k8s部署EFK
部署前置问题,基于生产实践而来。
并且线上的ES、中间件、缓存,生产下也不一定用k8s部署,会选择裸机部署。
我们通过如下案例,学习k8s系列知识点即可。
只要你们有ES大规模的需求,会有ES专门的工程师部署,因为ES它本身就极其复杂。
k8s管理并不合适。
es生产环境是部署es集群,通常会使用statefulset进行部署
使用 StatefulSet 部署 Elasticsearch 集群是一种常见的方式,它可以确保每个 Elasticsearch 实例都有唯一的标识符和稳定的网络标识符,使得 Elasticsearch 集群在扩容和缩容时更加可靠和可控。
- 稳定的网络标识符:Elasticsearch集群中的每个节点都需要有一个稳定的网络标识符(通常是节点名称),以便其他节点可以通过该标识符来识别和连接它。在StatefulSet中,每个Pod都会分配一个唯一的网络标识符,并且这些标识符在Pod重新启动时保持不变,这有助于确保集群稳定性。
- 有序的启动和关闭:Elasticsearch集群中的节点需要以特定的顺序启动和关闭,以便保持集群的稳定性。在StatefulSet中,Pod会按照其名称的数字顺序进行启动和关闭,从而确保节点按照正确的顺序加入或离开集群。
- 持久化存储:Elasticsearch集群需要持久化存储来保存数据。在StatefulSet中,每个Pod都可以有自己的持久化存储卷,这有助于确保数据在节点重新启动时不会丢失
es默认使用elasticsearch用户启动进程,es的数据目录是通过宿主机的路径挂载,因此目录权限被主机的目录权限覆盖,因此可以利用initContainer容器在es进程启动之前把目录的权限修改掉,注意init container要用特权模式启动。
若希望使用helm部署,参考 https://github.com/helm/charts/tree/master/stable/elasticsearch
1.statefulSet控制器
Deployment和StatefulSet是Kubernetes中用于管理容器应用程序的两种不同的资源对象,它们具有不同的用途和适用场景。
Deployment适用于无状态应用程序,它可以管理一组Pod,这些Pod可以动态地扩展和缩小,以满足应用程序的需求。Deployment确保Pod处于所需的副本数,并支持滚动更新和回滚操作。Deployment中的Pod没有持久性标识符,因此它们可以在任何节点上重新创建和调度。
相反,StatefulSet适用于有状态应用程序,它可以管理一组具有持久性标识符的Pod,这些Pod需要按顺序启动和停止,并且需要保持其标识符和网络标识符不变。例如,数据库应用程序通常需要有状态的Pod,因为它们需要保持其数据的完整性和一致性。StatefulSet确保Pod按顺序启动和停止,并支持有序扩展和缩小操作。
因此,如果您的应用程序是无状态的,并且只需要动态地扩展和缩小Pod以满足需求,那么您应该选择Deployment。如果您的应用程序是有状态的,并且需要保持其标识符和网络标识符不变,那么您应该选择StatefulSet。
为什么用statefulSet
Statefulset 是一个 Kubernetes 对象,它部署和扩展一组 Kubernetes pod,但部署也是如此。
通常,当我们进行部署时,我们不关心 pod 是如何调度的以及它们获得什么名称,但在某些情况下,重要的是 pod 按顺序部署并且在所有重启和重新调度中具有相同的名称。
这就是 statefulset 发挥作用的地方。Statefulset 为每个 pod 分配一个粘性标识 [一个从 0 开始的数字],而不是将随机字符串附加到 pod 的名称。
statefulset 中的每个 pod 都是按顺序启动的,所以如果由于某种原因 pod-0 没有启动,pod-1、2、3 等等也不会启动。
什么时候用statefulSet
statefulset 可以有多个用例,其中最常见的一个是当我们想要复制数据库时。数据库通常不能被deployment复制。
为什么我们不能使用deployment来复制数据库?

在上图中,我们有一个传统的 mysql 部署。副本数设置为 1。
此外,我们有一个 Web 应用程序可以读取/写入我们的 MySQL 数据库,然后 MySQL 数据库将数据存储在其持久卷中。
这对于单个 pod 非常有效,但是当我们扩展数据库以满足增加的工作负载的需求时会发生什么。
我们设置副本数 = 3 并点击 kubectl apply。

现在我们有 3 个独立的 mysql pod,但是不共享数据库。
由于多种原因这行不通。
当 Web 应用程序尝试从 mysql 读取数据/向 mysql 写入数据时,它每次都会转到不同的 pod,我们最终会得到不一致的数据。
Statefulset 将如何解决这个问题?

当我们将 mysql 或任何其他应用程序部署为 statefulset 时,可以将第一个 pod(在本例中恰好是 mysql-0)视为主 pod
它将支持读取和写入请求,同时其他 pod 是statefulset 的一部分将仅服务于读取请求。
这将帮助我们为数据库设置主从架构,这意味着所有属于 statefulset 的 pod 都将同步并共享相同的数据。
因为master、slave之间要互相通信,且完成数据复制。
Deployment创建多副本的pod
deployment部署的pod,如3个副本,互相之间本身几乎是没有相互访问需求的。
3个副本作为一个整体,一致对外去提供服务。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: efk-yuchao
labels:
app: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx-deployment
template:
metadata:
labels:
app: nginx-deployment
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
创建
[root@k8s-master ~/efk-all]#kubectl create -f nginx-deploy.yml
deployment.apps/nginx-deployment created
[root@k8s-master ~/efk-all]#kubectl -n efk-yuchao get po
NAME READY STATUS RESTARTS AGE
nginx-deployment-5bbbc49956-8cgcr 1/1 Running 0 13s
nginx-deployment-5bbbc49956-lb4d8 1/1 Running 0 13s
nginx-deployment-5bbbc49956-zd2t9 1/1 Running 0 13s
使用StatefulSet创建多副本pod
apiVersion: apps/v1
kind: StatefulSet # kind类型
metadata:
name: nginx-statefulset
namespace: efk-yuchao
labels:
app: nginx-sts
spec:
replicas: 3
serviceName: "nginx" # 多了个svc标识
selector:
matchLabels:
app: nginx-sts
template:
metadata:
labels:
app: nginx-sts
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
创建,很明显pod有了序号标识,pod名字是固定的规则
[root@k8s-master ~/efk-all]#kubectl -n efk-yuchao get po
NAME READY STATUS RESTARTS AGE
nginx-deployment-5bbbc49956-8cgcr 1/1 Running 0 45s
nginx-deployment-5bbbc49956-lb4d8 1/1 Running 0 45s
nginx-deployment-5bbbc49956-zd2t9 1/1 Running 0 45s
nginx-statefulset-0 1/1 Running 0 3s
nginx-statefulset-1 1/1 Running 0 3s
nginx-statefulset-2 1/1 Running 0 2s
# <statefulSet名>-0
# <statefulSet名>-1
# <statefulSet名>-2
# <statefulSet名>-3
基于statefuleSet的pod名字,有固定规则,可以提前确定好pod名。
无头service
在 Kubernetes 中,服务 (Service) 是一种用于暴露应用程序或服务的一种抽象机制。通过定义一个服务,可以为一个或多个 Pod 分配一个固定的虚拟 IP 地址,然后通过这个 IP 地址和服务定义的端口号访问这些 Pod 提供的应用程序或服务。
通常情况下,服务的 Cluster IP 是 Kubernetes 集群内部使用的,它提供了一个虚拟 IP 地址来代表一组后端 Pod,对外部客户端隐藏了后端 Pod 的真实 IP 地址。
但是有时候我们需要访问服务所对应的每个 Pod 的 IP 地址,例如需要直接访问每个 Pod 的状态或者日志等,这个时候 Headless Service 就可以派上用场了。
