EFK日志架构
什么叫路,走的人多了,那就是路,所以我们初学一个技术,想短期内,学会,学好。
就跟着一条清晰的路走,去学,就能看到结果。
切记千万别瞎琢磨,乱学,只会让你很久都学不会。
本课程资料,是基于最新的containerd的日志采集架构,不同于docker日志的采集用法。
Kubernetes主流的日志采集架构通常包括以下组件:
- 应用程序:产生日志的容器应用程序
- 日志代理:负责从容器中收集日志并发送到后端存储
- 日志收集器:负责从日志代理中接收和存储日志数据,并提供查询和可视化功能
- 存储后端:用于存储日志数据的后端数据库或存储系统,例如Elasticsearch、Splunk或Kafka等
其中,常用的日志代理包括Fluentd、Filebeat和Logstash等。这些代理可以与容器化应用程序集成,通过容器日志卷或Kubernetes API收集应用程序的标准输出和标准错误输出。一旦收集到日志数据,这些代理将其转发到日志收集器进行处理。
常见的日志收集器包括ELK堆栈(Elasticsearch、Logstash和Kibana)和EFK堆栈(Elasticsearch、Fluentd和Kibana)。
这些工具提供了强大的日志分析和查询功能,使运维人员能够快速定位和解决问题。
最后,存储后端通常使用Elasticsearch等NoSQL数据库或者消息队列系统,例如Kafka和RabbitMQ等。这些存储后端提供了高可用性和可伸缩性,以满足大规模容器化应用程序的需求。
k8s日志架构资料
https://kubernetes.io/zh-cn/docs/concepts/cluster-administration/logging/
docker的日志存储架构
容器日志驱动:
https://docs.docker.com/config/containers/logging/configure/
查看当前的docker主机日志驱动:
json-file格式,docker会默认将标准和错误输出保存为宿主机的文件,路径为:
/var/lib/docker/containers/
[root@docker01 ~]#ls /var/lib/docker/containers/
也可以通过docker配置文件修改存储路径
[root@docker01 ~]#cat /etc/docker/daemon.json { "insecure-registries":[ "harbor.yuchaoit.cn", "10.0.0.66:5000" ], "registry-mirrors" : [ "https://ms9glx6x.mirror.aliyuncs.com" ],
"exec-opts": ["navite.cgroupdriver=systemd"], "graph":"/docker-data"
} [root@docker01 ~]# [root@docker01 ~]#systemctl daemon-reload [root@docker01 ~]# [root@docker01 ~]#systemctl restart docker [root@docker01 ~]#
检查新配置
[root@docker01 ~]#docker info |grep -i driver Storage Driver: overlay2 Logging Driver: json-file Cgroup Driver: cgroupfs
查看新的docker日志如何存储
[root@docker01 ~]#docker run -d --name=ngx01 nginx
[root@docker01 ~]#ls /docker-data/ buildkit containers image network overlay2 plugins runtimes swarm tmp trust volumes
docker logs查看到的容器日志,以json格式存储在该目录
[root@docker01 ~]#ll /docker-data/containers/21e0086c6b976d51e19364694db1cfa0583832bce61b4fe9c55a0d86126549b1/ total 28 -rw-r----- 1 root root 2568 Apr 25 13:53 21e0086c6b976d51e19364694db1cfa0583832bce61b4fe9c55a0d86126549b1-json.log drwx------ 2 root root 6 Apr 25 13:53 checkpoints -rw------- 1 root root 2824 Apr 25 13:53 config.v2.json -rw-r--r-- 1 root root 1467 Apr 25 13:53 hostconfig.json -rw-r--r-- 1 root root 13 Apr 25 13:53 hostname -rw-r--r-- 1 root root 174 Apr 25 13:53 hosts drwx--x--- 2 root root 6 Apr 25 13:53 mounts -rw-r--r-- 1 root root 51 Apr 25 13:53 resolv.conf -rw-r--r-- 1 root root 71 Apr 25 13:53 resolv.conf.hash
也可以修改daemon.json ,让docker支持日志的切割处理
{ "log-driver": "json-file", "log-opts": { "max-size": "10m", "max-file": "3", "labels": "production_status", "env": "os,customer" } }
## k8s日志存储
Kubernetes默认情况下将容器日志存储在各自的Pod文件夹中。每个Pod都有一个唯一的UID,而每个容器都有一个相对于该Pod的唯一标识符。这些UID和标识符通常可以在Kubernetes控制平面中看到。
Kubernetes的默认日志目录是`/var/log/pods`,在该目录下,每个容器的日志都存储在一个独立的子目录中。每个子目录的名称格式如下:
查看k8s-master节点上的pod日志
[root@k8s-master ~/charts]#ls /var/log/pods/
[root@k8s-master ~/charts]#ls /var/log/pods/ demo-nginx_nginx-7dd78f9597-bdrx6_243b1f2c-178c-492c-aea4-09006356e763
这些目录的命名规则可以解释为:
[pod名称]*[容器名称]-[随机字符串]*[UID]
其中:
- [pod名称]是Pod的名称,它由Kubernetes系统根据Pod模板中的规则自动生成。
- [容器名称]是Pod中容器的名称,可以在Pod模板中指定。
- [随机字符串]是一个随机生成的字符串,用于确保在同一Pod中运行多个相同容器时每个容器的日志目录是唯一的。
- [UID]是该Pod的唯一标识符,由Kubernetes系统自动生成并分配。
因此,这些目录中包含了每个Pod中每个容器的日志文件。
## k8s记录日志的方法
总体分为三种方式:
- 使用在每个节点上运行的节点级日志记录代理。
- 在应用程序的 pod 中,包含专门记录日志的 sidecar 容器。
- 将日志直接从应用程序中推送到日志记录后端。
> 节点级日志记录代理
