HPA
Kubernetes(简称k8s) HPA(Horizontal Pod Autoscaler)是Kubernetes中的一种自动扩展机制,可以自动调整Kubernetes中部署的Pod数量,以根据负载的变化动态地扩展或缩小应用程序的副本数量。
HPA根据CPU利用率或其它指标(如内存利用率)来监控Pod的负载,并根据预先定义的规则自动扩展或缩小Pod的数量。例如,当Pod的CPU利用率超过一定阈值时,HPA可以自动增加Pod的数量,以处理更多的请求流量。当负载下降时,HPA会自动减少Pod的数量,以避免资源的浪费。
使用HPA可以使Kubernetes应用程序更具弹性和自适应性,从而更好地应对负载的变化。
当系统资源过高的时候,我们可以使用如下命令来实现 Pod 的扩缩容功能
$ kubectl -n yuchao scale deployment eladmin-web --replicas=2
但是这个过程是手动操作的。
在实际项目中,我们需要做到是的是一个自动化感知并自动扩容的操作。
Kubernetes 也为提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称HPA
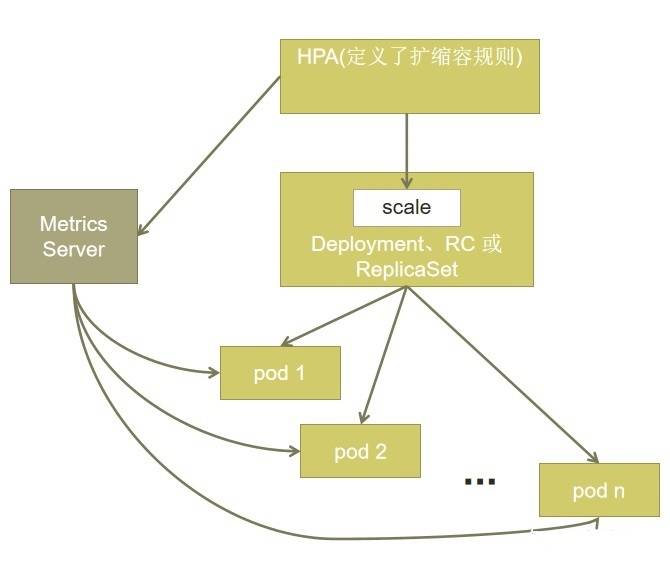
基本原理:HPA 通过监控分析控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量
Metric Server
Metrics Server是Kubernetes的一个组件,它用于收集Kubernetes集群中各个节点和容器的性能指标,例如CPU、内存、磁盘和网络等方面的数据,并将这些数据提供给Kubernetes的其他组件和用户使用。
Metrics Server的主要作用是为Kubernetes集群提供性能指标的监控和统计功能,以便管理员和开发人员可以更好地了解集群的健康状况,识别性能瓶颈和优化集群的资源使用。
Metrics Server收集的指标数据可以被许多其他Kubernetes组件和工具使用,例如Horizontal Pod Autoscaler (HPA)自动缩放Pod的功能,Kubernetes Dashboard的监控功能,以及Prometheus等第三方监控工具的数据采集。
总之,Metrics Server是Kubernetes集群中非常重要的一个组件,它为管理员和开发人员提供了丰富的性能指标数据,帮助他们更好地管理和优化集群的资源使用。
安装
官方代码仓库地址:https://github.com/kubernetes-sigs/metrics-server
Depending on your cluster setup, you may also need to change flags passed to the Metrics Server container. Most useful flags:
--kubelet-preferred-address-types- The priority of node address types used when determining an address for connecting to a particular node (default [Hostname,InternalDNS,InternalIP,ExternalDNS,ExternalIP])--kubelet-insecure-tls- Do not verify the CA of serving certificates presented by Kubelets. For testing purposes only.--requestheader-client-ca-file- Specify a root certificate bundle for verifying client certificates on incoming requests.
$ wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.1/components.yaml
需要修改部分yaml配置
# 添加- --kubelet-insecure-tls
...
133 containers:
134 - args:
135 - --cert-dir=/tmp
136 - --secure-port=4443
- --kubelet-insecure-tls # 允许忽略ssl
137 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
138 - --kubelet-use-node-status-port
139 - --metric-resolution=15s
140 image: bitnami/metrics-server:0.6.1 # 修改镜像地址为dockerhub里可用的
141 imagePullPolicy: IfNotPresent
...
安装
# 一样的,外部组件,需要操作k8s资源,肯定要走RBAC进行认证、授权
# 创建如下资源
# sa、clusterrolebinding、svc、deployment 一个典型的应用
[root@k8s-master ~/k8s-all]#kubectl apply -f components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
[root@k8s-master ~/k8s-all]#
查看metrics-server
[root@k8s-master ~/k8s-all]#kubectl -n kube-system get po |grep metri
metrics-server-85f9ddd95-878r7 1/1 Running 0 94s
此时你就可以查看nod、pod的资源使用率了