Headless Service 是一种特殊类型的服务,它的 Cluster IP 设置为 None,意味着没有单独的虚拟 IP 地址与之关联。
这种类型的服务并不会代理流量,而是直接返回后端 Pod 的 IP 地址列表,从而让客户端可以直接访问每个 Pod 的 IP 地址。
因此,Headless Service 可以方便地让客户端直接与后端 Pod 通信,避免了额外的网络开销和延迟,同时也适用于服务发现等场景。
画图理解无头svc
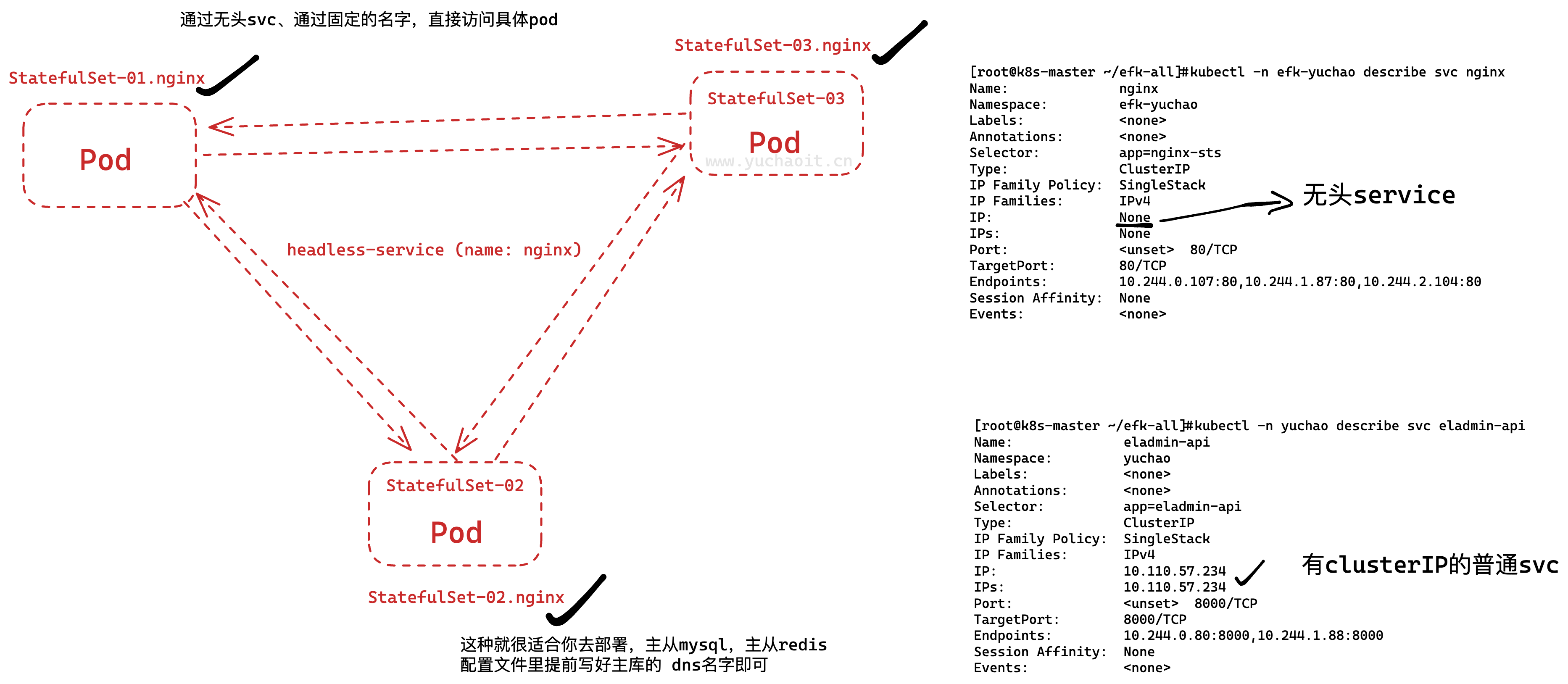
为什么叫做无头、因为它不需要一个可用的集群IP,也不用它去实现pod的负载均衡。
kind: Service
apiVersion: v1
metadata:
name: nginx
namespace: efk-yuchao
spec:
selector:
app: nginx-sts
ports:
- protocol: TCP
port: 80
targetPort: 80
clusterIP: None #
创建
[root@k8s-master ~/efk-all]#kubectl -n efk-yuchao get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 8s
headless-svc作用
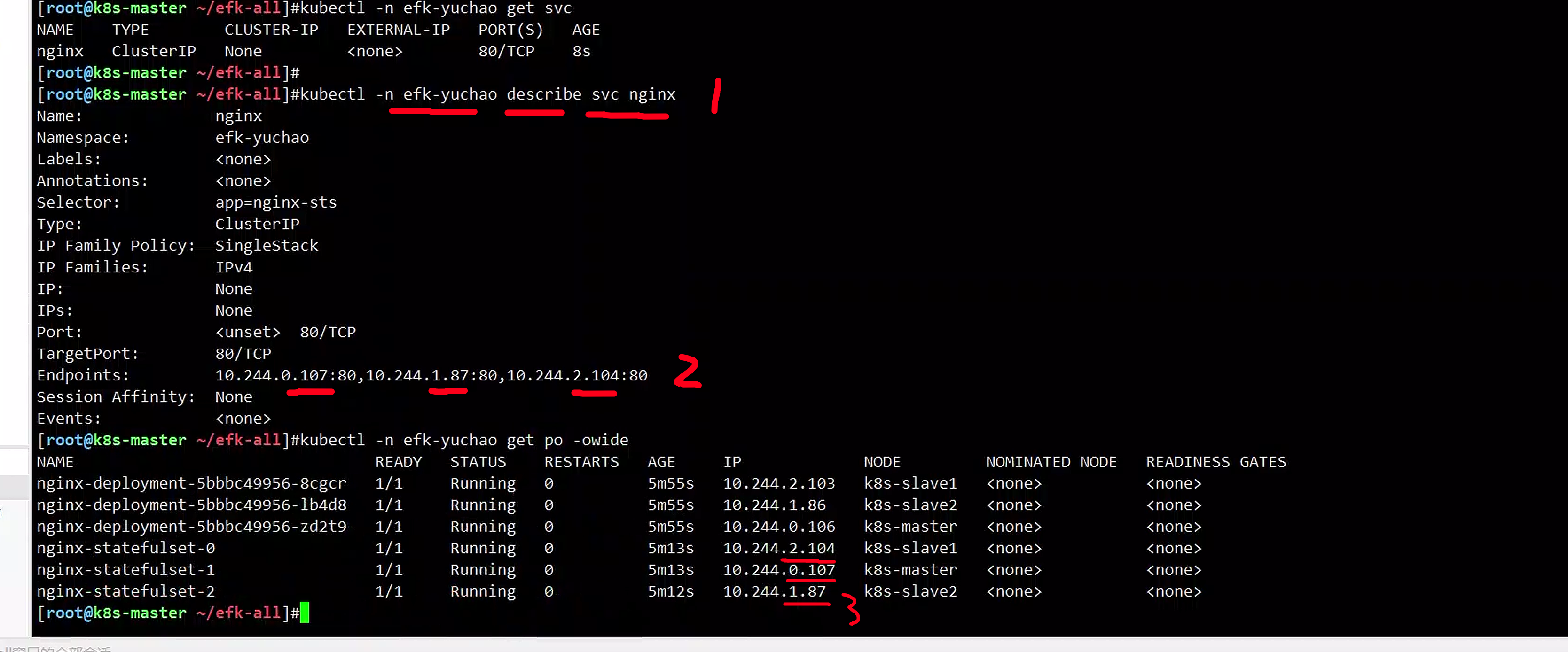
三个由statefulSet管理的pod可以直接根据<pod-name>.svc-name来实现域名解析
/ #
[root@k8s-master ~/efk-all]#kubectl -n efk-yuchao exec -it nginx-statefulset-2 -- sh
/ # curl nginx-statefulset-0.nginx -I
HTTP/1.1 200 OK
Server: nginx/1.21.5
Date: Wed, 26 Apr 2023 15:39:16 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Dec 2021 18:48:00 GMT
Connection: keep-alive
ETag: "61cb5be0-267"
Accept-Ranges: bytes
/ # curl nginx-statefulset-1.nginx -I
HTTP/1.1 200 OK
Server: nginx/1.23.4
Date: Wed, 26 Apr 2023 07:39:21 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Mar 2023 17:09:24 GMT
Connection: keep-alive
ETag: "64231f44-267"
Accept-Ranges: bytes
/ # curl nginx-statefulset-2.nginx -I
HTTP/1.1 200 OK
Server: nginx/1.21.5
Date: Wed, 26 Apr 2023 15:39:22 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 28 Dec 2021 18:48:00 GMT
Connection: keep-alive
ETag: "61cb5be0-267"
Accept-Ranges: bytes
部署ElasticSearch集群
因此mysql、redis、ETCD集群都需要pod集群互相访问。
statefulSet有状态服务控制器,能实现每一个pod有固定的网络名称标识、同时在创建应用之前就是固定可确认的(nginx-statefulset-序号),因此适合和headless-service结合工作。
并且statefulSet都是在初始化时,首次部署,适合中间件,数据库,缓存的启动。
因此实际使用并不多,更多的还是deployment。
只需要理解,特定的这下场景下
用statefulset+headless就可以获得固定的pod-name-序号,完成有状态应用部署。
Es-config.yaml
创建configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: es-config
namespace: logging
data:
elasticsearch.yml: |
cluster.name: "yuchao-elasticsearch"
node.name: "${POD_NAME}" # 环境变量去取
network.host: 0.0.0.0
discovery.seed_hosts: "es-svc-headless"
cluster.initial_master_nodes: "elasticsearch-0,elasticsearch-1,elasticsearch-2"
ES集群的创建,要指定初始化的集群pod地址,首先这里就无法用deployment,而用statefulset完成pod名称固定。
elasticsearch-0,elasticsearch-1,elasticsearch-2
[root@k8s-master ~/efk-all]#kubectl create ns logging
namespace/logging created
[root@k8s-master ~/efk-all]#kubectl apply -f es-config.yaml
configmap/es-config created
es-svc-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: es-svc-headless
namespace: logging
labels:
k8s-app: elasticsearch
spec:
selector:
k8s-app: elasticsearch
clusterIP: None
ports:
- name: in
port: 9300
protocol: TCP
创建
[root@k8s-master ~/efk-all]#kubectl -n logging get svc es-svc-headless -oyaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2023-04-26T08:27:48Z"
labels:
k8s-app: elasticsearch
name: es-svc-headless
namespace: logging
resourceVersion: "4994802"
uid: 5b059341-2830-46ef-99c8-0239033f30ff
spec:
clusterIP: None
clusterIPs:
- None
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: in
port: 9300
protocol: TCP
targetPort: 9300
selector:
k8s-app: elasticsearch
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
es-statefulSet.yaml
生产下的yaml都会特别长且复杂,我们只需要关注基本的
- namespace
- volume
- 初始化容器等
- 镜像
其他的不需要过多去看,根据业务调整即可。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: logging
labels:
k8s-app: elasticsearch
spec:
replicas: 3
serviceName: es-svc-headless
selector:
matchLabels:
k8s-app: elasticsearch
template:
metadata:
labels:
k8s-app: elasticsearch
spec:
initContainers:
- command:
- /sbin/sysctl
- -w
- vm.max_map_count=262144
image: alpine:3.6
imagePullPolicy: IfNotPresent
name: elasticsearch-logging-init
resources: {}
securityContext:
privileged: true
- name: fix-permissions
image: alpine:3.6
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: es-data-volume
mountPath: /usr/share/elasticsearch/data
containers:
- name: elasticsearch
image: elasticsearch:7.4.2
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name # 固定写法,获取pod名字的写法
resources:
limits:
cpu: '1'
memory: 2Gi
requests:
cpu: '1'
memory: 2Gi