使用在每个节点上运行的节点级日志记录代理,如 Fluentd、Logstash、Filebeat 等,可以轻松地收集并转发来自所有 Pod 的日志。代理可以通过从容器的 stdout/stderr 流中捕获日志,或从应用程序日志文件中收集日志,并将其转发到一些中心化日志存储或分析系统。
> sidecar 容器
在 Kubernetes 中,可以将专门记录日志的 sidecar 容器添加到应用程序 pod 中。这些容器与应用程序容器一起运行,并负责捕获、处理和推送日志。这种方法可以确保日志记录逻辑与应用程序代码逻辑彼此分离,从而更容易管理和维护日志记录。
> 直接推送日志
应用程序可以将其日志直接推送到日志记录后端,如 Elasticsearch、Logstash、Fluentd 等。应用程序可以通过标准输出或标准错误流来生成日志,并使用适当的库或工具将日志发送到日志记录后端。
总的来说,选择何种方式来记录应用程序日志,取决于您的具体需求和环境。每种方法都有其优缺点,需要根据实际情况来进行选择。
### 节点日志代理
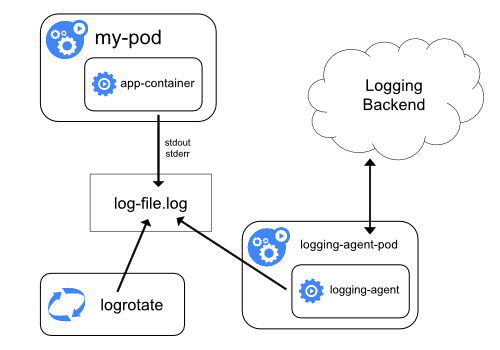
> 优势:
- 部署方便,使用DaemonSet类型控制器来部署agent即可
- 对业务应用的影响最小,没有侵入性
> 劣势:
- 只能收集标准和错误输出,对于容器内的文件日志,暂时收集不到
- 等于只能看到docker logs这样的日志
- 如果你容器内本地写入了一个如`/tmp/app.log`,是拿不到的
Kubernetes(k8s)节点级日志代理的好坏取决于使用场景和具体实现。一般而言,使用节点级日志代理的好处包括:
1. 高可用性:节点级代理可以确保即使节点上的容器故障,也可以保留日志,并将其发送到中央日志收集器。
2. 低延迟:通过在节点上收集和发送日志,可以减少将日志从容器传输到中央日志收集器所需的时间,从而提高了响应时间。
3. 支持多种协议和格式:由于许多节点代理支持多种协议和格式,因此可以轻松地将不同类型的应用程序和容器日志收集到同一个中央日志存储库中。
4. 可扩展性:可以将节点级代理配置为仅收集特定的容器日志,以便在需要时可以轻松添加新的容器并将其日志添加到集中式存储库中。
然而,使用节点级日志代理也存在一些潜在的风险和挑战:
1. 安全性问题:如果节点级代理没有得到适当的保护,可能会被攻击者利用来访问机密信息。
2. 性能开销:如果节点级代理没有得到适当的优化和调整,可能会对节点的性能造成负面影响。
3. 可用性问题:如果节点级代理无法正常工作,可能会导致丢失重要的日志信息。
综合考虑,节点级日志代理的好坏需要根据具体场景进行分析和评估。在使用时,应根据实际需求和安全要求来选择最合适的节点级代理,并对其进行适当的配置和管理。
### 使用 sidecar 容器和日志代理
在 Kubernetes 中,应用程序通常是运行在容器中的,因此应用程序的日志也是存储在容器内的。但是,使用容器日志来进行故障排除和监视可能会变得非常棘手。这是因为容器的生命周期比较短,容器启动和停止时会导致日志信息的丢失。此外,如果应用程序由多个容器组成,每个容器都需要管理自己的日志。
为了解决这个问题,可以使用 sidecar 容器和日志代理来捕获和处理应用程序的日志。sidecar 容器是一个额外的容器,可以与主容器并行运行在同一个 Pod 中,通过共享同一个文件系统和网络空间来访问主容器的日志文件。日志代理是一个专门的进程,可以负责将日志数据从 sidecar 容器收集并传输到目标存储或分析系统。
以下是使用 sidecar 容器和日志代理的好处:
1. 集中管理日志:使用 sidecar 容器和日志代理可以将所有的应用程序日志集中存储和管理,方便统一检索和分析。
2. 实时处理日志:日志代理可以实时收集和处理日志数据,从而使得故障排除和监视变得更加实时和精确。
3. 提高容器的可观测性:使用 sidecar 容器和日志代理可以提高容器的可观测性,因为您可以更轻松地监视应用程序的行为、排除故障和优化性能。
4. 灵活的日志存储和分析:使用日志代理,您可以将日志数据传输到各种存储和分析系统,例如 Elasticsearch、Fluentd、Logstash 等,以满足不同的需求和用例。
总之,使用 sidecar 容器和日志代理可以提高 Kubernetes 应用程序的可观测性、可维护性和可靠性,从而帮助您更好地管理和优化 Kubernetes 集群。
#### 方案1:sidecar 容器将应用程序日志传送到自己的标准输出。
> 在pod中启动一个sidecar容器,把容器内的日志文件吐到标准输出,由宿主机中的日志收集agent进行采集。
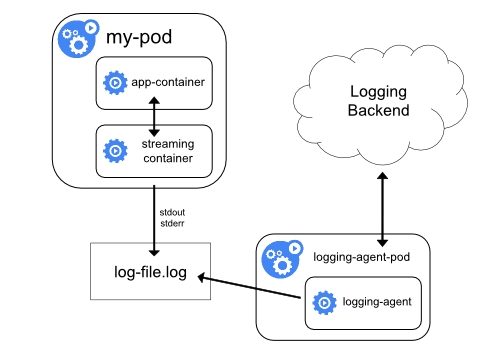
实践yaml
```yaml
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
创建pod,查看专门记录日志的容器信息
[root@k8s-master ~/k8s-all]#vim sidecar01.yaml
[root@k8s-master ~/k8s-all]#kubectl create -f sidecar01.yaml
pod/counter created
# 可以去看2个容器的日志
[root@k8s-master ~/k8s-all]#kubectl logs -f counter -c count-log-1
[root@k8s-master ~/k8s-all]#kubectl logs -f counter -c count-log-2
# count-log-1 和count-log-2 都是tail读取日志,输出到了stdout,因此可以kubectl logs看到
优势:
- 可以实现容器内部日志收集
- 对业务应用的侵入性不大
劣势:
- 每个业务pod都需要做一次改造
- 增加了一次日志的写入,对磁盘使用率有一定影响
该方案直接抛弃。
方案2:sidecar 容器运行一个日志代理,配置该日志代理以便从应用容器收集日志。
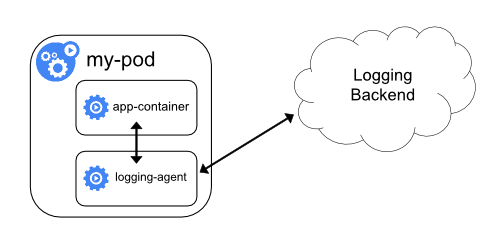
思路:直接在业务Pod中使用sidecar的方式启动一个日志收集的组件(比如fluentd),这样日志收集可以将容器内的日志当成本地文件来进行收取。
优势:不用往宿主机存储日志,本地日志完全可以收集
劣势:每个业务应用额外启动一个日志agent,带来额外的资源损耗。
企业在用日志架构
目前来讲,最建议的是采用节点级的日志代理。
方案一:自研方案,实现一个自研的日志收集agent,大致思路:
- 针对容器的标准输出及错误输出,使用常规的方式,监听宿主机中的容器输出路径即可
- 针对容器内部的日志文件
- 在容器内配置统一的环境变量,比如LOG_COLLECT_FILES,指定好容器内待收集的日志目录及文件
- agent启动的时候挂载docker.sock文件及磁盘的根路径
- 监听docker的容器新建、删除事件,通过docker的api,查出容器的存储、环境变量、k8s属性等信息
- 配置了LOG_COLLECT_FILES环境变量的容器,根据env中的日志路径找到主机中对应的文件路径,然后生成收集的配置文件
- agent与开源日志收集工具(Fluentd或者filebeat等)配合,agent负责下发配置到收集工具中并对进程做reload
方案二:日志使用开源的Agent进行收集(EFK方案),适用范围广,可以满足绝大多数日志收集、展示的需求。

EFK也就是如此架构图方案了。
为什么是EFK架构
但是为什么k8s官方推荐使用fluentd作为k8s体系的日志收集工具?