[root@k8s-master ~/k8s-all]#kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 95m 2% 2135Mi 27%
k8s-slave1 22m 1% 324Mi 8%
k8s-slave2 29m 1% 432Mi 11%
[root@k8s-master ~/k8s-all]#kubectl -n yuchao top po
NAME CPU(cores) MEMORY(bytes)
eladmin-api-79b478cf54-m5ntl 2m 895Mi
eladmin-web-7458474b64-c57nc 1m 1Mi
mysql-7c7cf8495f-5w5bk 1m 188Mi
ngx-test 0m 3Mi
redis-7957d49f44-cxj8z 1m 7Mi
yuchao-ngx 0m 1Mi
[root@k8s-master ~/k8s-all]#
HPA实践
HPA的实现有两个版本:
- autoscaling/v1,只包含了根据CPU指标的检测,稳定版本
- autoscaling/v2,支持根据cpu、memory或者用户自定义指标进行伸缩
基于CPU和内存的动态伸缩
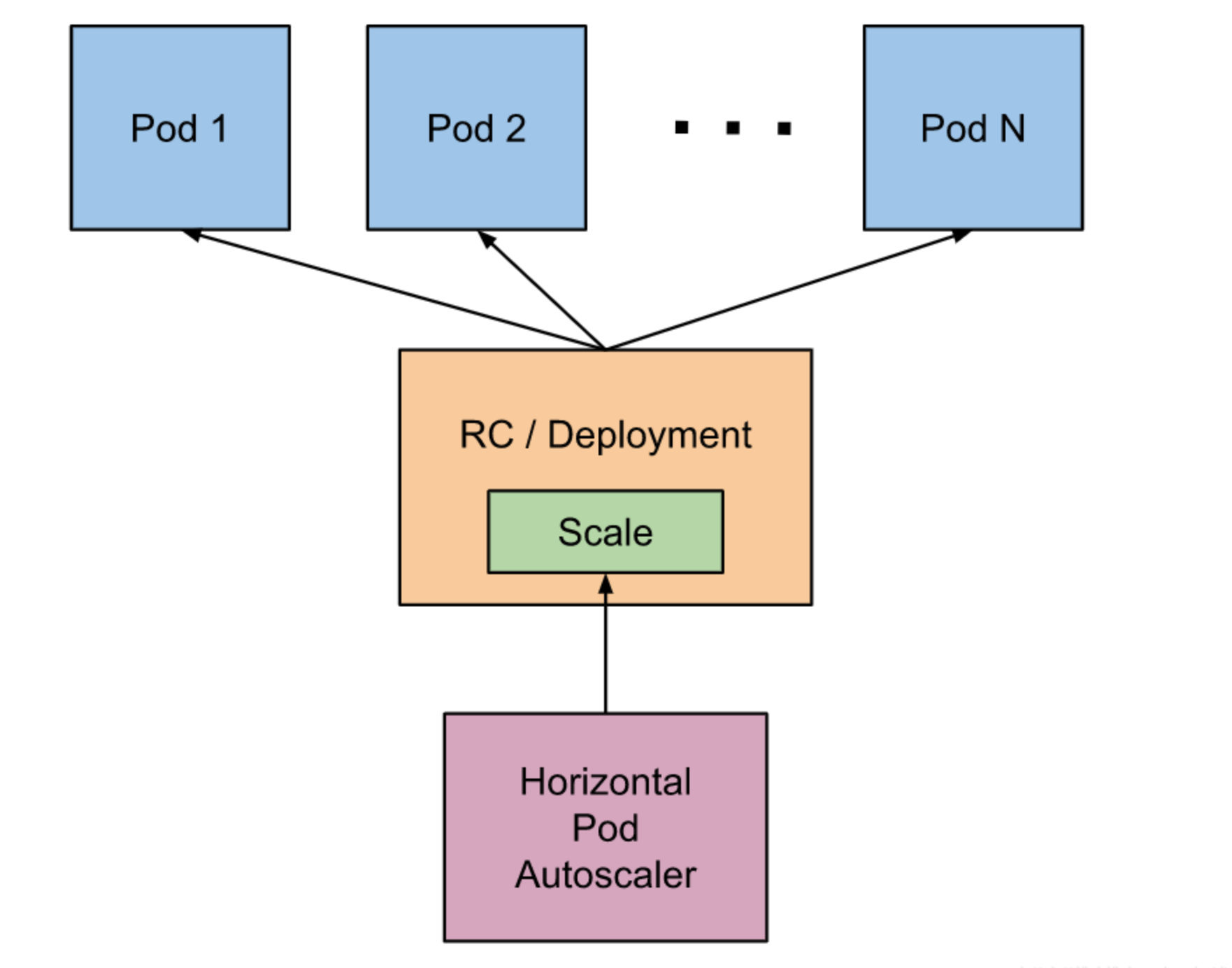
创建HPA对象
# 方式一
$ cat hpa-eladmin-web.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-eladmin-web
namespace: yuchao
spec:
maxReplicas: 3 # 最大扩到3副本
minReplicas: 1 # 最小1副本
scaleTargetRef: # 你准备调整谁
apiVersion: apps/v1
kind: Deployment
name: eladmin-web # 选择具体对象
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
# 方式二
$ kubectl -n yuchao autoscale deployment eladmin-web --cpu-percent=80 --min=1 --max=3
# 查看hpa
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-eladmin-web Deployment/eladmin-web 0%/80%, 2%/80% 1 3 1 16s
目前负载很低,待会可以进行压测,查看自动的扩缩容
注意:Deployment对象必须配置requests的参数,不然无法获取监控数据,也无法通过HPA进行动态伸缩
检查与修改deployment
修改你要自动扩缩容的应用,测试改为一个副本即可
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po |grep eladmin-web
eladmin-web-7458474b64-c57nc 1/1 Running 2 (15m ago) 11d
# 也的确配置了requests
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get po eladmin-web-7458474b64-c57nc -o yaml |grep -A 3 request
requests:
cpu: 50m
memory: 200Mi
terminationMessagePath: /dev/termination-log
压力测试
注意压力测试,是将客户端请求,负载均衡的发给多个pod,因此要访问svc。
$ yum -y install httpd-tools
[root@k8s-master ~/k8s-all]#kubectl -n yuchao get svc eladmin-web
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
eladmin-web ClusterIP 10.105.178.54 <none> 80/TCP 21d
# 为了更快看到效果,先调整副本数为1
$ kubectl -n yuchao scale deploy eladmin-web --replicas=1
# 模拟1000个用户并发访问页面10万次
$ ab -n 100000 -c 1000 http://10.105.178.54:80/
$ kubectl -n yuchao get hpa
$ kubectl -n yuchao get pods
图解动态扩缩容
- hpa定义监控eladmin-web,当cpu超过80%,扩容
- ab对deployment压测,导致cpu飙升
- hpa自动调整deployment的副本数
- 等pod负载降下去之后,hpa也会自动减少pod副本,完成缩容

缩容策略
扩容是对业务无影响的,因此可以随意扩容;
但是缩容可能会导致一些问题,因此hpa默认对缩容做了规则限制
压力降下来后,会有默认5分钟的scaledown的时间,可以通过controller-manager的如下参数设置:
--horizontal-pod-autoscaler-downscale-stabilization
The value for this option is a duration that specifies how long the autoscaler has to wait before another downscale operation can be performed after the current one has completed. The default value is 5 minutes (5m0s).