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: es-config-volume
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
subPath: elasticsearch.yml
- name: es-data-volume
mountPath: /usr/share/elasticsearch/data
volumes:
- name: es-config-volume
configMap:
name: es-config
items:
- key: elasticsearch.yml
path: elasticsearch.yml
volumeClaimTemplates: # 主要就是PVC的配置
- metadata:
name: es-data-volume
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "nfs"
resources:
requests:
storage: 5Gi
ES的每一个pod副本都需要有自己的一个PVC,因此这里无法固定写死PVC,用上述写法,可以自动申请PVC
名字规则就是
es-data-volume-0
es-data-volume-1
...
通过你提前创建好的storageClassName: "nfs",自动去创建。
这段代码定义了一个 PVC 模板,它包含以下字段:
metadata: PVC 模板的元数据,其中name字段定义了 PVC 的名称,这个例子中 PVC 的名称是es-data-volume。spec: PVC 模板的规格,它定义了 PVC 的存储要求,包括访问模式、存储类型、存储容量等。具体地:accessModes: PVC 的访问模式,这个例子中设置为ReadWriteOnce,表示这个 PVC 只能被一个节点以读写模式挂载。storageClassName: PVC 的存储类型,这个例子中设置为nfs,表示这个 PVC 使用 NFS 存储类型。resources: PVC 请求的存储容量,这个例子中请求了 5GB 的存储容量。
通过这个 PVC 模板,Kubernetes 可以根据需要动态地创建一个 PVC,以满足 Elasticsearch 数据卷的存储要求。
# 创建查看
[root@k8s-master ~/efk-all]#kubectl apply -f es-statefulset.yaml
statefulset.apps/elasticsearch created
# 通过如下过程,可以清晰看出,statefulSet是顺序启动pod
[root@k8s-master ~/efk-all]#kubectl -n logging get po -w
NAME READY STATUS RESTARTS AGE
elasticsearch-0 0/1 PodInitializing 0 22s
elasticsearch-0 1/1 Running 0 76s
elasticsearch-1 0/1 Pending 0 0s
elasticsearch-1 0/1 Pending 0 0s
elasticsearch-1 0/1 Pending 0 2s
elasticsearch-1 0/1 Init:0/2 0 2s
elasticsearch-1 0/1 Init:1/2 0 20s
elasticsearch-1 0/1 PodInitializing 0 21s
elasticsearch-1 1/1 Running 0 52s
elasticsearch-2 0/1 Pending 0 0s
elasticsearch-2 0/1 Pending 0 0s
elasticsearch-2 0/1 Pending 0 2s
elasticsearch-2 0/1 Init:0/2 0 2s
elasticsearch-2 0/1 Init:1/2 0 20s
elasticsearch-2 0/1 PodInitializing 0 21s
elasticsearch-2 1/1 Running 0 72s
# 检查对应的PVC
[root@k8s-master ~/efk-all]#kubectl -n logging get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
es-data-volume-elasticsearch-0 Bound pvc-b6f95308-ba8a-46eb-a7dd-6a52482976eb 5Gi RWO nfs 15m
es-data-volume-elasticsearch-1 Bound pvc-7eb411a2-cf2e-4cf7-bfaa-d7fad53c730d 5Gi RWO nfs 14m
es-data-volume-elasticsearch-2 Bound pvc-37fd8346-c6b2-4e9e-896f-29cd4b263e83 5Gi RWO nfs 13m
# 自动创建的PV
[root@k8s-master ~/efk-all]#kubectl get pv |grep es-data
pvc-37fd8346-c6b2-4e9e-896f-29cd4b263e83 5Gi RWO Delete Bound logging/es-data-volume-elasticsearch-2 nfs 14m
pvc-7eb411a2-cf2e-4cf7-bfaa-d7fad53c730d 5Gi RWO Delete Bound logging/es-data-volume-elasticsearch-1 nfs 15m
pvc-b6f95308-ba8a-46eb-a7dd-6a52482976eb 5Gi RWO Delete Bound logging/es-data-volume-elasticsearch-0 nfs 16m
# 检查NFS服务端
[root@docker01 /data/k8s]#ll |grep es-data
drwxrwxrwx 3 1000 1000 19 Apr 26 16:43 logging-es-data-volume-elasticsearch-0-pvc-b6f95308-ba8a-46eb-a7dd-6a52482976eb
drwxrwxrwx 3 1000 1000 19 Apr 26 16:44 logging-es-data-volume-elasticsearch-1-pvc-7eb411a2-cf2e-4cf7-bfaa-d7fad53c730d
drwxrwxrwx 3 1000 1000 19 Apr 26 16:46 logging-es-data-volume-elasticsearch-2-pvc-37fd8346-c6b2-4e9e-896f-29cd4b263e83
# 至此ES启动结束
检验es是否可访问
[root@k8s-master ~/efk-all]#kubectl -n logging get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
elasticsearch-0 1/1 Running 0 22m 10.244.0.108 k8s-master <none> <none>
elasticsearch-1 1/1 Running 0 21m 10.244.2.105 k8s-slave1 <none> <none>
elasticsearch-2 1/1 Running 0 20m 10.244.1.89 k8s-slave2 <none> <none>
[root@k8s-master ~/efk-all]#curl 10.244.0.108:9200
{
"name" : "elasticsearch-0",
"cluster_name" : "yuchao-elasticsearch",
"cluster_uuid" : "AfbL6JpxT7S7Dx3I7FJKXQ",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
es-svc.yaml
最后,你要访问这个ES,还得创建一个普通SVC,外部可访问
apiVersion: v1
kind: Service
metadata:
name: es-svc
namespace: logging
labels:
k8s-app: elasticsearch
spec:
selector:
k8s-app: elasticsearch
ports:
- name: out
port: 9200
protocol: TCP
创建测试
[root@k8s-master ~/efk-all]#kubectl create -f es-svc.yaml
service/es-svc created
[root@k8s-master ~/efk-all]#kubectl -n logging get svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
es-svc ClusterIP 10.104.229.252 <none> 9200/TCP 4s k8s-app=elasticsearch
es-svc-headless ClusterIP None <none> 9300/TCP 38m k8s-app=elasticsearch
[root@k8s-master ~/efk-all]#