云原生:https://github.com/kubernetes/kubernetes/tree/release-1.21/cluster/addons/fluentd-elasticsearch
fluentd已默认作为k8s内置日志插件。
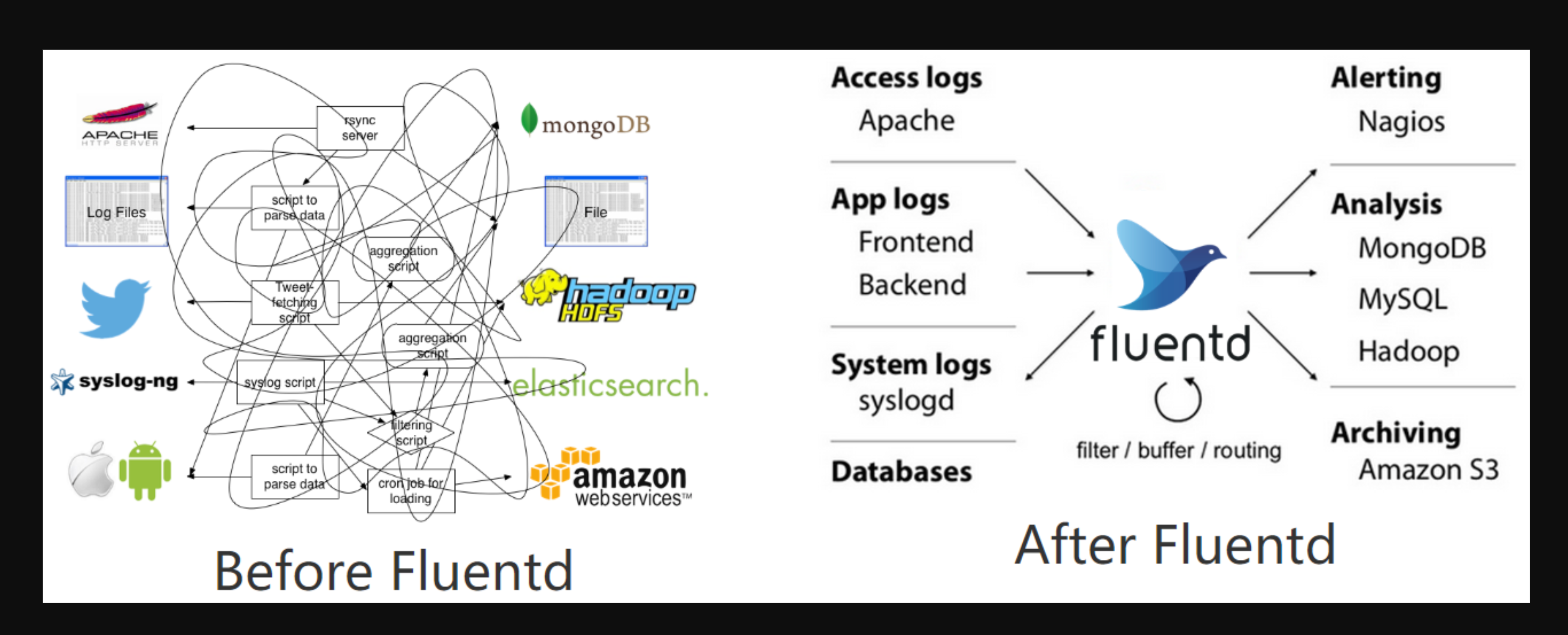
之前于超老师也讲解过传统的EFK架构,主要是Elasticsearch、Filebeat、Kibana三个组件。
Fluentd 是一个开源的日志收集和转发工具,它能够将来自不同数据源的日志进行统一的收集和转发,支持丰富的插件和定制化配置,广泛应用于云原生生态系统中。以下是推荐在 Kubernetes 中使用 Fluentd 作为日志收集工具的一些原因:
- 支持多种数据源:Fluentd 支持从多种数据源收集日志,包括文件、TCP/UDP、HTTP、Syslog 等,同时支持多种数据格式,如 JSON、CSV、Apache Log 等。这些特性使得 Fluentd 能够轻松地处理 Kubernetes 集群中各种组件的日志,包括容器、宿主机、API Server、kubelet 等。
- 处理灵活:Fluentd 提供了丰富的插件和配置选项,可以灵活地定制日志收集和处理过程。例如,可以使用 regex 插件对日志进行正则匹配和提取,使用 filter 插件对日志进行过滤和转换,使用 output 插件将日志输出到多种目标,如 Elasticsearch、Kafka、S3 等。
- 容错性高:Fluentd 采用了可插拔的架构,可以轻松地进行扩展和定制,同时支持多种错误处理机制,如重试、缓冲、转储等,使得它在面对异常情况时能够保证日志收集的可靠性和完整性。
- 社区活跃:Fluentd 是一个开源项目,有一个活跃的社区支持和维护,提供了广泛的文档和例子,方便用户学习和使用。同时,Fluentd 还与 Kubernetes 生态系统紧密集成,如提供了 Fluentd DaemonSet、Fluentd Kubernetes Metadata Filter 等插件,使得在 Kubernetes 中使用 Fluentd 更加便捷和高效。
综上所述,Fluentd 是一个高度可定制和可扩展的日志收集工具,可以轻松地处理 Kubernetes 集群中的各种组件的日志,并且具有良好的容错性和社区支持,因此在 Kubernetes 中使用 Fluentd 是一个不错的选择。
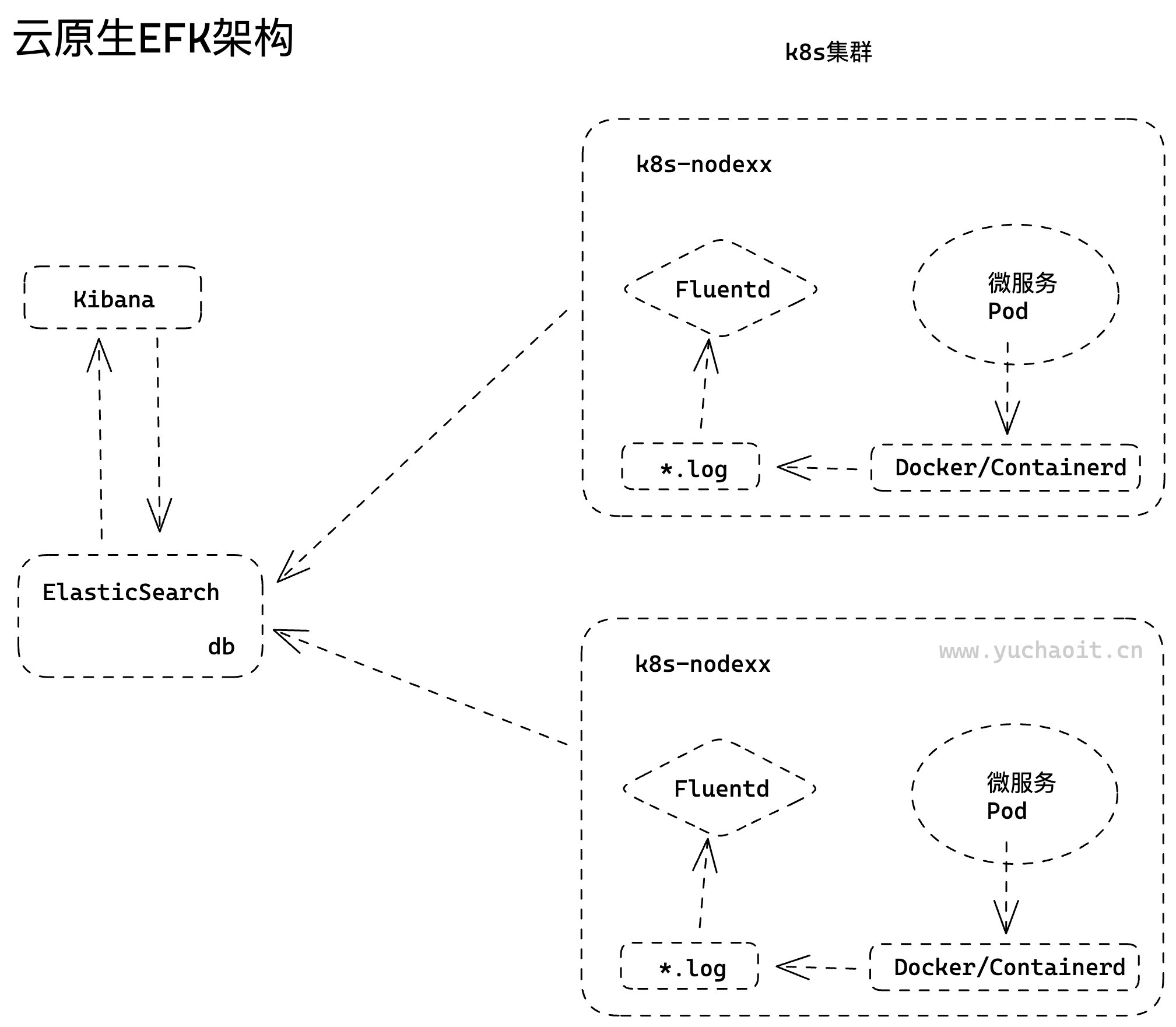
注意该EFK三个组件,本身就很复杂是成熟的大型软件,我们先不关心该软件本身的复杂玩法,理解EKF架构如何采集k8s日志即可。
Elasticsearch
EFK是一个日志管理解决方案,包括三个开源组件:Elasticsearch、Fluentd和Kibana。其中,Elasticsearch是EFK中的一个核心组件,是一个高度可扩展、分布式的搜索和分析引擎,用于存储和索引日志数据。
Elasticsearch可以快速地处理大量结构化和非结构化数据,具有快速的搜索、分析和可视化能力。它可以通过HTTP API提供数据访问,并且支持实时数据索引和搜索。在EFK中,Elasticsearch负责接收、存储和处理Fluentd收集的日志数据,并支持强大的搜索和查询功能。
通过使用Elasticsearch,用户可以轻松地搜索和分析其应用程序生成的海量日志数据,帮助快速排查问题、诊断错误和优化系统性能。
kibana
Kibana是EFK解决方案中的一个组件,是一个用于可视化和分析大量数据的开源工具。它提供了一个直观易用的Web界面,可以帮助用户从Elasticsearch中检索和分析数据,并可视化和呈现数据结果。
Kibana提供了各种图表和可视化工具,例如柱状图、线图、饼图、地图等等,让用户能够轻松地探索和呈现其数据。同时,Kibana也支持高级搜索和过滤功能,可以帮助用户深入挖掘数据,发现有价值的信息和趋势。
除了数据可视化和搜索功能之外,Kibana还提供了一个交互式仪表板,用户可以使用该仪表板创建自定义仪表板,将不同的可视化工具和数据源组合在一起,实现快速、简单地监控和分析数据的目的。
总之,Kibana是EFK解决方案中的一个强大工具,提供了强大的数据可视化、搜索和分析功能,帮助用户更轻松地处理和理解其日志和数据。
Fluentd
Fluentd是EFK解决方案中的另一个组件,是一个轻量级的开源日志收集器,用于收集、传输和存储大量日志数据。它支持多种输入和输出插件,并可以将日志数据转换为不同的格式。
Fluentd的一个主要功能是收集分散在不同地方的日志数据,例如应用程序日志、服务器日志和网络设备日志。它可以收集来自多个来源的数据,并将其转发到Elasticsearch进行处理和分析。
Fluentd具有灵活和可扩展的架构,用户可以通过编写自定义插件来扩展其功能。它还支持各种协议和数据格式,并且具有内置的过滤器,用于解析和转换不同格式的数据。
总之,Fluentd是EFK解决方案中的一个重要组件,用于收集、传输和存储大量日志数据。它具有灵活的架构和丰富的插件生态系统,可以帮助用户轻松地处理和管理其日志数据。

Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储、kafka等等。
Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下
- 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务
Fluentd作用
将日志文件JSON化
将文件数据结构化处理

将日志文件JSON化通常使用Fluentd(也称为Fluent)来完成。Fluentd是一种数据收集和转换的开源工具,可以帮助将不同格式的日志和数据从各种源(如应用程序、服务器和设备)发送到各种目标(如数据库、存储桶和消息队列)。
要将日志文件JSON化,需要使用Fluentd的输入插件来读取日志文件并使用输出插件将其转换为JSON格式。下面是一个使用Fluentd将日志文件JSON化的示例配置文件:
<source>
@type tail
path /path/to/your/logfile.log
pos_file /var/log/fluentd/buffer/tail.log.pos
tag json.log
format none
read_from_head true
</source>
<match json.log>
@type parser
key_name log
reserve_data true
<parse>
@type none
</parse>
</match>
<match json.log>
@type stdout
</match>