也可以通过设置每个hpa的behavior来控制scaleDown和scaleUp的行为。
本身是可以在hpa资源的yaml中定义的,了解即可。
是一个逐步的过程,当前的缩放完成后,下次缩放的时间间隔,比如从3个副本降低到1个副本,中间大概会等待2*5min = 10分钟
每隔五分钟,减少一个副本。
$ cat hpa-eladmin-web.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-eladmin-web
namespace: yuchao
spec:
maxReplicas: 3 # 最大扩到3副本
minReplicas: 1 # 最小1副本
scaleTargetRef: # 你准备调整谁
apiVersion: apps/v1
kind: Deployment
name: eladmin-web # 选择具体对象
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
behavior:
scaleDown:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 10
periodSeconds: 60
基于自定义指标的动态伸缩(先不用看)
这部分,在学完prometheus之后再操作。
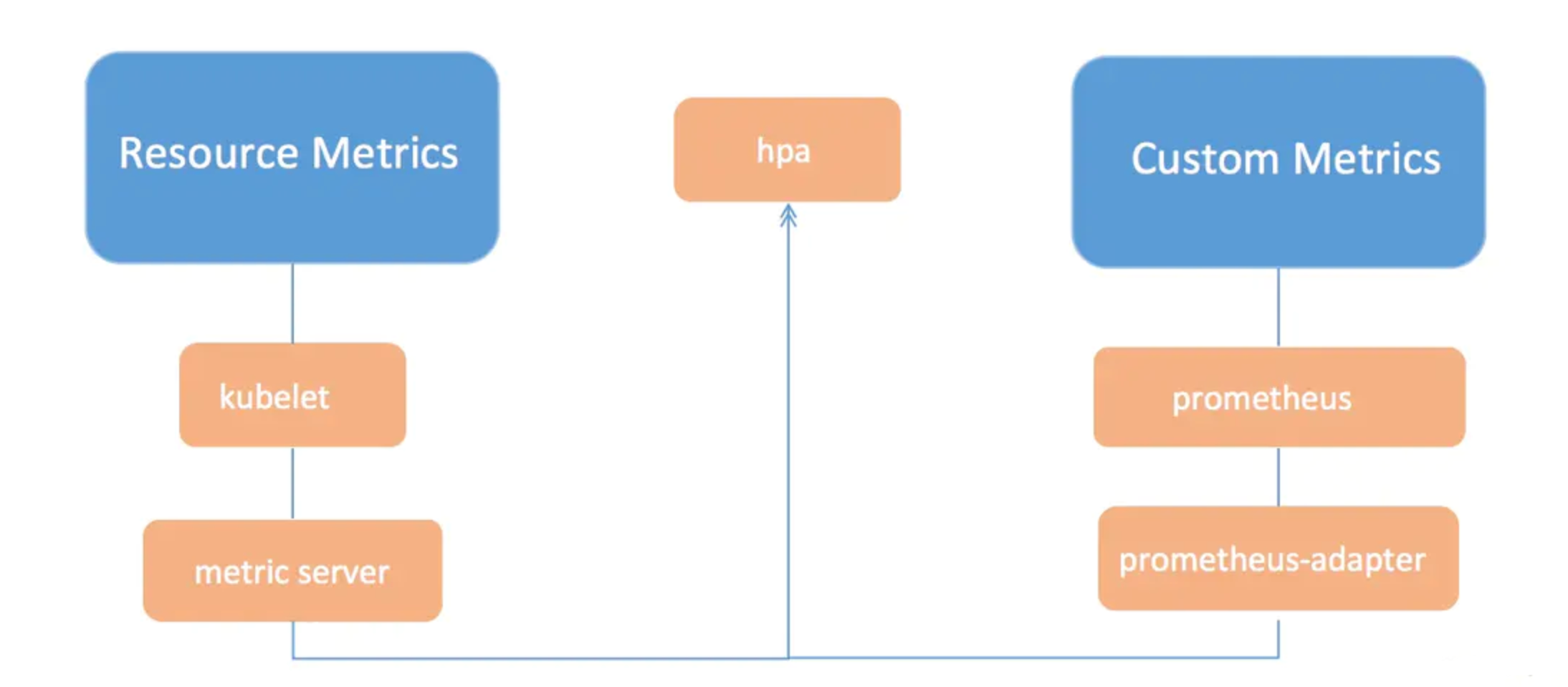
除了基于 CPU 和内存来进行自动扩缩容之外,我们还可以根据自定义的监控指标来进行。
这个我们就需要使用 Prometheus Adapter,Prometheus 用于监控应用的负载和集群本身的各种指标,Prometheus Adapter 可以帮我们使用 Prometheus 收集的指标并使用它们来制定扩展策略,这些指标都是通过 APIServer 暴露的,而且 HPA 资源对象也可以很轻易的直接使用。

HPA原理篇(进阶)
友情提醒
上面如何用HPA是很简单,可以快速实现扩缩容
但是如何理解HPA是怎么采集的pod指标,以及实现的扩缩容,就得理解k8s中的metrics指标采集概念。
如下这部分内容,基本是从代码分析角度,去理解如何通过API获取k8s资源的metrics,难度较大,初学者可以跳过
- k8s 1.8以下:使用heapster,1.11版本完全废弃
- k8s 1.8以上:使用metric-server
官方从 1.8 版本开始提出了 Metric api 的概念,而 metrics-server 就是这种概念下官方的一种实现,用于从 kubelet获取指标,替换掉之前的 heapster。
Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,比如获取某一Pod的监控数据:
[root@k8s-master ~]#kubectl get no -v=7
I0420 02:01:18.794192 64867 loader.go:372] Config loaded from file: /root/.kube/config
I0420 02:01:18.801882 64867 round_trippers.go:463] GET https://10.0.0.80:6443/api/v1/nodes?limit=500
I0420 02:01:18.801907 64867 round_trippers.go:469] Request Headers:
I0420 02:01:18.801921 64867 round_trippers.go:473] User-Agent: kubectl/v1.24.4 (linux/amd64) kubernetes/95ee5ab
I0420 02:01:18.801930 64867 round_trippers.go:473] Accept: application/json;as=Table;v=v1;g=meta.k8s.io,application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json
I0420 02:01:18.807381 64867 round_trippers.go:574] Response Status: 200 OK in 5 milliseconds
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 41d v1.24.4
k8s-slave1 Ready <none> 41d v1.24.4
k8s-slave2 Ready <none> 41d v1.24.4
[root@k8s-master ~]#
# k8s在1.8之前,都通过 https://10.0.0.80:6443/api/v1/nodes?limit=500 这种形式去获取资源数据,不太注重监控的数据查询
# 后续升级了引入了专门的监控接口
# api-server也升级了,通过如下专门的接口,采集如pod、node的资源使用率
# 只有安装metric-server才支持访问这个API
https://10.0.0.80:6443/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
查看pod的metrics
# metrics-server必须先安装,然后就可以通过上述API,获取资源数据
# 例如查看eladmin-api的使用率
[root@k8s-master ~]#kubectl -n yuchao get po eladmin-api-79b478cf54-m5ntl -v=7
I0420 02:06:21.183624 67204 loader.go:372] Config loaded from file: /root/.kube/config
I0420 02:06:21.189174 67204 round_trippers.go:463] GET https://10.0.0.80:6443/api/v1/namespaces/yuchao/pods/eladmin-api-79b478cf54-m5ntl
I0420 02:06:21.189188 67204 round_trippers.go:469] Request Headers:
I0420 02:06:21.189195 67204 round_trippers.go:473] Accept: application/json;as=Table;v=v1;g=meta.k8s.io,application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json
I0420 02:06:21.189199 67204 round_trippers.go:473] User-Agent: kubectl/v1.24.4 (linux/amd64) kubernetes/95ee5ab
I0420 02:06:21.193483 67204 round_trippers.go:574] Response Status: 200 OK in 4 milliseconds
NAME READY STATUS RESTARTS AGE
eladmin-api-79b478cf54-m5ntl 1/1 Running 12 (134m ago) 17d
[root@k8s-master ~]#
# 因此对应metrics接口规则是
https://10.0.0.80:6443/apis/metrics.k8s.io/v1beta1/namespaces/yuchao/pods/eladmin-api-79b478cf54-m5ntl
# 但是你想访问k8s-api获取数据,肯定要进行认证、鉴权,否则就是403了
[root@k8s-master ~]#curl -k https://10.0.0.80:6443/apis/metrics.k8s.io/v1beta1/namespaces/yuchao/pods/eladmin-api-79b478cf54-m5ntl
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "pods.metrics.k8s.io \"eladmin-api-79b478cf54-m5ntl\" is forbidden: User \"system:anonymous\" cannot get resource \"pods\" in API group \"metrics.k8s.io\" in the namespace \"yuchao\"",
"reason": "Forbidden",
"details": {
"name": "eladmin-api-79b478cf54-m5ntl",
"group": "metrics.k8s.io",
"kind": "pods"
},
"code": 403
# 因此可以用上一节于超老师讲课时,针对yuchao这个namespace创建的serviceAccount,创建token
# 并且你的sa得有权限访问yuchao这个ns下的资源才行
[root@k8s-master ~]#kubectl -n yuchao create token eladmin-web
拿到token..