# 直接访问service
[root@k8s-master ~/efk-all]#curl 10.104.229.252:9200
{
"name" : "elasticsearch-1",
"cluster_name" : "yuchao-elasticsearch",
"cluster_uuid" : "AfbL6JpxT7S7Dx3I7FJKXQ",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
# 于超老师提醒,看下咱们创了了什么
[root@k8s-master ~/efk-all]#kubectl -n logging get all
NAME READY STATUS RESTARTS AGE
pod/elasticsearch-0 1/1 Running 0 24m
pod/elasticsearch-1 1/1 Running 0 23m
pod/elasticsearch-2 1/1 Running 0 22m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/es-svc ClusterIP 10.104.229.252 <none> 9200/TCP 64s
service/es-svc-headless ClusterIP None <none> 9300/TCP 39m
NAME READY AGE
statefulset.apps/elasticsearch 3/3 24m
2.部署Kibana
三个思考点
- kibana需要暴露web页面给前端使用,因此使用ingress配置域名来实现对kibana的访问
- kibana为无状态应用,直接使用Deployment来启动
- kibana需要访问es,直接利用k8s服务发现访问此地址即可,http://es-svc:9200、这里就是于超老师上面最后一步创建的svc。
解释
- 对于需要将Kibana暴露给外部访问的需求,可以使用Kubernetes中的Ingress对象来实现。Ingress是Kubernetes中用于管理外部访问的对象,它定义了从外部进入集群的规则,包括路由规则、SSL证书、认证等。你可以通过创建一个Ingress资源对象,将外部请求转发到Kibana服务的ClusterIP或NodePort端口上,从而实现对Kibana的访问。在Ingress对象中,你需要指定Kibana的域名或者IP地址以及相应的路由规则。
- Kibana是一个无状态的应用,因此可以使用Kubernetes的Deployment对象来启动它。Deployment对象是Kubernetes中用于管理应用副本的对象,它可以自动创建和管理应用的副本数量,并且在节点故障或者副本失败时自动恢复。你需要创建一个Kibana的Deployment资源对象,指定Kibana的容器镜像、副本数量等配置信息,然后Kubernetes会自动创建相应数量的Pod来运行Kibana。
- Kibana需要访问Elasticsearch(ES),可以直接通过Kubernetes中的Service对象来实现。Service是Kubernetes中用于管理应用访问的对象,它可以为应用创建一个虚拟的IP地址和端口号,供其他应用访问。在Kubernetes中,你需要创建一个ES的Service对象,指定ES的IP地址和端口号,然后在Kibana的配置文件中指定ES的访问地址为此Service的地址。这样,Kibana就可以通过Kubernetes的服务发现机制访问ES了。
kibana.yaml
课程上提供的yaml,以官网教程,实际验证过而来,都是为了理解整体,EFK在k8s下的运维,部署流程。
学会操作后,可以去维护企业对应的生产环境下的EFK类似的架构,所以不用生搬硬套,灵活学习。
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
selector:
matchLabels:
app: "kibana"
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: kibana:7.4.2
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_HOSTS
value: http://es-svc:9200 # 注意点
- name: SERVER_NAME
value: kibana-logging
- name: SERVER_REWRITEBASEPATH
value: "false"
ports:
- containerPort: 5601
volumeMounts:
- name: config
mountPath: /usr/share/kibana/config/
volumes:
- name: config
configMap:
name: kibana-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kibana-config
namespace: logging
data:
kibana.yml: |-
elasticsearch.requestTimeout: 90000
server.host: "0"
xpack.monitoring.ui.container.elasticsearch.enabled: true
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
ports:
- port: 5601
protocol: TCP
targetPort: 5601
type: ClusterIP
selector:
app: kibana
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kibana
namespace: logging
spec:
ingressClassName: nginx
rules:
- host: kibana.yuchaoit.cn
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kibana
port:
number: 5601
创建访问
[root@k8s-master ~/efk-all]#kubectl apply -f kibana-all.yaml
deployment.apps/kibana created
configmap/kibana-config created
service/kibana created
ingress.networking.k8s.io/kibana created
[root@k8s-master ~/efk-all]#
[root@k8s-master ~/efk-all]#kubectl -n logging get po
NAME READY STATUS RESTARTS AGE
elasticsearch-0 1/1 Running 0 33m
elasticsearch-1 1/1 Running 0 32m
elasticsearch-2 1/1 Running 0 31m
kibana-7df699c857-dlhjm 1/1 Running 0 2m20s
# 修改客户端主机dns
10.0.0.80 kibana.yuchaoit.cn
成功部署如图即可
在Elasticsearch中,"Index"是一种数据结构,类似于关系型数据库中的表。它是一个包含了一组文档的逻辑容器,每个文档都是一个JSON格式的对象,可以包含任意数量的字段。
具体来说,当你在Elasticsearch中创建一个Index时,它会自动创建对应的倒排索引,以便能够对文档进行高效的搜索和检索。这个过程包括将每个文档拆分成单个的词项(tokens),并将这些词项映射到文档中的位置,以便能够在搜索时精确匹配查询关键词。
另外,一个Index还可以被分为多个Shard,以支持数据的分布式存储和并行处理。每个Shard是一个独立的索引,包含了一部分文档,并可以被分配到不同的节点上进行处理。
总之,一个Index在Elasticsearch中扮演着非常重要的角色,它是数据存储和搜索的基本单位,也是实现高可用和水平扩展的关键组件。
目前还只有kibana初始化的索引数据,下一步就是去采集日志数据,写入ES,最后用kibana分析。
3.部署fluentd
- fluentd为日志采集服务,kubernetes集群的每个业务节点都有日志产生,因此需要使用daemonset的模式进行部署
- 为进一步控制资源,会为daemonset指定一个选择标签,fluentd=true来做进一步过滤,只有带有此标签的节点才会部署fluentd
docker默认的日志
docker日志格式,直接就是一个json
[root@docker01 /data/k8s]#tail -2 /docker-data/containers/21e0086c6b976d51e19364694db1cfa0583832bce61b4fe9c55a0d86126549b1/21e0086c6b976d51e19364694db1cfa0583832bce61b4fe9c55a0d86126549b1-json.log
{"log":"2023/04/25 05:53:51 [notice] 1#1: start worker process 33\n","stream":"stderr","time":"2023-04-25T05:53:51.934238809Z"}