在这个配置文件中,tail输入插件将读取/path/to/your/logfile.log日志文件,并将其标记为json.log。parser输出插件将log字段解析为JSON,并将其保留在原始日志中。
stdout输出插件将JSON格式的日志输出到标准输出。你可以将stdout替换为任何其他输出插件,例如file,elasticsearch等。
可插拔架构设计
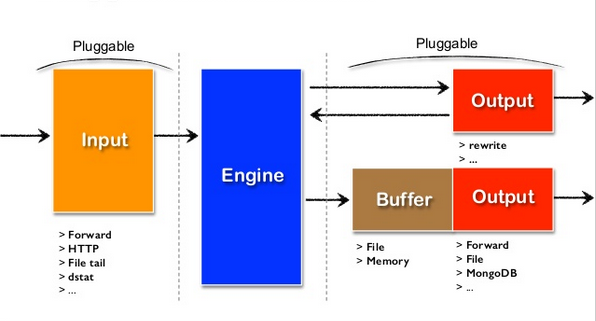
市面上如此之多的软件,都以插件形式,很方便的接入,例如数据分别写入到ES、kafka都安装额外的插件即可。
极小的资源占用
Fluentd是一种开源数据收集器,专门用于可扩展的日志收集。
Fluentd被称为极小的资源占用是因为它的内存占用相对较小,且可以在各种硬件和操作系统上运行。
它可以在C和Ruby语言中运行,使用的内存通常在30-40MB之间。
此外,Fluentd还支持多线程,并且每个核心可以处理约13,000个事件/秒,这使得它在高吞吐量环境中表现非常出色。
Fluentd的核心部分是用C语言编写的,而一些插件和配置文件则可以用Ruby语言编写。
因此,Fluentd可以在C和Ruby语言的混合环境中运行,这使得Fluentd具有高效性能和灵活性。
C语言具有较高的执行效率和低内存占用,而Ruby语言则提供了更方便易用的接口和丰富的功能库。
通过结合使用这两种语言,Fluentd既可以满足高性能的数据收集需求,也可以提供灵活的扩展性和可定制性。

极强的可靠性
fluentd被认为具有极强的可靠性是因为它具有以下特点:
- 基于内存和本地文件的缓存:Fluentd使用内存和本地文件缓存机制来保证数据的可靠性。当Fluentd无法将数据发送到目标时,它将缓存数据,等待连接恢复后再次尝试发送。此外,Fluentd还支持使用缓存文件将数据写入磁盘,以防止数据丢失。
- 强大的故障转移:Fluentd提供了强大的故障转移机制,使其能够自动恢复故障和错误。例如,当Fluentd无法将数据发送到目标时,它将自动重试并记录错误信息,以帮助管理员快速解决问题。另外,Fluentd还支持基于标签的故障转移和多节点部署,以进一步提高可靠性。
综上所述,Fluentd的缓存机制和故障转移机制使其能够高效地处理大量数据并确保数据的可靠性,从而被认为具有极强的可靠性。
fluentd实践
1.收集nginx日志
- 配置fluent.conf
- 使用@tail插件通过监听access.log文件
- 启动fluentd服务
- 手动追加内容至access.log文件
- 观察本地输出内容是否符合预期
准备好nginx服务,以及access.log
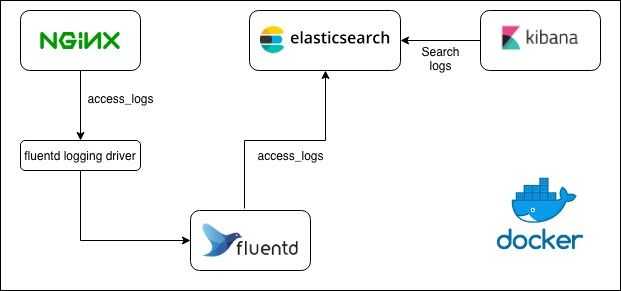
# fluentd官方提供的k8s教程
https://github.com/fluent/fluentd-kubernetes-daemonset
# 1.创建容器,测试fluntd用法,去采集nginx的日志
docker run -u root --rm -ti --entrypoint='' fluent/fluentd-kubernetes-daemonset:v1-debian-elasticsearch-amd64 bash
# 2.创建配置文件
cat > fluent.conf <<EOF
<source>
@type tail
path /var/log/nginx/access.log
pos_file /var/log/nginx/nginx_access.posg
tag nginx_access
format none
@log_level trace
</source>
<match nginx_access>
@type stdout
</match>
EOF
# 这段配置很简单,就是数据源,/var/log/nginx/access.log ,fluentd读取解析后,输出到stdout
这段代码是用来配置 Fluentd,用于收集和处理日志数据。
其中,<source> 指定了日志数据源,使用 tail 插件监视 /var/log/nginx/access.log 文件,pos_file 指定了记录读取进度的文件路径(已处理的标志位),tag 用于标记数据流,format 指定了数据格式,这里设置为 none 表示不对日志数据进行解析。
<match> 则指定了日志数据的输出目标,使用 stdout 插件将数据输出到标准输出流,也可以是ES、kafka等,这里等于直接输出给容器的stdout。
@log_level 指定了日志级别,这里设置为 trace 表示输出最详细的日志信息。
#启动fluentd
root@452669cd8250:/home/fluent# fluentd -c fluent.conf
2023-04-25 09:28:48 +0000 [info]: parsing config file is succeeded path="fluent.conf"
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-concat' version '2.5.0'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-dedot_filter' version '1.0.0'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-detect-exceptions' version '0.0.14'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-elasticsearch' version '5.1.4'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-grok-parser' version '2.6.2'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-json-in-json-2' version '1.0.2'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-kubernetes_metadata_filter' version '2.9.2'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-multi-format-parser' version '1.0.0'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-parser-cri' version '0.1.1'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-prometheus' version '2.0.2'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-record-modifier' version '2.1.0'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-rewrite-tag-filter' version '2.4.0'