# 使用这个token即可访问metrics API了
[root@k8s-master ~]#curl -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6IllmUUhDWV9wUXEtcEZDRlhuQzlRZTMxQ0czdkhuU9YRThNR1daVExvOVEifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjgxOTMxNzExLCJpYXQiOjE2ODE5MjgxMTEsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJ5dWNoYW8iLCJzZXJ2aWNlYWNjb3VudCI6eyJuYW1lIjoiZWxhZG1pbi13ZWIiLCJ1aWQiOiJmYWY0NzI2My1hZDhmLTRlYjAtYjVmNC0wM2Y2ZDc5MTQ3NTkifX0sIm5iZiI6MTY4MTkyODExMSwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Onl1Y2hhbzplbGFkbWluLXdlYiJ9.FhrdYOdhdF19WCn0UYBjS1H1jsdc4b8YAB_QeumGgW71oy-YADXC64gKCKcDyME9hPN5wyjTBFP9Ogk3zRl1btcuI8K6sT2OeLKUFLrBlzyLFYRNshV_345A8jeMBw1vs0iCgCjmYMpbmL8bVCNsKgIn9amvFq_Ne6HMkYYopHXIAoDqYaSbtCEsrxGtK1TSx9cxCnJM9erjqrufbdTXENR4UPe9aoUooErXi2jPOYBbLaM6_f6pcurz3AtV086pT5zlZcjXmCgHbimZV3X49vhIrNDdqP2EAA2MSySuYKIZ8ZJy-VlLoWIWCBVXI96LaoU6n9pz1kxwFs4JFK4gbw" https://10.0.0.80:6443/apis/metrics.k8s.io/v1beta1/namespaces/yuchao/pods/eladmin-api-79b478cf54-m5ntl
{
"kind": "PodMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "eladmin-api-79b478cf54-m5ntl",
"namespace": "yuchao",
"creationTimestamp": "2023-04-19T18:17:23Z",
"labels": {
"app": "eladmin-api",
"pod-template-hash": "79b478cf54"
}
},
"timestamp": "2023-04-19T18:17:15Z",
"window": "12.131s",
"containers": [
{
"name": "eladmin-api",
"usage": {
"cpu": "1938555n",
"memory": "1005736Ki"
}
}
]
}
# k8s中的Ki和Mi都是计算机存储容量的单位,Ki代表2的10次方(1024)字节,Mi代表2的20次方(1048576)字节。它们通常用于描述内存或磁盘容量。
# OK、搞定,查询出了,这个pod当前的资源使用率了
# 等于如下操作
>>> 1005736/1024
982.1640625
[root@k8s-master ~]#kubectl -n yuchao top pod eladmin-api-79b478cf54-m5ntl
NAME CPU(cores) MEMORY(bytes)
eladmin-api-79b478cf54-m5ntl 2m 982Mi
pod数据采集流程
# 查看我们安装了metrics-server哪些东西
[root@k8s-master ~]#kubectl -n kube-system get all |grep metric
pod/metrics-server-85f9ddd95-878r7 1/1 Running 0 26h
service/metrics-server ClusterIP 10.107.55.224 <none> 443/TCP 26h
deployment.apps/metrics-server 1/1 1 1 26h
replicaset.apps/metrics-server-85f9ddd95 1 1 1 26h
# 1.先创建HPA资源规则,要监控你的什么应用,触发扩缩容的资源使用率是多少,副本要调整到多少
# 2.HPA通过监控如deployment的 API,查看资源使用率
# 3.deployment的数据是通过kubelet > pod 查询出来的,然后写入到的Metrics server
HPA(Horizontal Pod Autoscaler)、Metrics API、Metrics Server 和 Kubelet 是 Kubernetes 中与自动伸缩相关的重要组件。
Metrics API 和 Metrics Server 提供了 Kubernetes 集群中的监控数据,其中 Metrics API 提供了 Kubernetes 中各个组件的基本监控数据,而 Metrics Server 则收集和存储了每个节点和 Pod 的详细监控数据。
Kubelet 是 Kubernetes 中每个节点上的代理程序,负责管理该节点上的容器和 Pod,并定期向 Metrics Server 提供节点和 Pod 的监控数据。
HPA 利用 Metrics API 和 Metrics Server 收集的监控数据,结合用户设置的自动伸缩策略(例如 CPU 使用率、内存使用率等),动态地调整 Pod 的数量,从而实现自动伸缩的功能。
因此,HPA、Metrics API、Metrics Server 和 Kubelet 之间存在密切的关系,它们共同协作,实现了 Kubernetes 集群中的自动伸缩功能。