{"log":"2023/04/25 05:53:51 [notice] 1#1: start worker process 34\n","stream":"stderr","time":"2023-04-25T05:53:51.934239703Z"}
查看containerd的日志格式
Docker的日志输出格式与Containerd的日志格式不同,因此需要注意解析日志时要使用新的格式解析器:
https://github.com/fluent/fluentd-kubernetes-daemonset#use-cri-parser-for-containerdcri-o-logs
就是fluent针对containerd日志采集转换的一个项目代码。
# k8s下pod的日志格式
[root@k8s-master ~/efk-all]#ls -l /var/log/pods/logging_elasticsearch-0_78f72b8f-5fa6-492f-846c-6c9ff6454be5/
total 0
drwxr-xr-x 2 root root 19 Apr 26 16:43 elasticsearch
drwxr-xr-x 2 root root 19 Apr 26 16:42 elasticsearch-logging-init
drwxr-xr-x 2 root root 19 Apr 26 16:42 fix-permissions
# 这就是pod下的三个容器
# 以及查看下,用containerd启动的容器,日志如何记录的
[root@k8s-master ~/efk-all]#tail -2 /var/log/pods/logging_elasticsearch-0_78f72b8f-5fa6-492f-846c-6c9ff6454be5/elasticsearch/0.log
2023-04-26T16:44:59.604293424+08:00 stdout F {"type": "server", "timestamp": "2023-04-26T08:44:59,603Z", "level": "INFO", "component": "o.e.x.m.e.l.LocalExporter", "cluster.name": "yuchao-elasticsearch", "node.name": "elasticsearch-0", "message": "waiting for elected master node [{elasticsearch-1}{iH4_jkA6RmK4yvS1VhodbA}{_Wq437XKRZ6zVzDgqWreEA}{10.244.2.105}{10.244.2.105:9300}{dilm}{ml.machine_memory=2147483648, ml.max_open_jobs=20, xpack.installed=true}] to setup local exporter [default_local] (does it have x-pack installed?)", "cluster.uuid": "AfbL6JpxT7S7Dx3I7FJKXQ", "node.id": "yVtMzDcUSJ6QVNbdKMQb9g" }
containerd的容器日志记录如上,已经和以前老版本的docker日志采集有了区别。
修改fluentd程序的配置文件
https://github.com/fluent/fluentd-kubernetes-daemonset#use-cri-parser-for-containerdcri-o-logs
按官网教程,得出如下结论
fluentd默认是以docker的json格式去处理日志,你需要更改为containerd格式的,因此我们可以用configmap去替换fluentd默认的配置文件。
# fluentd以ruby插件形式完成各种功能,可以用gem list去查看插件列表
[root@k8s-master ~/efk-all]#cat tail_container_parse.conf
# configuration example
<parse>
@type cri
</parse>
# 创建configmap,后面挂载给fluentd使用,适配containerd的日志格式
$ kubectl -n logging create configmap tail-container-parse --from-file=tail_container_parse.conf
创建RBAC
fluentd需要访问k8s集群资源API,那肯定得认证、授权
又是serviceAccount > RBAC流程
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
创建
[root@k8s-master ~/efk-all]#kubectl create -f fluentd-rbac.yaml
serviceaccount/fluentd-es created
clusterrole.rbac.authorization.k8s.io/fluentd-es created
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created
创建fluentd进程
咱们用的是节点级的日志采集,因为就得确保每一台机器,都必须部署一个agent,并且只有一个副本。
这就是daemonset控制器的作用。
daemonset定义文件,注意点:
- Pod模板:DaemonSet会在每个Node上创建一个Pod,因此需要定义Pod的模板。在该模板中,需要包括挂载
/var/log/pods目录和fluentd的configmap中的配置文件的声明。 - Node选择器:DaemonSet需要指定Node选择器来确定在哪些Node上运行Pod。可以在Node选择器中添加fluentd=true的标签,以便只在标记为“fluentd=true”的Node上部署fluentd。
- 更新策略:由于DaemonSet会在每个Node上运行Pod,因此更新策略需要谨慎处理。建议使用“RollingUpdate”策略来逐个更新每个Node上的Pod。
fluentd-daemonset.yaml
https://github.com/fluent/fluentd-kubernetes-daemonset#use-cri-parser-for-containerdcri-o-logs
也是通过官网教程查询而来、了解即可。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
k8s-app: fluentd-logging
version: v1
spec:
selector:
matchLabels:
k8s-app: fluentd-logging
version: v1
template:
metadata:
labels:
k8s-app: fluentd-logging
version: v1
spec:
nodeSelector:
fluentd: "true" # 选择哪些机器需要采集日志,否则默认采集所有节点了
serviceAccount: fluentd-es
serviceAccountName: fluentd-es
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1-debian-elasticsearch-amd64
env:
- name: K8S_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: FLUENT_ELASTICSEARCH_HOST
value: "es-svc" # 填入es的服务发现名
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200" # 填入es的port
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http" # 没用证书
- name: FLUENTD_SYSTEMD_CONF
value: "disable" # 是否采集systemd日志
- name: FLUENTD_PROMETHEUS_CONF
value: "disable" # 是否采集普罗米修斯
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
# When actual pod logs in /var/lib/docker/containers, the following lines should be used.
# - name: dockercontainerlogdirectory
# mountPath: /var/lib/docker/containers
# readOnly: true
# When actual pod logs in /var/log/pods, the following lines should be used.
- name: dockercontainerlogdirectory
mountPath: /var/log/pods
readOnly: true
- mountPath: "/fluentd/etc/tail_container_parse.conf"