2023-04-25 09:28:48 +0000 [info]: gem 'fluent-plugin-systemd' version '1.0.5'
2023-04-25 09:28:48 +0000 [info]: gem 'fluentd' version '1.14.3'
2023-04-25 09:28:48 +0000 [info]: using configuration file: <ROOT>
<source>
@type tail
path "/var/log/nginx/access.log"
pos_file "/var/log/nginx/nginx_access.posg"
tag "nginx_access"
format none
@log_level "trace"
<parse>
@type none
unmatched_lines
</parse>
</source>
<match nginx_access>
@type stdout
</match>
</ROOT>
2023-04-25 09:28:48 +0000 [info]: starting fluentd-1.14.3 pid=15 ruby="2.6.9"
2023-04-25 09:28:48 +0000 [info]: spawn command to main: cmdline=["/usr/local/bin/ruby", "-Eascii-8bit:ascii-8bit", "/fluentd/vendor/bundle/ruby/2.6.0/bin/fluentd", "-c", "fluent.conf", "--under-supervisor"]
2023-04-25 09:28:48 +0000 [info]: adding match pattern="nginx_access" type="stdout"
2023-04-25 09:28:48 +0000 [info]: adding source type="tail"
2023-04-25 09:28:48 +0000 [info]: #0 starting fluentd worker pid=20 ppid=15 worker=0
2023-04-25 09:28:48 +0000 [debug]: #0 tailing paths: target = | existing =
2023-04-25 09:28:48 +0000 [info]: #0 fluentd worker is now running worker=0
再开一个终端,安装nginx,以及测试日志
root@452669cd8250:/home/fluent# apt update
root@452669cd8250:/home/fluent# apt install nginx curl -y
# 测试命令
10 curl 127.0.0.1
11 curl 127.0.0.1/a
12 curl 127.0.0.1/b
13 curl 127.0.0.1/c
14 curl 127.0.0.1/d
15 curl 127.0.0.1/www.yuchaoit.cn
# 以及用如下命令去理解,什么是容器的stdout
[root@docker01 ~]#docker logs -f nifty_shaw
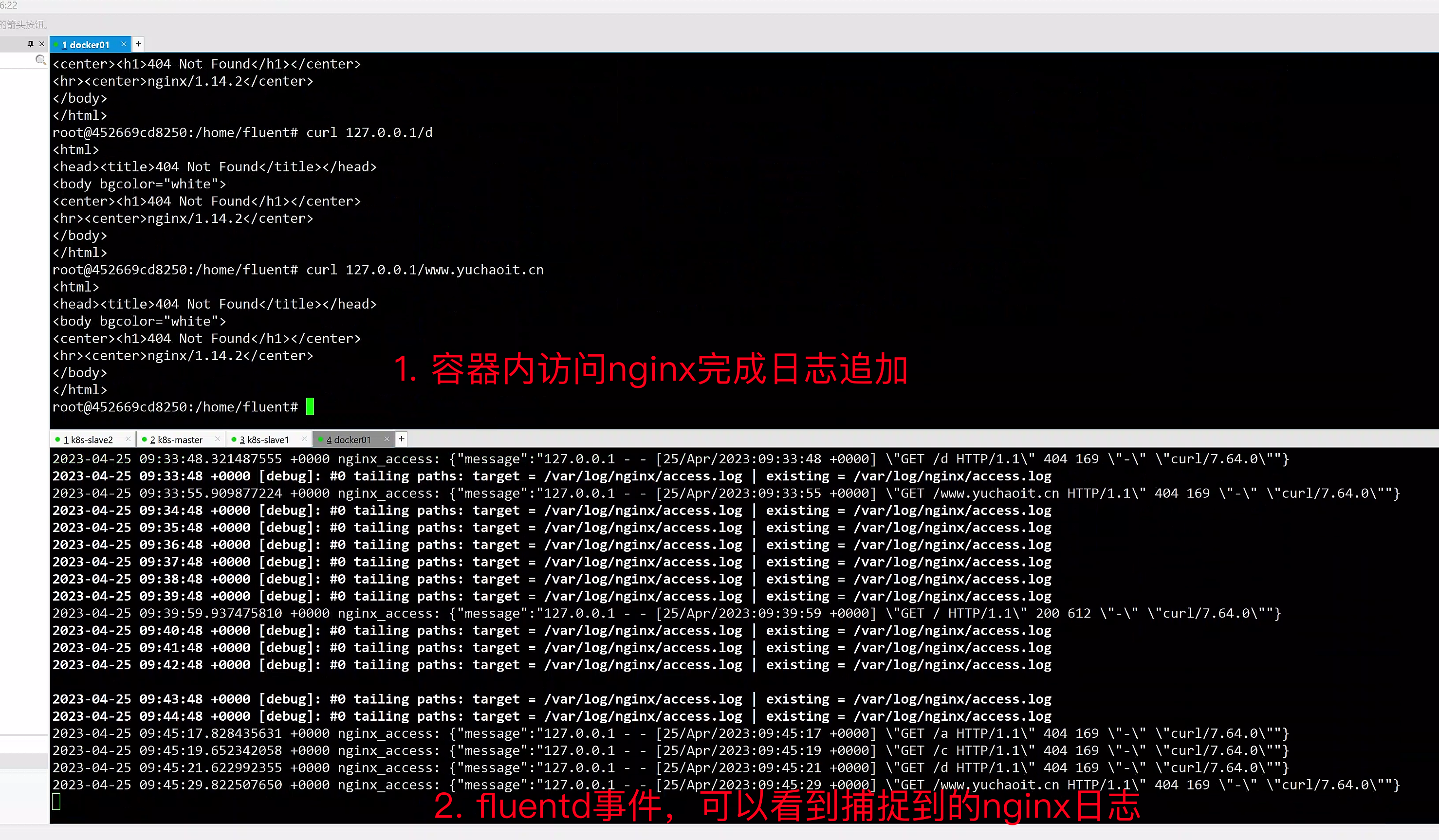
fluentd事件解读
- 时间戳:2023-04-25 09:36:48 +0000
- 日志级别:debug
- 日志内容:#0 tailing paths: target = /var/log/nginx/access.log | existing = /var/log/nginx/access.log
其中,日志内容的解读如下:
- #0:代表 tail 插件配置中的 tag 号,可以用来区分不同的 tail 配置;
- tailing paths:表示正在进行的文件追踪操作;
- target = /var/log/nginx/access.log:指定要追踪的文件路径;
- existing = /var/log/nginx/access.log:表示已经存在的文件路径,如果追踪的文件不存在,则 existing 字段为空。
事件格式
Fluentd 的事件(Event)是由三个主要部分组成:
- 时间戳(Time):事件发生的时间,通常使用标准时间格式(例如ISO 8601)表示。
- 标签(Tag):标记事件的来源,通常由 Fluentd 配置文件中的
<source>模块定义。 - 记录(Record):真实的日志内容,是一个键值对或 JSON 对象,包含事件的详细信息,也可以在 Fluentd 配置文件中进行修改或增加。
2.收集nginx且转json
转json、或者转其他格式后,也就有更强的适配性,让其他应用读取日志数据。
收集容器内的nginx应用的access.log日志,并解析日志字段为JSON格式,原始日志的格式为:
root@452669cd8250:/home/fluent# tail /var/log/nginx/access.log
127.0.0.1 - - [25/Apr/2023:09:33:44 +0000] "GET /a HTTP/1.1" 404 169 "-" "curl/7.64.0"
127.0.0.1 - - [25/Apr/2023:09:33:45 +0000] "GET /b HTTP/1.1" 404 169 "-" "curl/7.64.0"
127.0.0.1 - - [25/Apr/2023:09:33:47 +0000] "GET /c HTTP/1.1" 404 169 "-" "curl/7.64.0"
127.0.0.1 - - [25/Apr/2023:09:33:48 +0000] "GET /d HTTP/1.1" 404 169 "-" "curl/7.64.0"
127.0.0.1 - - [25/Apr/2023:09:33:55 +0000] "GET /www.yuchaoit.cn HTTP/1.1" 404 169 "-" "curl/7.64.0"
