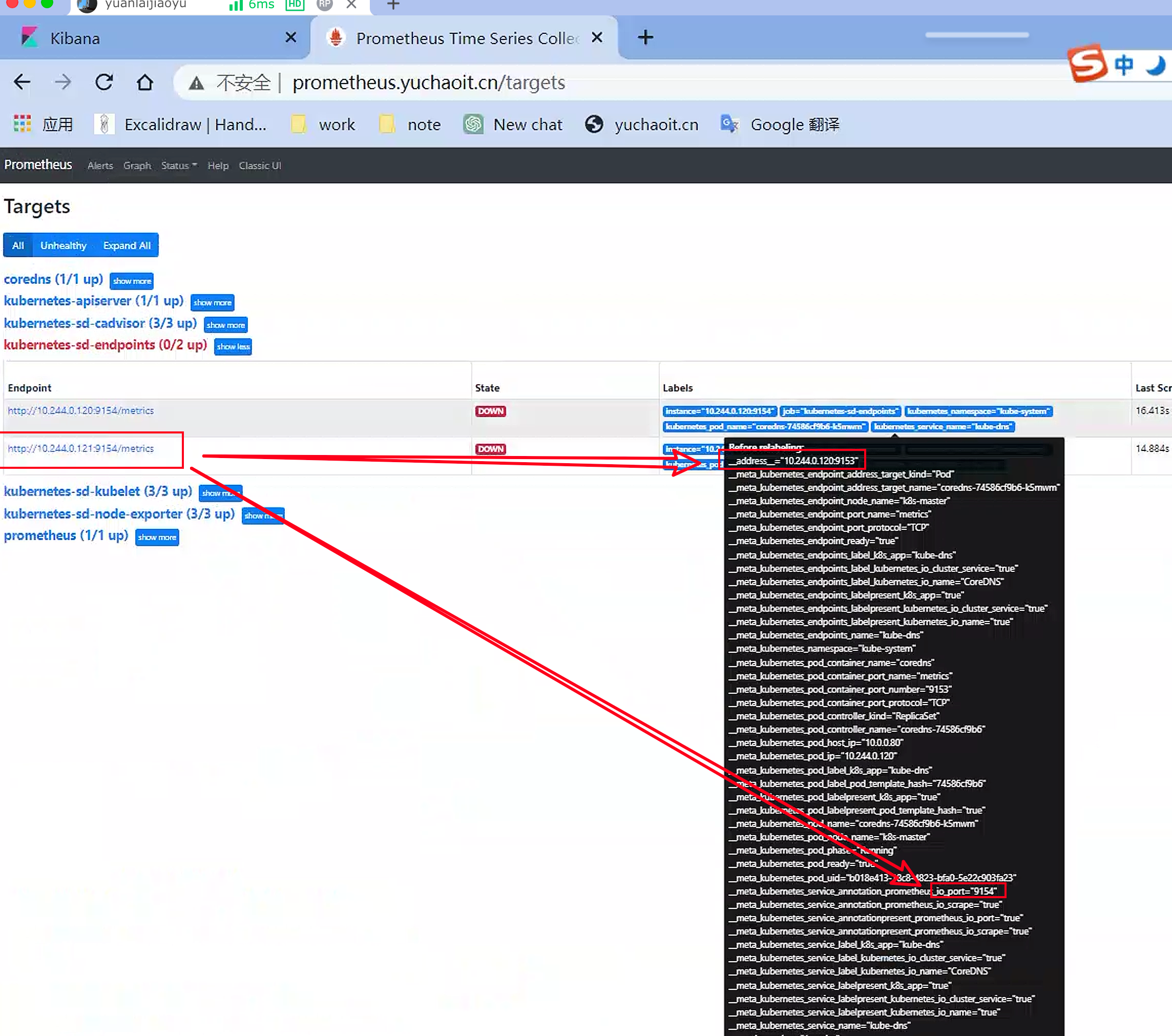
至此,将coredns的service修改回去,你的普罗米修斯,就已经修改完毕了配置文件。
接下来只需要修改业务的service,即可自动完成普罗米修斯的服务发现
识别API、识别端口
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
[root@k8s-master ~/prometheus-all]#kubectl -n kube-system edit service kube-dns
service/kube-dns edited

6.最后的验收
我们做了这么多的知识铺垫,都是为了理解最后的一个步骤。
修改前面kube-state-metrics的service
[root@k8s-master ~/prometheus-all/kube-state-metrics-2.1.0/examples/standard]#cat service.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080"
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.1.0
name: kube-state-metrics
namespace: monitor
spec:
clusterIP: None