name: config
subPath: tail-container-parse # 通过subpath讲本地配置文件,写入容器
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath: # 通过这里去拿节点上的日志目录
path: /var/log
# When actual pod logs in /var/lib/docker/containers, the following lines should be used.
# - name: dockercontainerlogdirectory
# hostPath:
# path: /var/lib/docker/containers
# When actual pod logs in /var/log/pods, the following lines should be used.
- name: dockercontainerlogdirectory
hostPath:
path: /var/log/pods # 通过这里去拿节点上的containerd的日志
- name: config
configMap:
name: tail-container-parse
items:
- key: tail_container_parse.conf
path: tail-container-parse
部署
# 给slave1打上标签,进行部署fluentd日志采集服务,master不用的话就不加了
$ kubectl label node k8s-slave1 fluentd=true
$ kubectl label node k8s-slave2 fluentd=true
[root@k8s-master ~/efk-all]#kubectl -n logging get po -owide |grep fluentd
fluentd-6ms94 1/1 Running 0 49s 10.244.1.90 k8s-slave2 <none> <none>
fluentd-bv6tc 1/1 Running 0 49s 10.244.2.106 k8s-slave1 <none> <none>
# 检查配置文件替换
[root@k8s-master ~/efk-all]#kubectl -n logging exec -it fluentd-6ms94 -- bash