127.0.0.1 - - [25/Apr/2023:09:39:59 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.64.0"
127.0.0.1 - - [25/Apr/2023:09:45:17 +0000] "GET /a HTTP/1.1" 404 169 "-" "curl/7.64.0"
127.0.0.1 - - [25/Apr/2023:09:45:19 +0000] "GET /c HTTP/1.1" 404 169 "-" "curl/7.64.0"
127.0.0.1 - - [25/Apr/2023:09:45:21 +0000] "GET /d HTTP/1.1" 404 169 "-" "curl/7.64.0"
127.0.0.1 - - [25/Apr/2023:09:45:29 +0000] "GET /www.yuchaoit.cn HTTP/1.1" 404 169 "-" "curl/7.64.0"
root@452669cd8250:/home/fluent#
fluent.conf
http://fluentular.herokuapp.com/
https://docs.fluentd.org/parser/nginx 直接拿来就用
cat > fluent.conf <<'EOF'
<source>
@type tail
path /var/log/nginx/access.log
pos_file /var/log/fluentd/access.log.pos
tag nginx.access
<parse>
@type regexp
expression /^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)"(?:\s+(?<http_x_forwarded_for>[^ ]+))?)?$/
time_format %d/%b/%Y:%H:%M:%S %z
</parse>
read_from_head true
</source>
<match nginx.access>
@type stdout
</match>
EOF
# 重启
fluentd -c fluent.conf
配置解读
@type: Fluentd插件的类型。在此示例中,使用的是tail输入插件,它允许Fluentd在文件中追踪新的行并解析它们。path: 日志文件的路径。Fluentd将从此文件读取日志数据。pos_file: 存储读取位置的文件路径。当Fluentd停止时,它会将其当前的位置记录在该文件中,以便在Fluentd重新启动时继续从上次读取的位置开始读取。如果此文件不存在,Fluentd将从文件开头开始读取。tag: 给日志记录打标签,以便Fluentd将它们转发到正确的输出插件。在这个例子中,标签为nginx.access。: 用于指定解析日志数据的方式。在此示例中,使用的是正则表达式解析器,用于解析Nginx的访问日志格式。 标签包含两个参数: @type: 解析器的类型。在这个例子中,使用的是正则表达式解析器。expression: 解析正则表达式。time_format: 日期格式。
read_from_head: 指示Fluentd是否应该从文件的开头读取。在此示例中,该参数被设置为true。<match>: 用于指定Fluentd应该将日志数据转发到哪个输出插件。在这个例子中,输出插件是stdout,它将日志记录打印到控制台。
该format语法可以直接拿来官方文档,结合对正则的理解调整即可。
http://fluentular.herokuapp.com/
用这个网站校验正则
重启fluentd
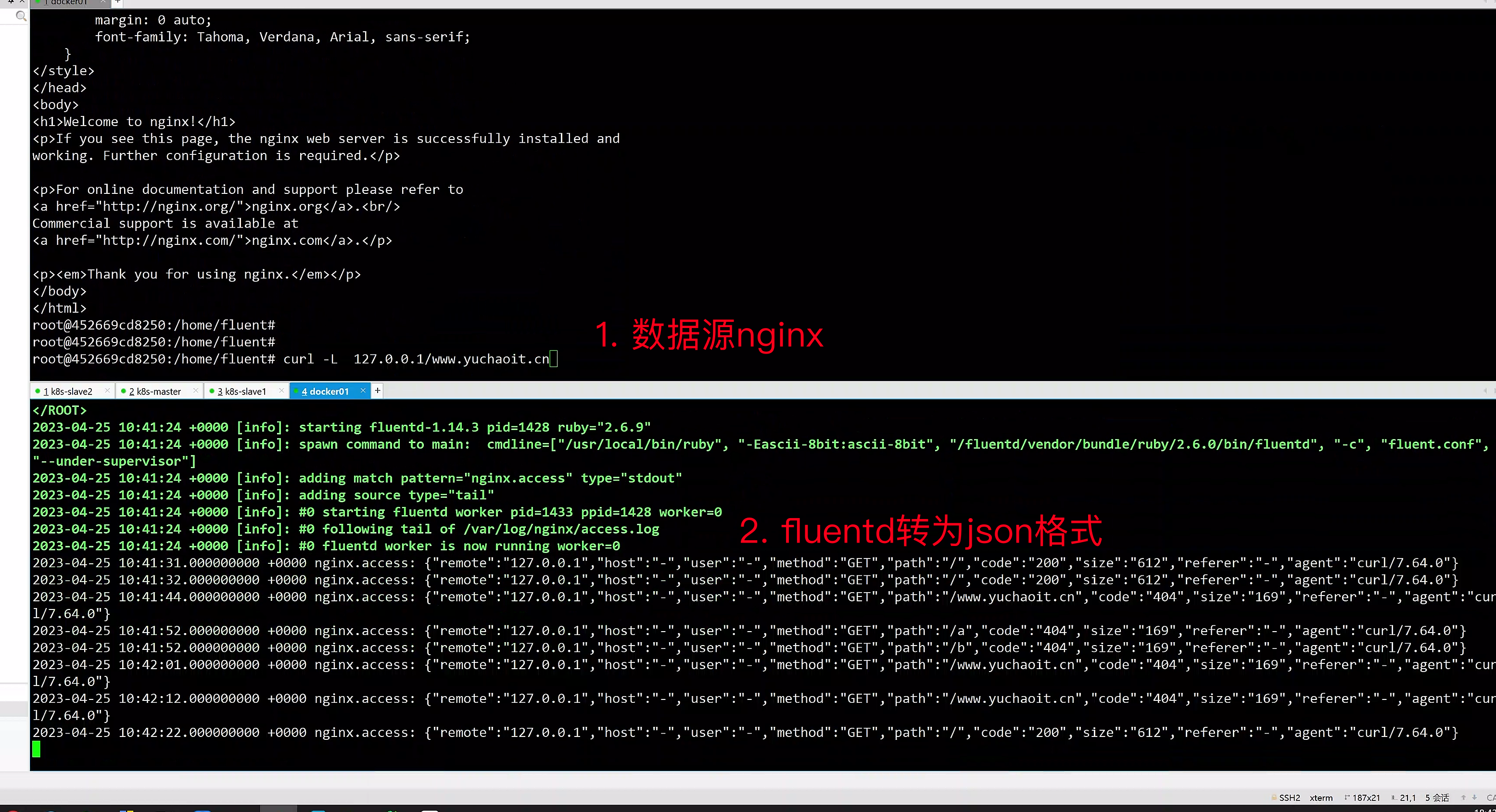
root@452669cd8250:/home/fluent# fluentd -c fluent.conf
2023-04-25 09:54:58 +0000 [info]: parsing config file is succeeded path="fluent.conf"
2023-04-25 09:54:58 +0000 [info]: gem 'fluent-plugin-concat' version '2.5.0'
2023-04-25 10:41:31.000000000 +0000 nginx.access: {"remote":"127.0.0.1","host":"-","user":"-","method":"GET","path":"/","code":"200","size":"612","referer":"-","agent":"curl/7.64.0"}
2023-04-25 10:41:32.000000000 +0000 nginx.access: {"remote":"127.0.0.1","host":"-","user":"-","method":"GET","path":"/","code":"200","size":"612","referer":"-","agent":"curl/7.64.0"}
2023-04-25 10:41:44.000000000 +0000 nginx.access: {"remote":"127.0.0.1","host":"-","user":"-","method":"GET","path":"/www.yuchaoit.cn","code":"404","size":"169","referer":"-","agent":"curl/7.64.0"}
2023-04-25 10:41:52.000000000 +0000 nginx.access: {"remote":"127.0.0.1","host":"-","user":"-","method":"GET","path":"/a","code":"404","size":"169","referer":"-","agent":"curl/7.64.0"}
2023-04-25 10:41:52.000000000 +0000 nginx.access: {"remote":"127.0.0.1","host":"-","user":"-","method":"GET","path":"/b","code":"404","size":"169","referer":"-","agent":"curl/7.64.0"}
2023-04-25 10:42:01.000000000 +0000 nginx.access: {"remote":"127.0.0.1","host":"-","user":"-","method":"GET","path":"/www.yuchaoit.cn","code":"404","size":"169","referer":"-","agent":"curl/7.64.0"}