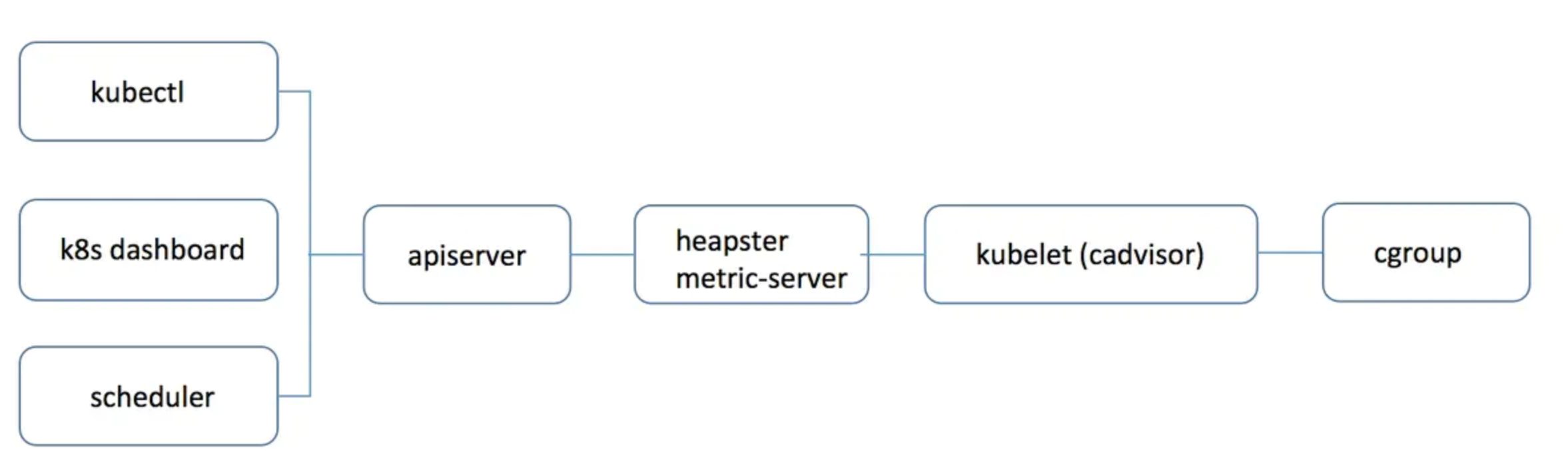
kubelet是怎么拿到的pod指标
Kubelet可以通过不同的方式获取Pod的指标,包括以下几种方式:
- cAdvisor:Kubelet内置了cAdvisor(Container Advisor)组件,它会定期监控
容器的CPU、内存、网络等指标,并将这些指标数据以RESTful API的形式暴露出来。Kubelet通过查询cAdvisor API来获取Pod和容器级别的指标数据。 - Metrics API:Kubernetes提供了Metrics API,可以暴露聚合的Pod和容器级别的指标数据,包括CPU使用率、内存使用量等。Kubelet可以通过访问Metrics API来获取Pod指标。
- 自定义指标:除了使用cAdvisor和Metrics API获取标准指标外,Kubelet还可以通过收集和发布自定义指标来扩展其指标能力。这些自定义指标可以由Kubelet插件、第三方应用程序或基础设施组件生成。
- Kubelet Summary API:Kubelet还提供了一个内部API,称为Kubelet Summary API,用于提供有关节点上所有容器和Pod的汇总指标信息。Kubelet可以通过查询此API来获取有关
Pod指标的信息。
总之,Kubelet使用cAdvisor、Metrics API、自定义指标和Kubelet Summary API等不同的方式来获取Pod的指标数据。
kubelet是通过cAdvisor模块获取的容器指标(资源使用率)
cAdvisor介绍
这部分于超老师在讲解docker容器数据采集时就说过。
Kubelet 是 Kubernetes 集群中的一个重要组件,负责管理节点上的容器化工作负载。它通过与容器运行时交互来监控和管理这些容器。
其中,cAdvisor(Container Advisor)是一个由 Google 开源的基于容器的资源使用和性能分析工具,它被广泛应用于 Kubernetes 中的资源监控和容器性能分析。
Kubelet 使用 cAdvisor 来获取容器和节点的指标,并将它们暴露给 Kubernetes API 服务器和监控系统。具体来说,Kubelet 会在节点上运行一个 cAdvisor 容器,然后使用本地 HTTP 请求的方式来查询容器的指标。
Kubelet 获取 pod 指标的过程如下:
- Kubelet 每隔一段时间会向 cAdvisor 发送一个 HTTP GET 请求,获取节点上所有容器的指标。
- 获取到容器的指标后,Kubelet 会对每个 pod 的容器进行过滤,只保留与该 pod 相关的容器指标。
- 最后,Kubelet 会将这些指标转换成 Kubernetes API 对象的形式,并将它们发送给 Kubernetes API 服务器。
需要注意的是,Kubelet 获取的指标包括 CPU、内存、磁盘、网络等多种维度的指标,这些指标对于监控和调优容器化应用非常重要。
你可以在 node 节点访问 10250 端口获取监控数据:
- Kubelet Summary metrics: https://127.0.0.1:10250/metrics,暴露 node、pod 汇总数据
- Cadvisor metrics: https://127.0.0.1:10250/metrics/cadvisor,暴露 container 维度数据
手工测试访问node指标
务必还得使用token去访问k8s集群API
# 通过这个sa账户,就有访问metrics的权限,创建token就行
[root@k8s-master ~]#kubectl -n kube-system get sa |grep metric
metrics-server 0 26h
# 基于sa创建token
$ kubectl -n kube-system create token metrics-server
# 基于token访问指标接口,看看是否有权限访问到信息
[root@k8s-master ~]#curl -k -H "Authorization: Bearer xxxxtokenxxxx" https://localhost:10250/metrics
# 但凡token错了,都提示Unauthorized ,未授权
为什么metrics-server可以接入到api-server
# 只有安装metric-server才支持访问这个API
https://10.0.0.80:6443/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
# 思考一个问题,为什么你可以基于6443的kube-apiserver ,加入一个metrics.k8s.io 就可以访问到pod的指标了?
# Metrics Server是独立的一个服务,只能服务内部实现自己的api,是如何做到通过标准的kubernetes 的API格式暴露出去的
# 答案如下
Metrics数据流
kubelet虽然提供了 metric 接口,但实际监控逻辑由内置的cAdvisor模块负责,早期的时候,cadvisor是单独的组件,从k8s 1.12开始,cadvisor 监听的端口在k8s中被删除,所有监控数据统一由Kubelet的API提供。
cadvisor获取指标时实际调用的是 runc/libcontainer库,而libcontainer是对 cgroup文件 的封装,即 cadvsior也只是个转发者,它的数据来自于cgroup文件。
cgroup文件中的值是监控数据的最终来源。
kube-aggregator
Kube-aggregator和Metrics Server都是Kubernetes集群中的组件,用于不同的目的。
Kube-aggregator是Kubernetes API聚合器,它允许用户扩展Kubernetes API以支持自定义资源和API。Kubernetes API聚合器的作用是将多个API服务聚合到一个单一的API端点中,使用户可以使用一个API端点来访问所有的Kubernetes资源。