root@fluentd-6ms94:/home/fluent# cat /fluentd/etc/tail_container_parse.conf
# configuration example
<parse>
@type cri
</parse>
# 检查容器内,是否拿到了node上的日志
root@fluentd-6ms94:/home/fluent# ls /var/log/pods/
demo-nginx_nginx-7dd78f9597-c8dj4_b796bc19-90fc-4f5f-91b5-fc6b40273f55
efk-yuchao_nginx-deployment-5bbbc49956-lb4d8_09a333cf-28e2-40b1-9b88-dc6759026c8c
efk-yuchao_nginx-statefulset-2_84deb7b6-9162-4bc2-8f6d-f3eda0b79174
harbor_harbor-notary-server-768db5d4d4-6wzn8_14671da2-22d9-4d7e-a5e7-581922a8bb68
harbor_harbor-redis-0_76878092-8bb7-4ea8-8799-f3cd697da1a1
kube-flannel_kube-flannel-ds-74gxd_740b105d-d5cd-4a8e-ab4a-2f0fcfd04828
kube-system_kube-proxy-lfvwt_1aec918f-385e-453b-9b46-726eba00af38
kube-system_metrics-server-85f9ddd95-878r7_1ae585d0-ee33-4639-b9c3-1dca9f2dd05e
kubernetes-dashboard_dashboard-metrics-scraper-77d78b7997-hzbpq_0b7ad0fd-c893-46b7-8cd1-198f612fec8d
kubernetes-dashboard_kubernetes-dashboard-7c745c7dc-hng6r_fd77eaa6-5991-44f1-8c4d-fc6e10e2e346
logging_elasticsearch-2_12e18de1-c280-4cf8-ad92-cc5b531ad2ee
logging_fluentd-6ms94_89102ebe-1bf4-4d2f-a737-8c800511aa45