2023-04-25 10:42:12.000000000 +0000 nginx.access: {"remote":"127.0.0.1","host":"-","user":"-","method":"GET","path":"/www.yuchaoit.cn","code":"404","size":"169","referer":"-","agent":"curl/7.64.0"}
2023-04-25 10:42:22.000000000 +0000 nginx.access: {"remote":"127.0.0.1","host":"-","user":"-","method":"GET","path":"/","code":"200","size":"612","referer":"-","agent":"curl/7.64.0"}
{
"remote":"127.0.0.1",
"host":"-",
"user":"-",
"method":"GET",
"path":"/www.yuchaoit.cn",
"code":"404",
"size":"169",
"referer":"-",
"agent":"curl/7.64.0"
}
更多高级fluent.conf的玩法,得继续看官网,以及了解一些ruby的编码语法。
Fluent.conf语法
fluentd数据流模型
https://docs.fluentd.org/v/0.12/quickstart/life-of-a-fluentd-event
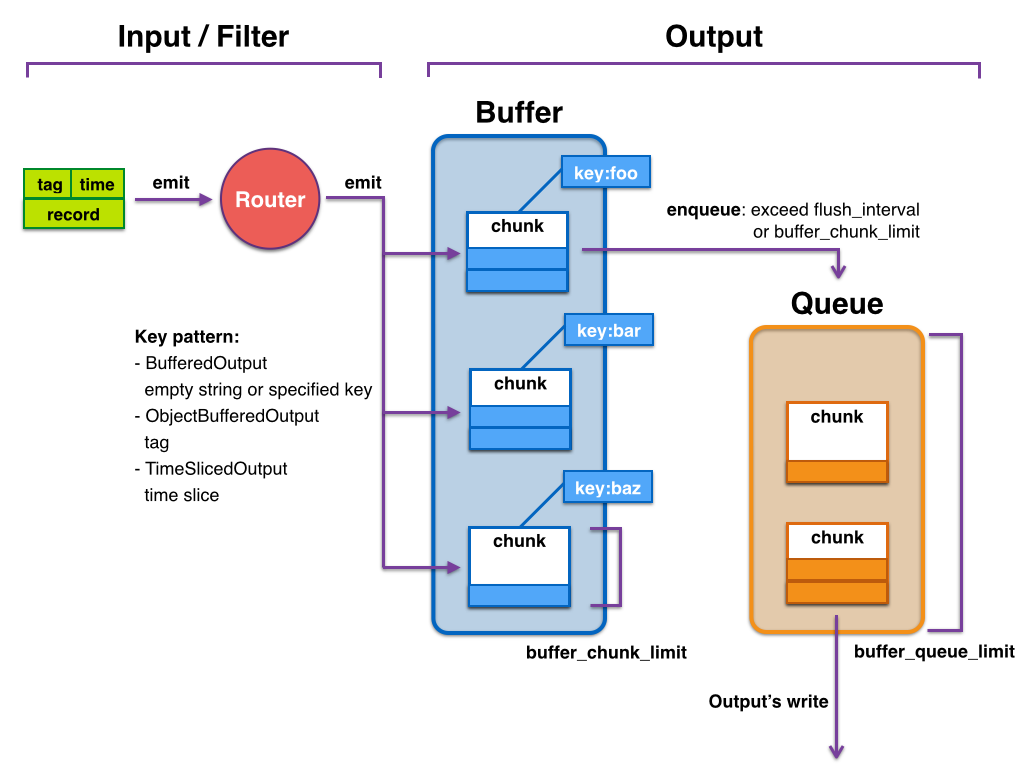
Input -> filter 1 -> ... -> filter N -> Buffer -> Output
这是 Fluentd 的数据流模型,其中 Input 是数据源,Output 是数据的最终目的地,filter 1 到 filter N 则是对数据进行处理和转换的一系列过滤器,Buffer 是用于暂存数据的缓冲区。
具体地说,数据首先从 Input 插件中读取,然后经过 filter 1 到 filter N 的处理,这些过滤器可以进行各种操作,例如解析、转换、过滤、聚合等。处理后的数据被发送到 Buffer 中,这个缓冲区可以是内存、磁盘或者网络等存储介质。Buffer 用于暂存数据,以便 Fluentd 可以更有效地处理数据。当 Buffer 中的数据达到一定数量或者时间间隔时,Fluentd 将数据批量发送到 Output 插件,最终输出到指定的目的地。
这个数据流模型的优点是灵活性强,可以通过添加、删除或者修改过滤器,来满足各种不同的数据处理需求。同时,使用缓冲区可以提高数据处理的效率和容错性,因为它可以处理临时的数据流量峰值,以及网络或者系统故障等异常情况。
总之,Fluentd 的数据流模型由 Input、filter、Buffer 和 Output 四个部分组成,通过这个模型,可以对不同来源的数据进行处理和转换,并将处理后的数据发送到指定的目的地。
启动fluentd
# 执行fluentd -c fluent.conf
root@231134dfd502:/home/fluent# ps -ef
\UID PID PPID C STIME TTY TIME CMD
root 1 0 0 03:23 pts/0 00:00:00 bash
root 1322 0 0 03:25 ? 00:00:00 nginx: master process nginx
www-data 1323 1322 0 03:25 ? 00:00:00 nginx: worker process
www-data 1324 1322 0 03:25 ? 00:00:00 nginx: worker process
www-data 1325 1322 0 03:25 ? 00:00:00 nginx: worker process
www-data 1326 1322 0 03:25 ? 00:00:00 nginx: worker process
root 1344 0 0 03:38 pts/1 00:00:00 bash
root 1351 1 15 03:38 pts/0 00:00:00 ruby /fluentd/vendor/bundle/ruby/2.6.0/bin/fluentd -c fluent.conf
root 1356 1351 14 03:38 pts/0 00:00:00 /usr/local/bin/ruby -Eascii-8bit:ascii-8bit /fluentd/vendor/bundle/ruby/2.6.0/b
root 1358 1344 0 03:38 pts/1 00:00:00 ps -ef
root@231134dfd502:/home/fluent#
fluent.conf指令语法
fluent.conf 是 Fluentd 的配置文件,其中包含了 Fluentd 的指令语法。下面是 Fluentd 指令语法的一些概述:
- 指令以
{}包围,多个指令之间用换行符分隔; - 每个指令由指令名称和参数组成,用空格隔开;
- 指令参数由键值对组成,用空格隔开,键和值之间用
=隔开; - 多个参数之间用
,隔开; - 值可以是字符串、数字、布尔值、正则表达式、数组等;
- 注释以
#开头,直到行末。
Fluentd 中常用的指令包括 source、filter、match 等,用于配置数据源、数据处理过程和数据输出。指令可以嵌套使用,形成复杂的数据流转和处理逻辑。
当在 Fluentd 配置文件中使用 source、filter、match 指令时,需要遵循特定的语法和格式。
source 指令
source 指令用于指定 Fluentd 的数据源,可以从不同的来源获取数据。下面是 source 指令的语法:
confCopy code
<source>
@type source_type
key1 value1
key2 value2
...
</source>
其中,source_type 是必选参数,表示数据源的类型,例如 tail、tcp、udp、http 等。其他的键值对是可选参数,用于指定数据源的配置选项,如端口号、日志文件路径等。每个数据源只能有一个 source 指令。
filter 指令
filter 指令用于对从数据源获取到的数据进行处理、转换或过滤。下面是 filter 指令的语法:
confCopy code
<filter tag>
@type filter_type
key1 value1
key2 value2
...