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app.kubernetes.io/name: kube-state-metrics
更新
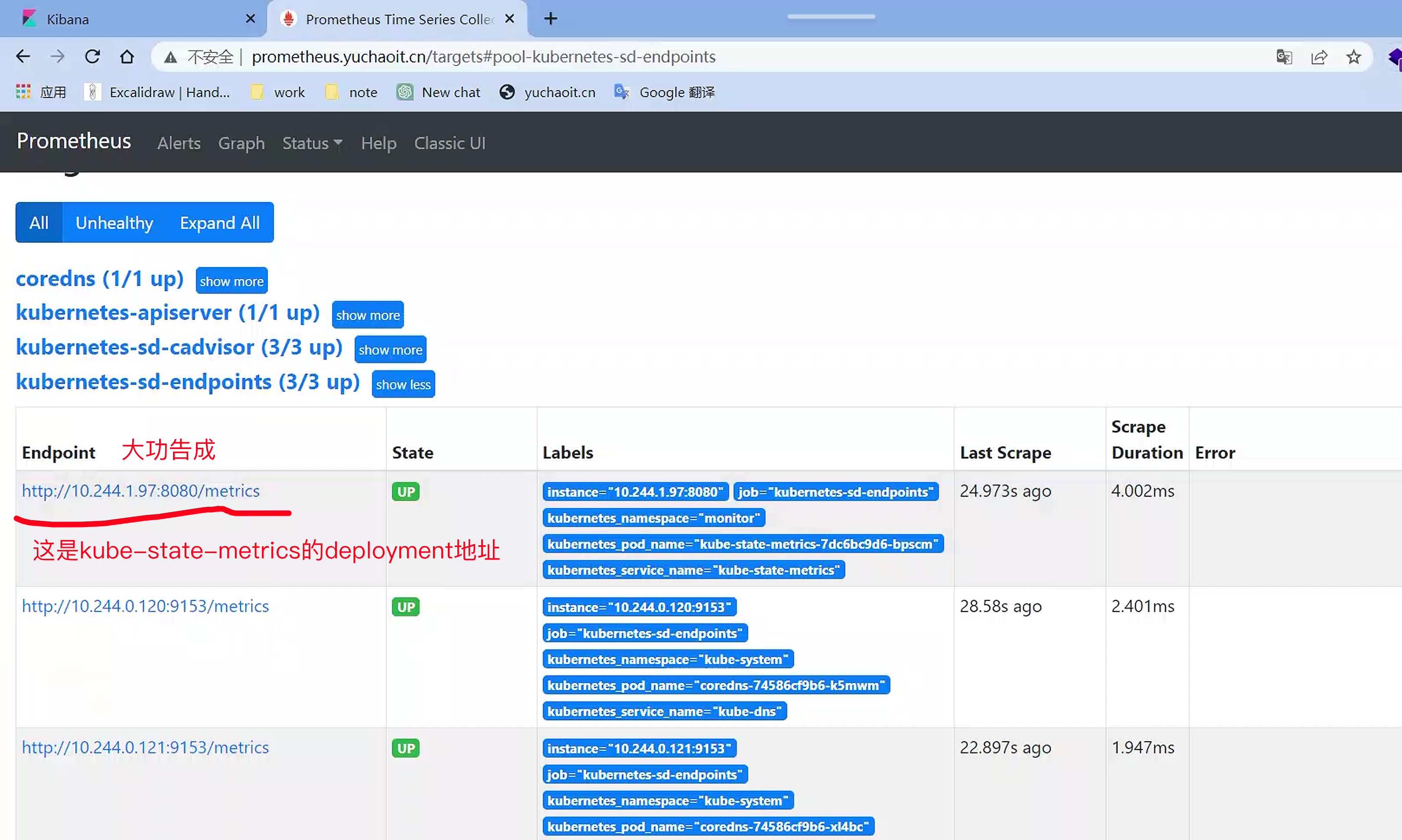
[root@k8s-master ~/prometheus-all/kube-state-metrics-2.1.0/examples/standard]#kubectl apply -f service.yaml
service/kube-state-metrics configured
查看target列表,是否自动加入了kube-state-metrics
查看target的kubernetes-sd-endpoints即可
于超老师友情提醒,prometheus公司会有专门做云原生监控的运维,铺垫好了环境。
后续只需要关心业务上的yaml修改,学会了本节内容,你方可理解为什么service里需要添加注释,就可以完成target监控的添加。
至此,有了监控,采集数据的工具,下一步就是学习如何更好的可视化展示数据。
查看target列表,观察是否存在kube-state-metrics的target。
kube_pod_container_status_running
kube_deployment_status_replicas
kube_deployment_status_replicas_unavailable