nfs-provisioner_nfs-client-provisioner-6bf7c9796c-7m2pl_101e3707-62f1-4901-9d56-24c5350e55e0
yuchao_demo-85cdd494c-8tcfn_d942a43b-4cfa-4b64-9b06-2d1de7961c0d
yuchao_eladmin-api-79b478cf54-nznfh_8cd2f186-e5ac-44d9-86d8-f5aab437283d
yuchao_ngx-test_cab0eb88-7ec5-40f9-a423-8bafd6c2b147
yuchao_redis-7957d49f44-cxj8z_71b912f5-6787-454f-9693-9cc7551cb25a
# fluentd默认配置文件
root@fluentd-6ms94:/home/fluent# cat /fluentd/etc/fluent.conf
检查EFK是否正确
至此fluentd容器启动,且挂载了node上的pod日志,也指定了ES地址,在它默认配置文件中就是发给ES。
我们可以去kibana直接查询ES的索引数据了。
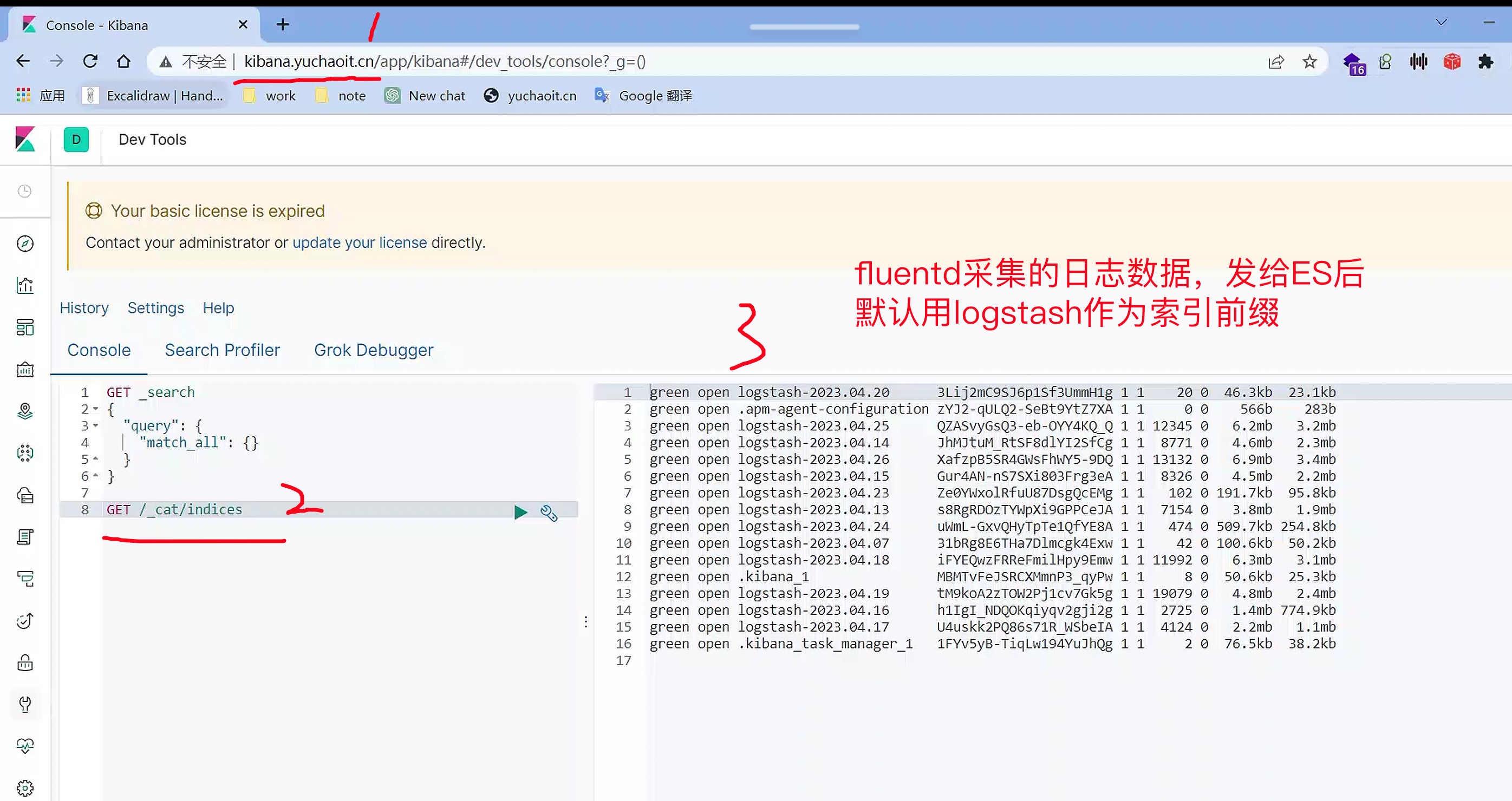
4.日志收集功能验证
管理索引
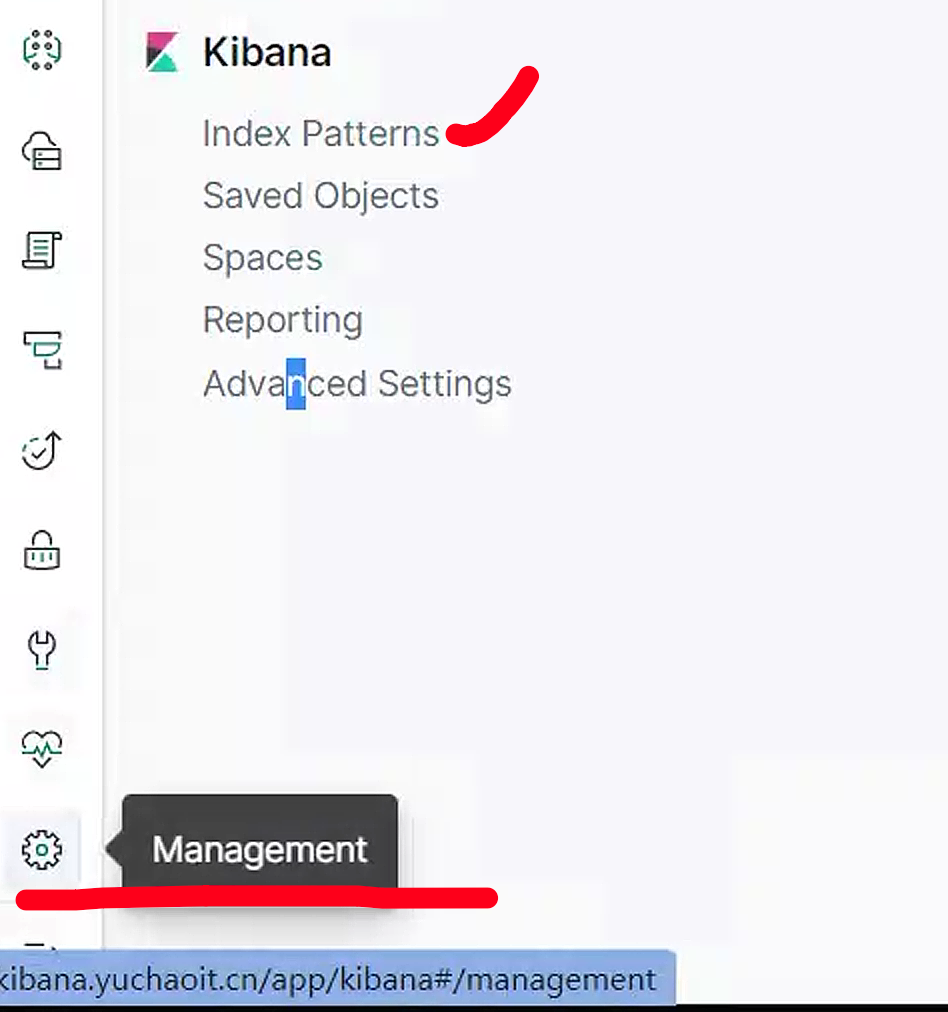
创建索引模式,匹配那些索引,我们这里匹配所有的fluentd收集的数据
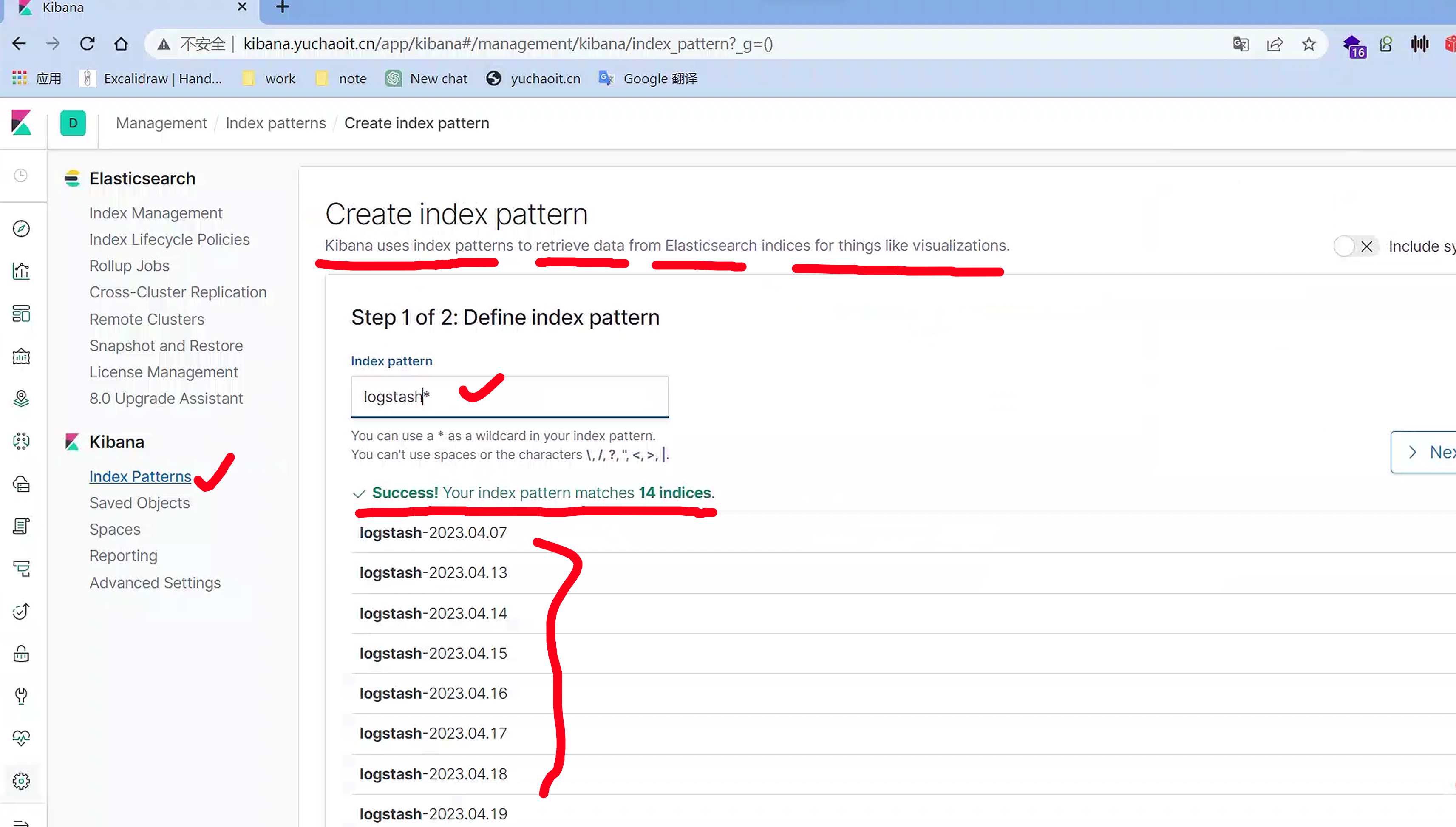
选择时间戳
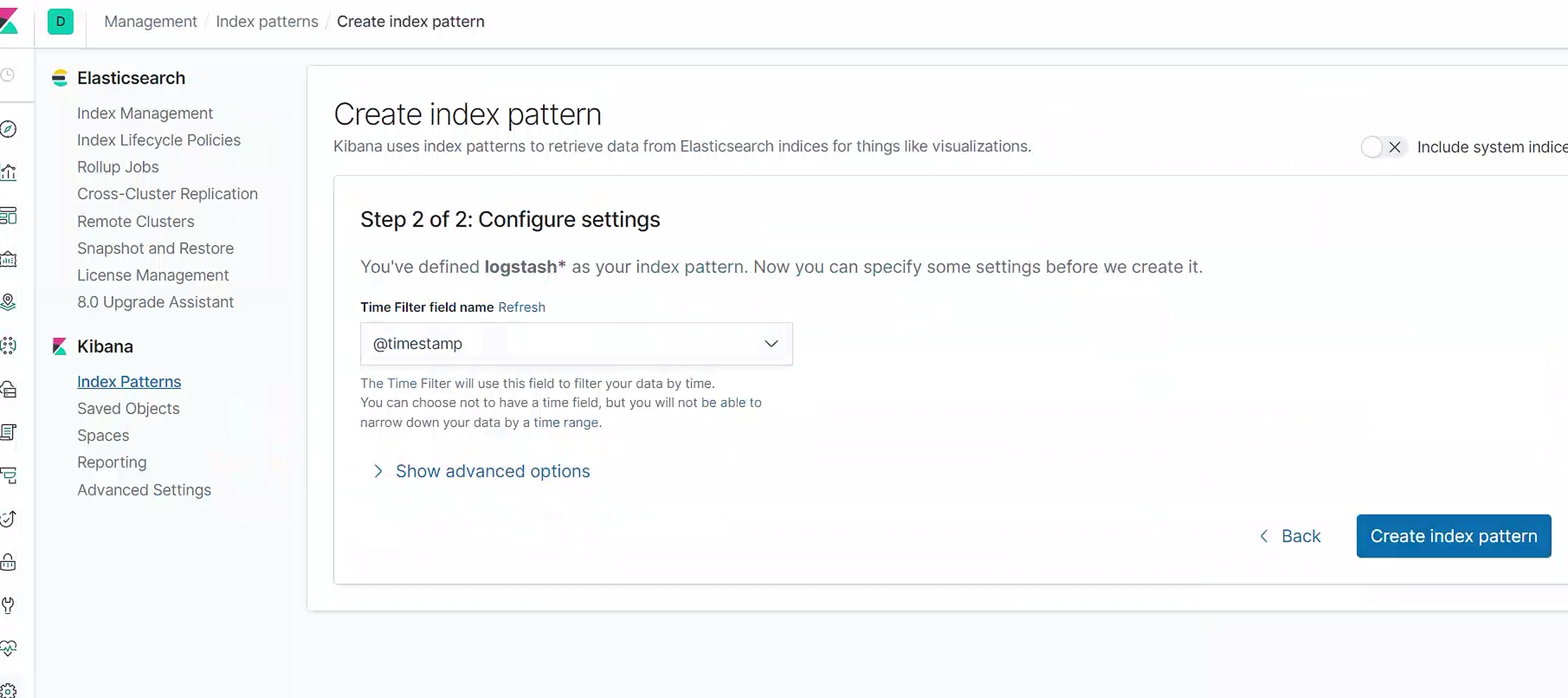
选择discover

至此就能看到containerd的日志了
过滤只看某个pod的日志
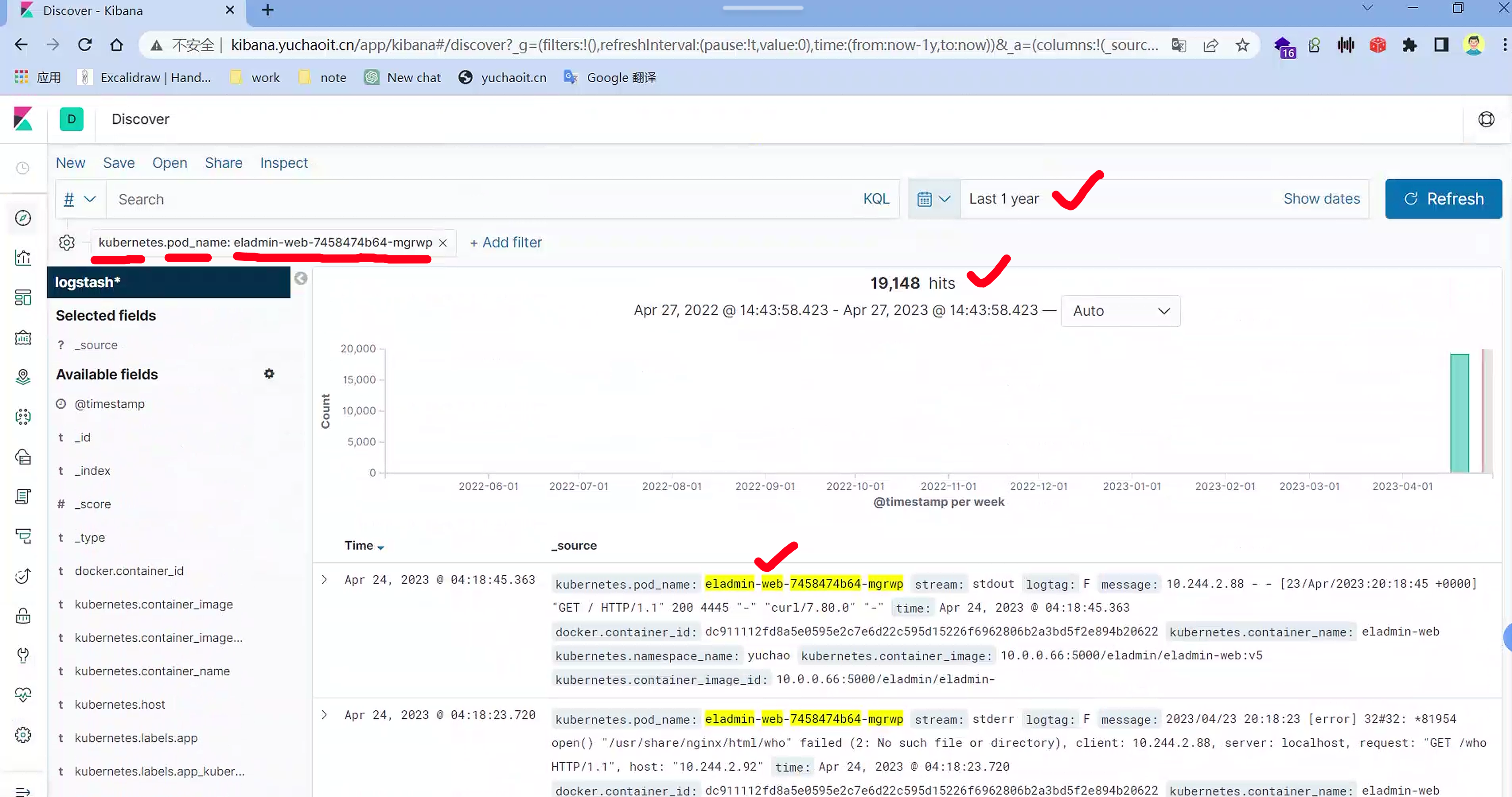
文档
思考:日志中出现了很多kubernetes的元数据信息,这些数据从哪采集而来
https://github.com/fabric8io/fluent-plugin-kubernetes_metadata_filter
到这里,我们就在 Kubernetes 集群上成功部署了 EFK ,要了解如何使用 Kibana 进行日志数据分析,可以参考 Kibana 用户指南文档:https://www.elastic.co/guide/en/kibana/current/index.html