</filter>
其中,tag 是必选参数,表示数据的标签,用于区分不同的数据流。filter_type 是必选参数,表示数据处理的类型,例如 grep、record_transformer、parser 等。其他的键值对是可选参数,用于指定数据处理的配置选项,如正则表达式、字段映射等。
match 指令
match 指令用于将处理后的数据发送到指定的输出插件。下面是 match 指令的语法:
confCopy code
<match tag>
@type output_type
key1 value1
key2 value2
...
</match>
其中,tag 是必选参数,表示数据的标签,用于匹配 filter 中处理后的数据流。output_type 是必选参数,表示输出插件的类型,例如 stdout、file、elasticsearch 等。其他的键值对是可选参数,用于指定输出插件的配置选项,如输出路径、索引名称等。
需要注意的是,match 指令必须与 source、filter 指令匹配使用,每个数据流可以有多个 match 指令,用于将数据输出到不同的地方。
source
source ,数据源,对应Input 通过使用 source 指令,来选择和配置所需的输入插件来启用 Fluentd 输入源, source 把事件提交到 fluentd 的路由引擎中。使用type来区分不同类型的数据源。如下配置可以监听指定文件的追加输入:
<source>
@type tail
path /var/log/httpd-access.log
pos_file /var/log/td-agent/httpd-access.log.pos
tag myapp.access
format apache2
</source>
filter
Event processing pipeline(事件处理流)
filter 可以串联成 pipeline,对数据进行串行处理,最终再交给 match 输出。 如下可以对事件内容进行处理:
<source>
@type http
port 9880
</source>
<filter myapp.access>
@type record_transformer
<record>
host_param “#{Socket.gethostname}”
</record>
</filter>
filter 获取数据后,调用内置的 @type record_transformer 插件,在事件的 record 里插入了新的字段 host_param,然后再交给 match 输出。
label指令
可以在 source 里指定 @label,这个 source 所触发的事件就会被发送给指定的 label 所包含的任务,而不会被后续的其他任务获取到。
<source>
@type forward
</source>
<source>
### 这个任务指定了 label 为 @SYSTEM
### 会被发送给 <label @SYSTEM>
### 而不会被发送给下面紧跟的 filter 和 match
@type tail
@label @SYSTEM
path /var/log/httpd-access.log
pos_file /var/log/td-agent/httpd-access.log.pos
tag myapp.access
format apache2
</source>
<filter access.**>
@type record_transformer
<record>
# …
</record>
</filter>
<match **>
@type elasticsearch
# …
</match>
<label @SYSTEM>
### 将会接收到上面 @type tail 的 source event
<filter var.log.middleware.**>
@type grep
# …
</filter>
<match **>
@type s3
# …
</match>
</label>
match
Match匹配输出
查找匹配 “tags” 的事件,并处理它们。match 命令的最常见用法是将事件输出到其他系统(因此,与 match 命令对应的插件称为 “输出插件”)
<source>
@type http
port 9880
</source>
<filter myapp.access>
@type record_transformer
<record>
host_param “#{Socket.gethostname}”
</record>
</filter>
<match myapp.access>
@type file
path /var/log/fluent/access
</match>
events
在 Fluentd 中,事件(event)是指一个包含时间戳、标签和记录数据的数据单元。它是 Fluentd 内部数据处理和传输的基本单元,可以由不同的输入插件生成,经过一系列过滤处理后,再由输出插件发送到目标存储、服务等。
每个事件包含三个重要的字段:
time:事件的时间戳,表示该事件产生的时间。在 Fluentd 中,时间戳通常采用 ISO 8601 格式,并且精度可以高达纳秒级别。tag:事件的标签,用于标识事件的来源和类型。在 Fluentd 配置文件中,可以通过source、filter、match等指令来指定事件的标签。record:事件的记录数据,通常是一个 JSON 对象。它可以包含任何与该事件相关的信息,例如日志消息、错误码、HTTP 请求等。
在 Fluentd 中,事件会在整个系统内进行流转和转换。通常的数据流转过程如下:
- 输入插件生成事件,并将其推送到 Fluentd 的消息队列中。
- Fluentd 消费队列中的事件,根据标签和类型进行分类,并将其传递给相应的过滤器进行处理。
- 过滤器处理事件,并将处理后的事件重新发送到消息队列中。
- 输出插件从消息队列中获取事件,并将其发送到目标存储、服务等。
事件的格式和结构可以根据业务需求进行定制和调整。通过灵活的配置和过滤,可以方便地将事件传递到不同的存储和服务中,从而实现日志收集、数据传输和数据处理等功能。
例如一个原始日志
192.168.0.1 - - [28/Feb/2013:12:00:00 +0900] "GET /www.yuchaoit.cn HTTP/1.1" 200 777
经过fluentd 引擎处理完后的样子可能是:
2020-07-16 08:40:35 +0000 apache.access: {"user":"-","method":"GET","code":200,"size":777,"host":"192.168.0.1","path":"/www.yuchaoit.cn"}