这种聚合器提供了许多有用的功能,比如支持
扩展API和自定义资源定义(CRD)等。
Metrics Server则是Kubernetes集群中的一个组件,用于收集和存储集群资源使用情况的指标数据,如CPU、内存、网络和文件系统等。Metrics Server收集这些数据后,可以供Kubernetes Dashboard等其他工具使用,以便用户可以更好地监控和管理集群的资源使用情况。Metrics Server本身是一个轻量级的组件,它只需要部署在Kubernetes集群中,并与Kubernetes API服务器通信即可。
总的来说,Kube-aggregator和Metrics Server都是Kubernetes集群中的重要组件,它们提供了不同的功能,但都是为了帮助用户更好地管理和监控集群资源的使用情况。
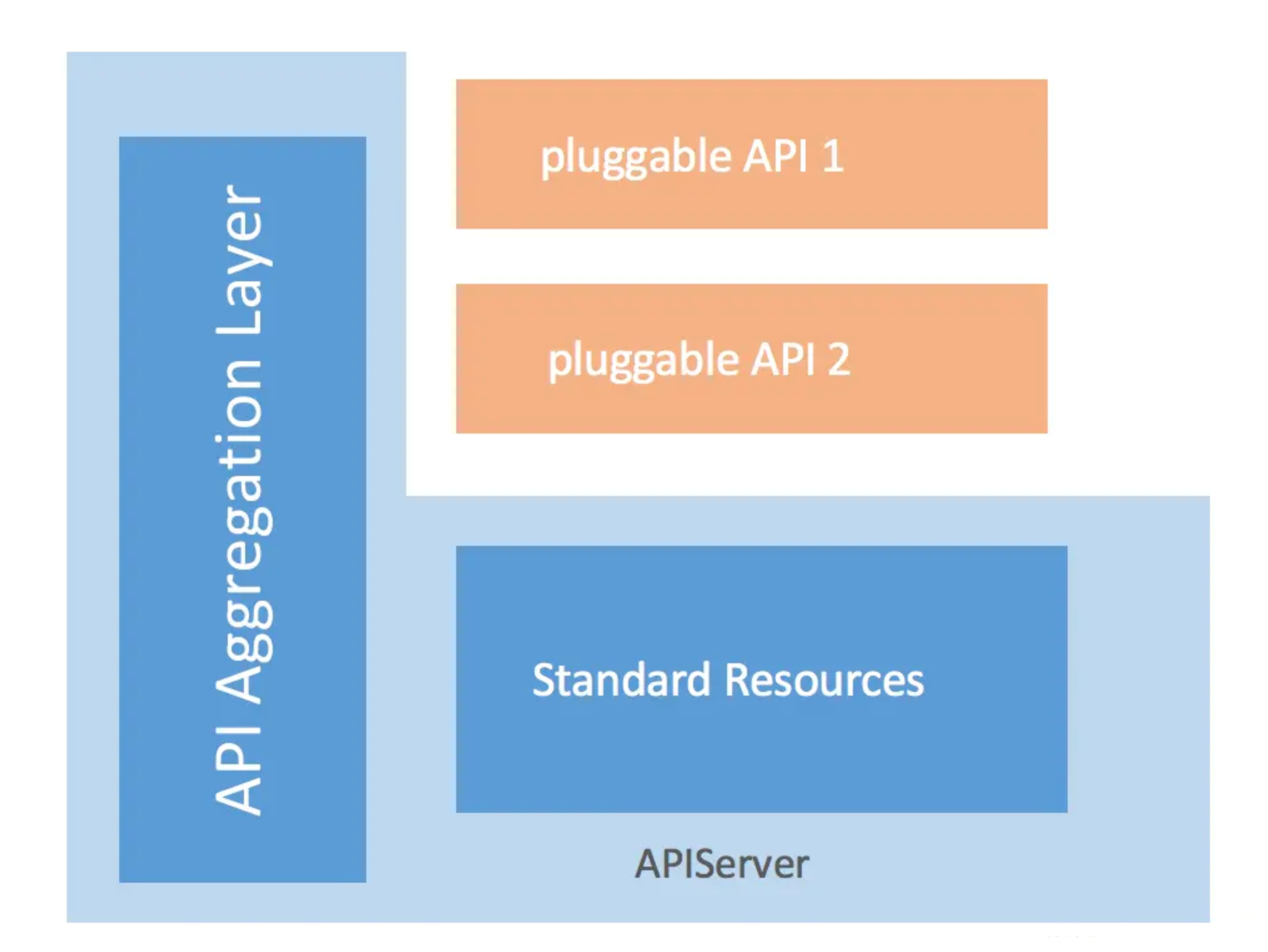
# 标准 api-server格式
https://10.0.0.80:6443/api/v1/nodes?limit=500
# 通过 API 聚合器,将开发自定义的第三方k8s插件,对接到api-server上
# 因此就可以通过如下的API形式,去访问k8s某个资源的指标了
# metrics API格式
https://10.0.0.80:6443/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
apiservice命令
"kubectl get apiservice" 是用于在 Kubernetes 集群中列出所有可用 API 服务的命令。
Kubernetes 中的 API 服务定义了 Kubernetes API 中可用的所有资源和操作。通过运行 "kubectl get apiservice" 命令,您可以查看当前在集群中运行的所有 API 服务及其状态。这些状态包括是否可用、是否正在进行版本控制等等。
此外,您还可以使用 "kubectl describe apiservice" 命令获取有关特定 API 服务的详细信息。
例如,您可以使用该命令查看 API 服务的端点、资源版本、服务类型等等。
总之,"kubectl get apiservice" 是一个非常有用的命令,可以帮助您在 Kubernetes 集群中快速了解可用的 API 服务,并在需要时获取更多有关特定服务的详细信息。
查看metric-server的实现
# 分为本地,和第三方的两种API
[root@k8s-master ~]#kubectl get apiservices.apiregistration.k8s.io
NAME SERVICE AVAILABLE AGE
v1. Local True 42d
v1.admissionregistration.k8s.io Local True 42d
v1.apiextensions.k8s.io Local True 42d
v1.apps Local True 42d
v1.authentication.k8s.io Local True 42d
v1.authorization.k8s.io Local True 42d
v1.autoscaling Local True 42d
v1.batch Local True 42d
v1.certificates.k8s.io Local True 42d
v1.coordination.k8s.io Local True 42d
v1.discovery.k8s.io Local True 42d
v1.events.k8s.io Local True 42d
v1.networking.k8s.io Local True 42d
v1.node.k8s.io Local True 42d
v1.policy Local True 42d
v1.rbac.authorization.k8s.io Local True 42d
v1.scheduling.k8s.io Local True 42d
v1.storage.k8s.io Local True 42d
v1beta1.batch Local True 42d
v1beta1.discovery.k8s.io Local True 42d
v1beta1.events.k8s.io Local True 42d
v1beta1.flowcontrol.apiserver.k8s.io Local True 42d
v1beta1.metrics.k8s.io kube-system/metrics-server True 37h
v1beta1.node.k8s.io Local True 42d
v1beta1.policy Local True 42d
v1beta1.storage.k8s.io Local True 42d
v1beta2.flowcontrol.apiserver.k8s.io Local True 42d
v2.autoscaling Local True 42d
v2beta1.autoscaling Local True 42d
v2beta2.autoscaling Local True 42d
[root@k8s-master ~]#
# 查看metric-server的API信息
[root@k8s-master ~]#kubectl get apiservices.apiregistration.k8s.io v1beta1.metrics.k8s.io -oyaml
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apiregistration.k8s.io/v1","kind":"APIService","metadata":{"annotations":{},"labels":{"k8s-app":"metrics-server"},"name":"v1beta1.metrics.k8s.io"},"spec":{"group":"metrics.k8s.io","groupPriorityMinimum":100,"insecureSkipTLSVerify":true,"service":{"name":"metrics-server","namespace":"kube-system"},"version":"v1beta1","versionPriority":100}}
creationTimestamp: "2023-04-19T15:54:54Z"
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
resourceVersion: "4007454"
uid: 89aa7d36-c46b-4e1e-b197-8c6b4d2e5a3b
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
port: 443
version: v1beta1
versionPriority: 100
status:
conditions:
- lastTransitionTime: "2023-04-20T13:06:56Z"
message: all checks passed
reason: Passed
status: "True"
type: Available
# API代理原理
# 会往apiserver里注册一个
# proxyPath := "/apis/" + apiService.Spec.Group + "/" + apiService.Spec.Version
# 当你访问api-server时
# https://10.0.0.80:6443/apis/metrics.k8s.io/v1beta1
↓↓↓↓其实是转发到这里
# => https://metrics-server:443/apis/metrics.k8s.io/v1beta1
# 查看metrics-server访问入口
[root@k8s-master ~]#kubectl -n kube-system get svc metrics-server
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
metrics-server ClusterIP 10.107.55.224 <none> 443/TCP 37h
# 测一测
[root@k8s-master ~]#kubectl -n yuchao create token eladmin-web
eyJhbGciOiJSUzI1NiIsImtpZCI6IllmUUhDWV9wUXEtcEZDRlhuQzlRZTMxQ0czdkhuUU9YRThNR1daVExvOVEifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjgyMDYwMDg2LCJpYXQiOjE2ODIwNTY0ODYsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJ5dWNoYW8iLCJzZXJ2aWNlYWNjb3VudCI6eyJuYW1lIjoiZWxhZG1pbi13ZWIiLCJ1aWQiOiJmYWY0NzI2My1hZDhmLTRlYjAtYjVmNC0wM2Y2ZDc5MTQ3NTkifX0sIm5iZiI6MTY4MjA1NjQ4Niwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Onl1Y2hhbzplbGFkbWluLXdlYiJ9.mZpxD54dJ2KulGMPmjEh50Blc9OvCxwO0QKc2aiOEvKJjHrVOBtImHJTdMi6LGndl4VDJRnJyOm7cCTuUR4ekGhgCMIxi0qr7QLx5F62_e72YZZBaaUgQ-g9D_8flX7FxEmARqyS6LRWE0GlQ0DNmRjBKO_2LTtW2bCudOQPT_Ggis5t7Szt57rTZQeaR_cJVfdgPpZBXrWVy5je_k1QXQKyVgBrux_Lda61gFj-HhDjgJx5iyIIGFtED5r-38nD_2qwckbNtz2Fzh500ax9bVXPhAfkRZOEK1AtxFHesjKPdK2klPHj1eHl6Px5ZIgHZTdMpv4Q0TCquJpJpl24uA
# 访问metrics-server,例如查看pod指标
# 1. 通过api-server的形式
[root@k8s-master ~]#kubectl -n yuchao get po yuchao-ngx -v=7
I0421 13:56:01.158045 83448 loader.go:372] Config loaded from file: /root/.kube/config
I0421 13:56:01.163562 83448 round_trippers.go:463] GET https://10.0.0.80:6443/api/v1/namespaces/yuchao/pods/yuchao-ngx
I0421 13:56:01.163577 83448 round_trippers.go:469] Request Headers:
I0421 13:56:01.163583 83448 round_trippers.go:473] User-Agent: kubectl/v1.24.4 (linux/amd64) kubernetes/95ee5ab
I0421 13:56:01.163587 83448 round_trippers.go:473] Accept: application/json;as=Table;v=v1;g=meta.k8s.io,application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json
I0421 13:56:01.168039 83448 round_trippers.go:574] Response Status: 200 OK in 4 milliseconds
NAME READY STATUS RESTARTS AGE
yuchao-ngx 1/1 Running 4 (38h ago) 14d
[root@k8s-master ~]#
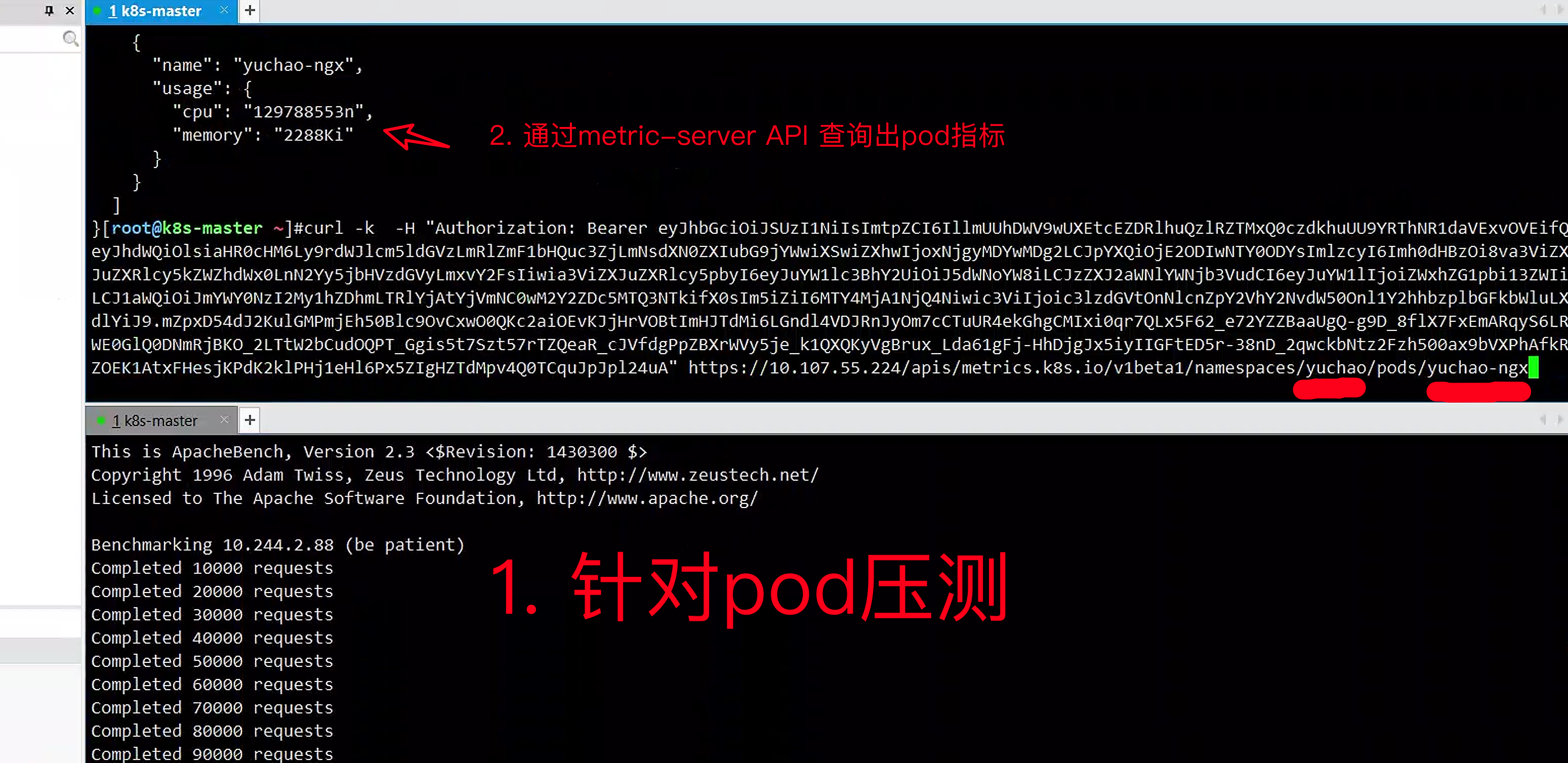
# 2.通过metrics-server的形式
[root@k8s-master ~]#curl -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6IllmUUhDWV9wUXEtcEZDRlhuQzlRZTMxQ0czdkhuUU9YRThNR1daVExvOVEifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjgyMDYwMDg2LCJpYXQiOjE2ODIwNTY0ODYsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJ5dWNoYW8iLCJzZXJ2aWNlYWNjb3VudCI6eyJuYW1lIjoiZWxhZG1pbi13ZWIiLCJ1aWQiOiJmYWY0NzI2My1hZDhmLTRlYjAtYjVmNC0wM2Y2ZDc5MTQ3NTkifX0sIm5iZiI6MTY4MjA1NjQ4Niwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Onl1Y2hhbzplbGFkbWluLXdlYiJ9.mZpxD54dJ2KulGMPmjEh50Blc9OvCxwO0QKc2aiOEvKJjHrVOBtImHJTdMi6LGndl4VDJRnJyOm7cCTuUR4ekGhgCMIxi0qr7QLx5F62_e72YZZBaaUgQ-g9D_8flX7FxEmARqyS6LRWE0GlQ0DNmRjBKO_2LTtW2bCudOQPT_Ggis5t7Szt57rTZQeaR_cJVfdgPpZBXrWVy5je_k1QXQKyVgBrux_Lda61gFj-HhDjgJx5iyIIGFtED5r-38nD_2qwckbNtz2Fzh500ax9bVXPhAfkRZOEK1AtxFHesjKPdK2klPHj1eHl6Px5ZIgHZTdMpv4Q0TCquJpJpl24uA" https://10.107.55.224/apis/metrics.k8s.io/v1beta1/namespaces/yuchao/pods/yuchao-ngx
{
"kind": "PodMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "yuchao-ngx",
"namespace": "yuchao",
"creationTimestamp": "2023-04-21T14:11:37Z",
"labels": {
"run": "yuchao-ngx"
}
},
"timestamp": "2023-04-21T14:11:19Z",
"window": "13.596s",
"containers": [
{
"name": "yuchao-ngx",
"usage": {
"cpu": "0",
"memory": "1920Ki"
}
}
]
}
很明显,数据直接从metric-server也可以直接拿到pod的指标
对比API
metrics-server
https://10.107.55.224/apis/metrics.k8s.io/v1beta1/namespaces/yuchao/pods/yuchao-ngx
api-server
https://10.0.0.80:6443/apis/metrics.k8s.io/v1beta1/namespaces/yuchao/pods/yuchao-ngx
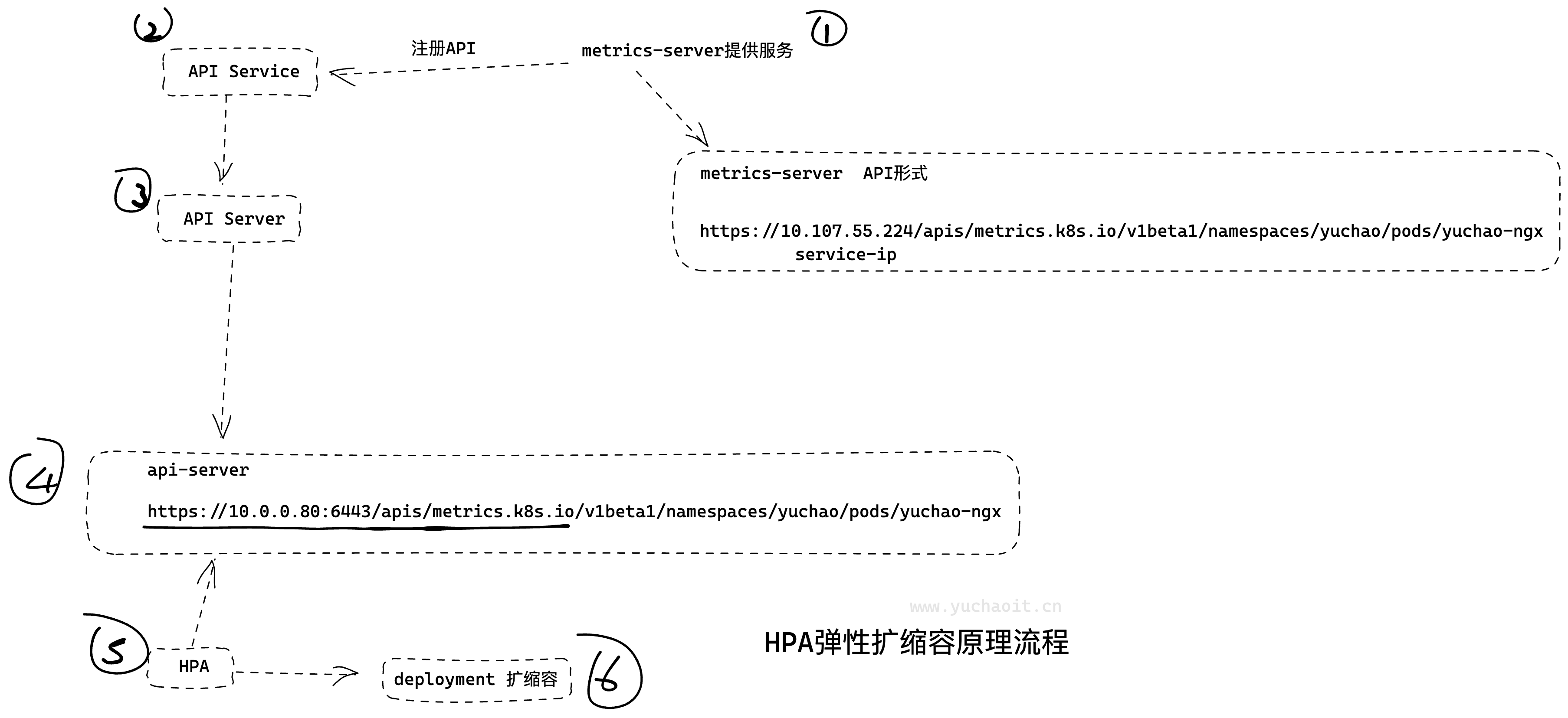
各组件解释
apiservices.apiregistration.k8s.io 、hpa 、metrics-server、kube-apiserver-k8s-master的关联
- apiservices.apiregistration.k8s.io:是Kubernetes中的一种资源类型,它定义了Kubernetes API服务器所提供的API服务的信息。它指定了API服务的名称、组、版本以及它们所暴露的REST端点等信息。
- kube-apiserver-k8s-master:是Kubernetes的API服务器组件,它提供了Kubernetes API的入口。它负责处理API请求并管理Kubernetes中的各种资源。它还可以根据apiservices中定义的API服务信息自动配置API路由和负载均衡。
- metrics-server:是Kubernetes中用于收集集群各种资源的监控指标的组件。它可以提供集群各种资源的实时监控数据,如CPU和内存使用率等。
- hpa(Horizontal Pod Autoscaler):是Kubernetes中的一种控制器,它可以根据集群资源使用情况来自动调整应用程序的副本数。它使用metrics-server收集的监控指标数据来判断是否需要扩展或缩小应用程序的副本数。
因此,这些组件和资源之间的联系和作用可以描述为:
- apiservices指定了API服务的信息,其中包括kube-apiserver-k8s-master提供的API服务的信息。
- kube-apiserver-k8s-master提供了Kubernetes API的入口,可以处理API请求并管理Kubernetes中的各种资源。它还可以根据apiservices中定义的API服务信息自动配置API路由和负载均衡。
- metrics-server负责收集集群各种资源的监控指标,包括CPU和内存使用率等。它提供的实时监控数据可以供hpa控制器使用。
- hpa控制器可以根据metrics-server收集的监控指标数据来自动调整应用程序的副本数,以满足应用程序的资源需求。